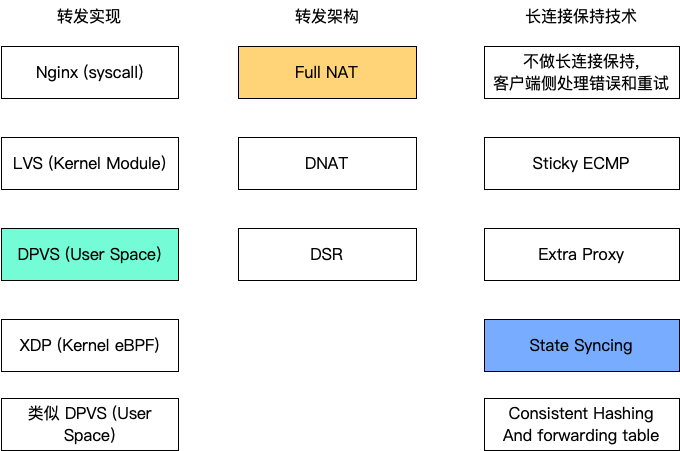
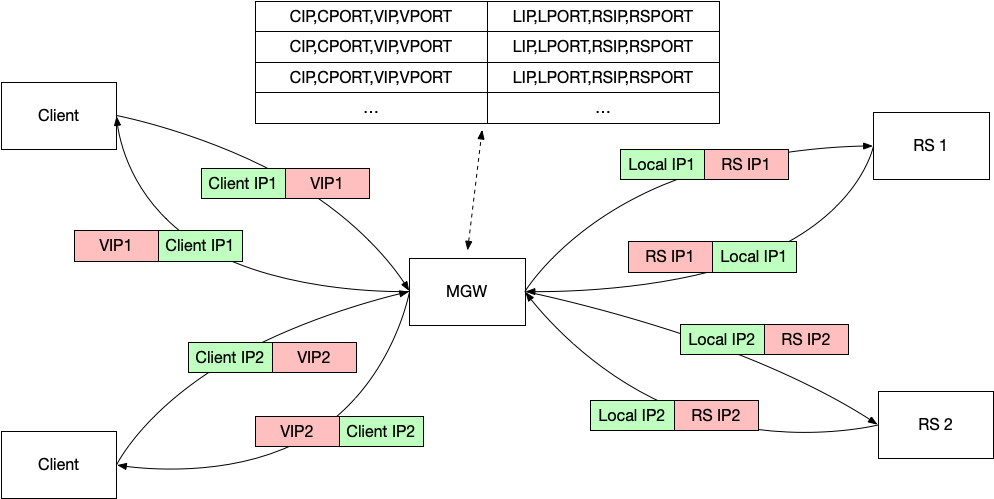
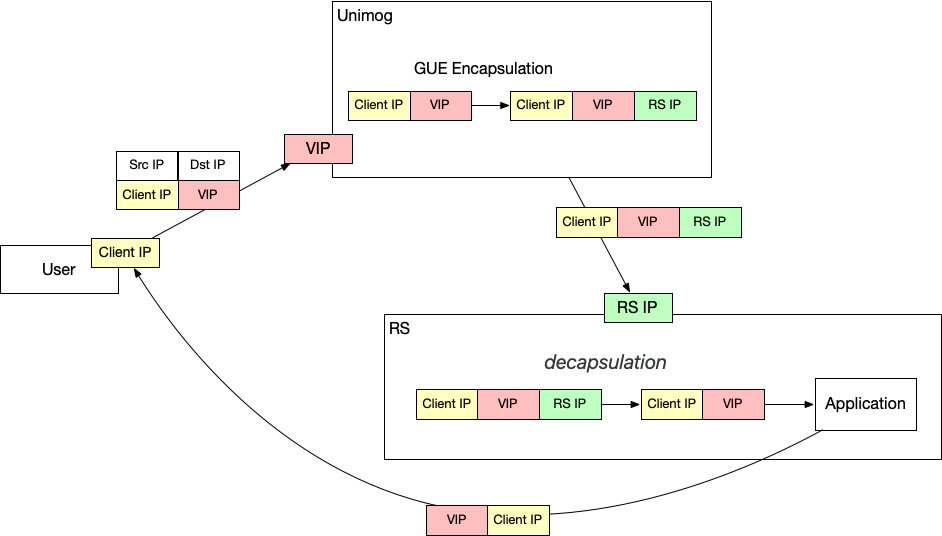
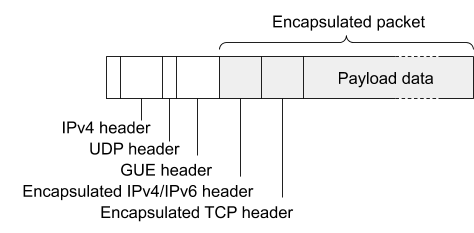
美团的方法是,给每一个 CPU 绑定一个 Local IP,CPU0 使用 local ip0,CPU1使用 local ip1,这样没有数据共享,就不需要加锁了。使用网卡的提供的 flow director,可以做到将 local0 的数据包全都给 cpu0 的队列处理。(如果结合上面提到的浮动路由使用的话,那么每一个 MGW 的 CPU 都需要有一个 Local IP 并且绑定到集群的所有实例中。)
减少上下文切换
就是把跑数据面的进程绑定到固定的 CPU 核心上,然后像 bash,ssh,等其他程序都绑定到其他的核心上。这样,数据面进程永远不会处理中断之类的事情,只会跑重要的数据面进程。
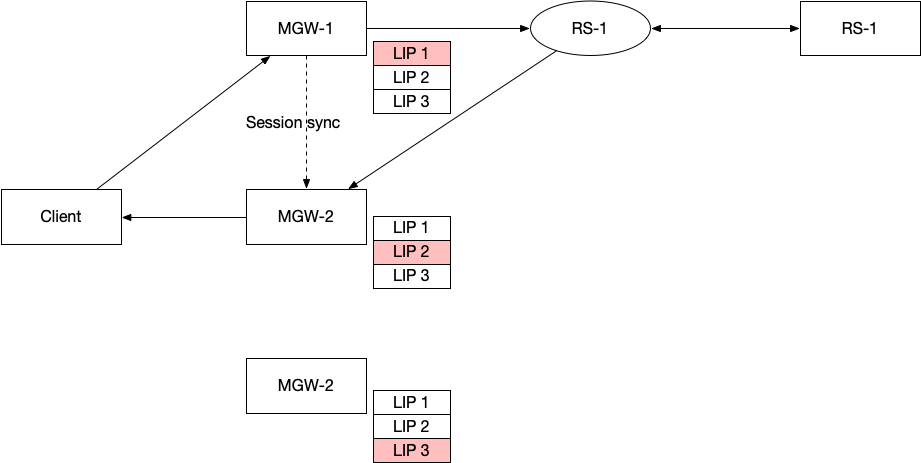
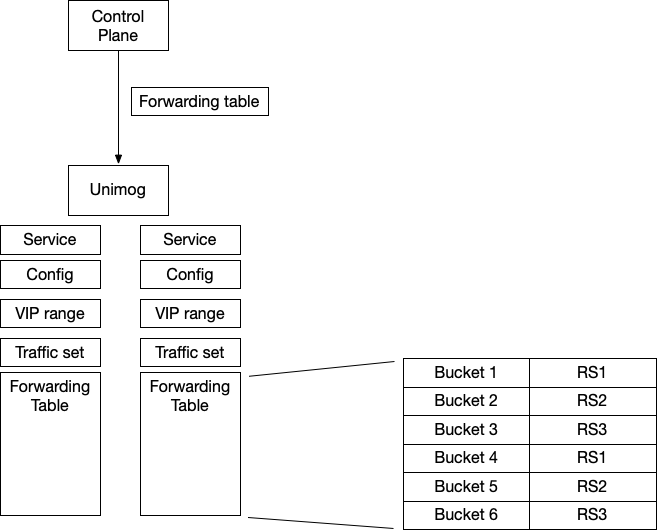
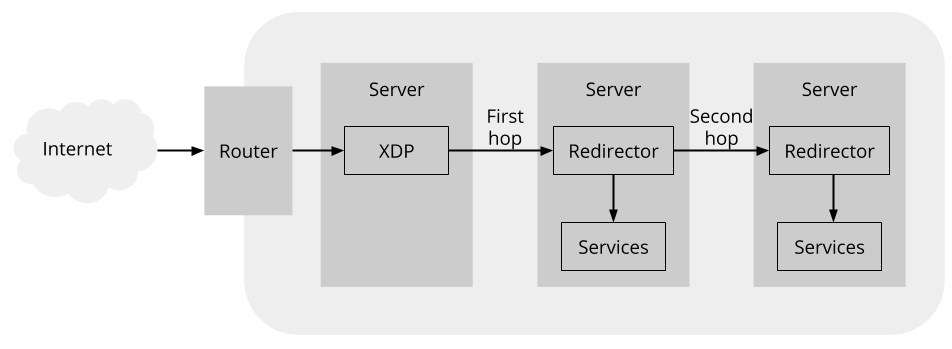
这样也解决了另一个问题,假设 RS A 下线了,那么不需要重新计算整个 forwarding table,只需要将 RS A 对应的 bucket 修改成其他的 RS 好了。只有 hash 到 RS A 的 TCP 连接需要到其他的 RS 上去。
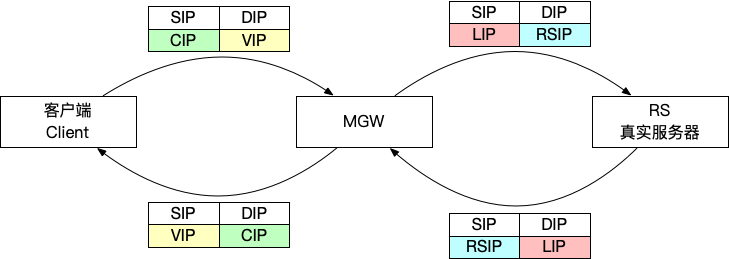
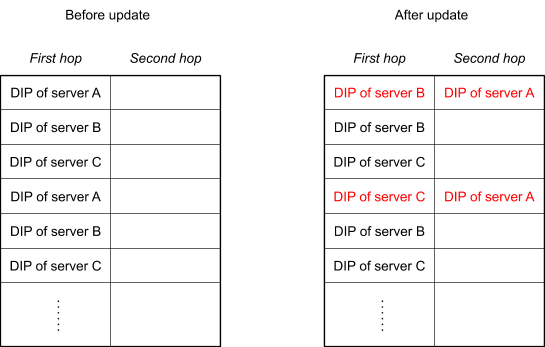
这里还有一个问题:如果 forwarding table 变了,比如 RS A 的 bucket 替换成了 RS B,对于新的 TCP SYN 包,转发到 B 是没有问题的。但是原来连接 A 的,如果到了 B,会被 B 直接拒绝,返回 RST——我不认识你。所以这里要解决一个问题,就是 forwarding table 发生变化的时候,已经存在的连接要保持住,比如原来发送给 A 的,还是需要发送给 A。
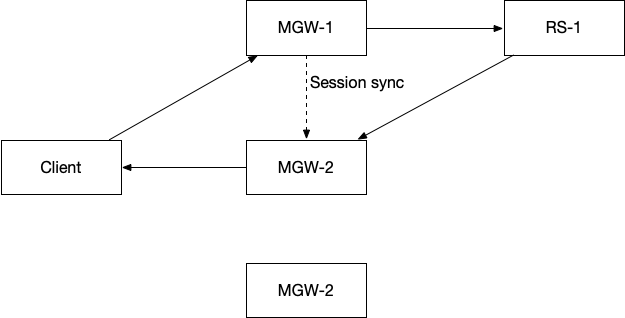
解决方案非常巧妙:forwarding table 中,每一个 bucket 都对应两列 RS,第一列是当前主转发表(First hop),第二列是备份转发表(second hop)。当发生变化的时候,对应的 bucket 主转发表 RS A 变成了 RS B 或者 RS C,备转发表变成 RS A,如下图所示。
一种是 ping-pong 类型,像 DNS,一个包出去,一个包回来,这种可以跳过 2 hop 的维护,一个 hop 必中。
另一个是请求发出去,响应源源不断的回来。这种场景,还是要维护这些包都到同一台 RS 上。可以用和 TCP 一样的方法来处理,但问题是 UDP 没有 SYN 包,怎么来区分出来是否是新建的连接呢?
方案是这样的,我们还是像 TCP 一样维护 2 hop 的表:
第一个 hop 的 Server 收到之后,检查当前机器是否有对应 4 元组的连接(是的,UDP 虽然是「无连接的」,但是你在 Linux 用 ss 工具来查看,也是能看到 UDP 的「连接的」,实现上也有 socket 和连接的概念);
如果没有,直接转发给第二个 hop。
于是现在 UDP 的新连接几乎都去第二个 hop 了。和 TCP 相反。
所以 Conductor 在添加 Server 的时候,如果想要它接收 TCP 流量,应该放到 first hop,如果想让它接收 UDP 流量,应该放到 second hop。(这个地方我感觉很奇怪,之前的描述,第二 hop,即备份表,应该是即将下线的 Server 正在 drain connection,这时候作为 UDP 不是反而开始接收流量了嘛?虽然问题不大,但是不如让 UDP 永远尝试 second hop 先,如果找不到再去 first hop,好像更好,可以保持行为一致。我的这个想法带来的另一个问题是,在实现上讲,这里先去第二个 hop,再去第一个 hop,从网络层面更加违反直觉。评论l2dy指出。)
小李首先想到:既然同一条网线用在一个网络设备上可以,另一个网络设备上却不行,那会不会是 MAC 地址的问题?网线另一端的 ISP 只允许电脑的 MAC 地址,如果是路由器的 MAC 地址,就拒绝掉。有一种叫做 Sticky MAC 的端口安全技术,指的是,当交换机的端口第一次发生流量的时候,交换机就记住这个端口的 MAC 地址,从此之后,这个端口就只能允许这个 MAC 来访问。
验证这个想法很简单,小李让宿舍的另一个同学,把他的电脑接在了网线上。结果发现,即使是另一台电脑,也是可以上网的。这说明网线另一端的 ISP 并没有拿 MAC 来做限制。
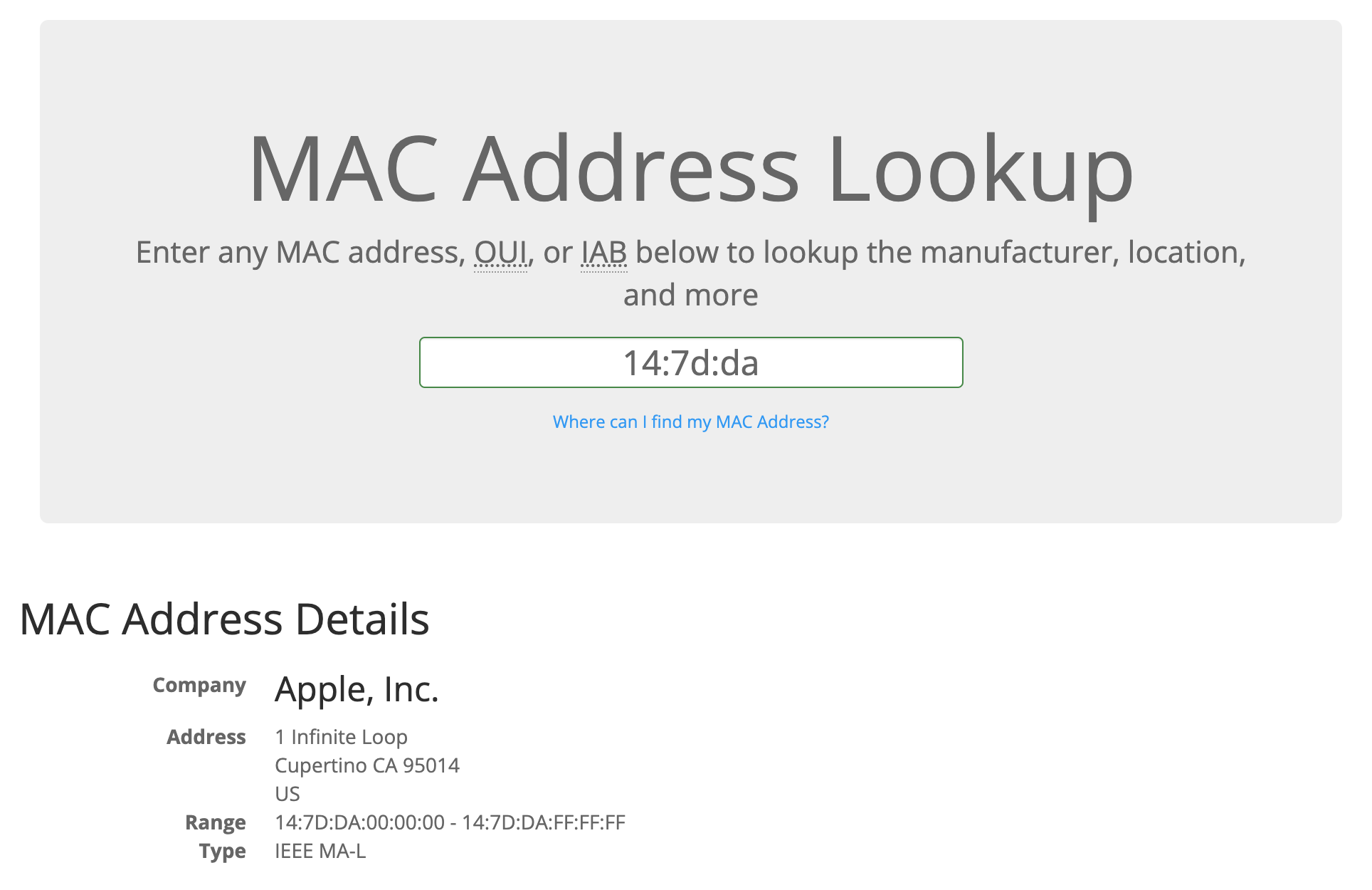
那会不会是通过 MAC 来识别了设备类型呢?MAC 地址的前 24 bit 叫做 OUI,是由 IEEE 分配给不同组织的唯一标志符。我们可以在这个网站查询一个 MAC 地址属于哪一个制造商。
比如谈到 IP 地址,必介绍 IP 分类。然后出个问题考考你:「这个 IP 是 A 类还是 B 类?」后来,工作这么多年从没遇到一个问题需要我判断一个 IP 是几类 IP 的(倒是需要经常判断一个 IP 是不是 Private IP)。因为如今的网络掩码都是可变长度了,Classful network 那是上个世纪的东西了,没有人用这种 IP 分类划分网络了。




{kind=link}