这篇文章写一下服务器的网络方面的调优经验。如果网络的带宽使用在 1GE,其实没有必要做调优,默认的参数基本没有问题;如果有 10G 以上的网络带宽要求,就需要做一些优化了,比如三层网关,四层负载均衡,七层负载均衡,大流量的 Redis 服务器这种场景,在 25GE, 100GE 甚至 400GE 的网卡上,如果不做调优,可能无法跑满带宽。
本文专注于系统参数调优,不涉及代码方面的优化。(当然代码方面的优化也是非常重要的,在高性能网络方面,通过优化代码减少指令数,提高缓存命中率,性能提升也是非常显著的。)
本文提供优化思路,具体的性能差别需要设计实验来得出,虽然我们做了大量的性能测试,但是全贴出来就显得文章太长没有重点,所以实验参数就不贴了。
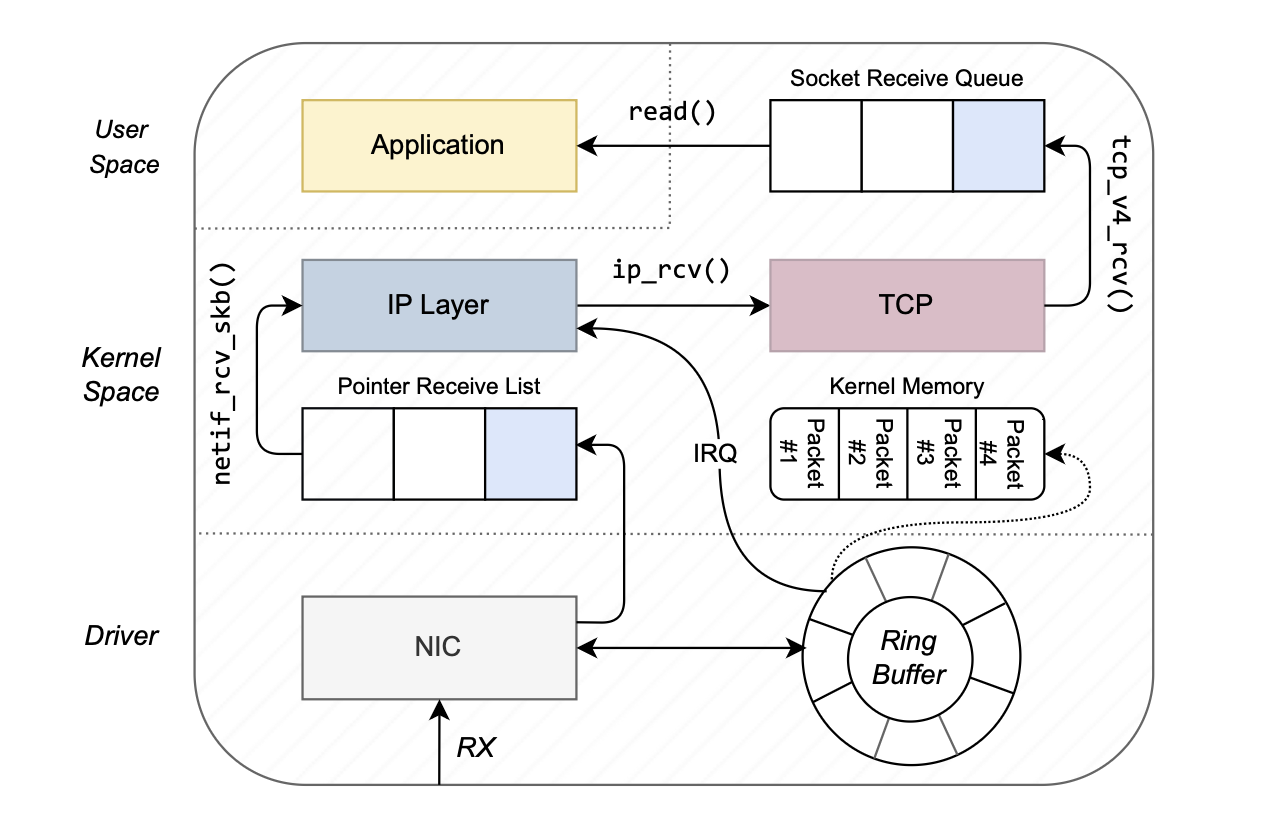
这是一个 TCP 的 ingress 大体的流程图。
来源:The Path of a Packet Through the Linux Kernel Linux 网络栈的收包流程大致上可以分成这么几步:
网卡(NIC)收到包;
NIC DMA 把包写入内存,更新 Ring Buffer;
NIC 发送 interrupt 通知 CPU;
CPU 进入 IRQ handler,调度 NAPI,触发 SoftIRQ;
SoftIRQ 被触发,NAPI poll RX Ring,处理数据包;
进入内核的协议栈处理,数据包最终被用户态的程序通过 socket API 处理。这部分不是这篇文章服务器性能方面关注的重点,所以省略。
我们按照这个路线讨论需要调优的地方。
PCIe
首先,网卡是通过 PCIe 接口插在主板上,如果 PCIe 的带宽小于网卡的带宽,那么在第 1 步就出现瓶颈了。
可以用以下命令检查 PCIe 的实际带宽。
先找到网卡所在的 PCIe 地址:
$ ethtool - i eth2
driver : mlx5_core
version : 24.04 - 0.7.0
firmware - version : 26.43.2026 ( MT_0000000531 )
expansion - rom - version :
bus - info : 0000 : 31 : 00.0
supports - statistics : yes
supports - test : yes
supports - eeprom - access : no
supports - register - dump : no
supports - priv - flags : yes
然后用 lspci 查看这个地址的信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
$ lspci - vv - s 0000 : 31 : 00.0
31 : 00.0 Ethernet controller : Mellanox Technologies MT2894 Family [ ConnectX - 6 Lx ]
Subsystem : Mellanox Technologies MT2894 Family [ ConnectX - 6 Lx ]
Physical Slot : 5
Control : I / O - Mem + BusMaster + SpecCycle - MemWINV - VGASnoop - ParErr + Stepping - SERR + FastB2B - DisINTx +
Status : Cap + 66MHz - UDF - FastB2B - ParErr - DEVSEL = fast > TAbort - < TAbort - < MAbort - > SERR - < PERR - INTx -
Latency : 0 , Cache Line Size : 32 bytes
Interrupt : pin A routed to IRQ 18
NUMA node : 0
Region 0 : Memory at 202ffc000000 ( 64 - bit , prefetchable ) [ size = 32M ]
Expansion ROM at b0e00000 [ disabled ] [ size = 1M ]
Capabilities : [ 60 ] Express ( v2 ) Endpoint , MSI 00
DevCap : MaxPayload 512 bytes , PhantFunc 0 , Latency L0s unlimited , L1 unlimited
ExtTag + AttnBtn - AttnInd - PwrInd - RBE + FLReset + SlotPowerLimit 75W
DevCtl : CorrErr + NonFatalErr + FatalErr + UnsupReq -
RlxdOrd + ExtTag + PhantFunc - AuxPwr - NoSnoop + FLReset -
MaxPayload 512 bytes , MaxReadReq 4096 bytes
DevSta : CorrErr + NonFatalErr - FatalErr - UnsupReq + AuxPwr - TransPend -
LnkCap : Port #0, Speed 16GT/s, Width x8, ASPM not supported
ClockPM - Surprise - LLActRep - BwNot - ASPMOptComp +
LnkCtl : ASPM Disabled ; RCB 64 bytes , Disabled - CommClk +
ExtSynch - ClockPM - AutWidDis - BWInt - AutBWInt -
LnkSta : Speed 16GT / s , Width x8
TrErr - Train - SlotClk + DLActive - BWMgmt - ABWMgmt -
DevCap2 : Completion Timeout : Range ABC , TimeoutDis + NROPrPrP - LTR -
10BitTagComp + 10BitTagReq - OBFF Not Supported , ExtFmt - EETLPPrefix -
EmergencyPowerReduction Not Supported , EmergencyPowerReductionInit -
FRS - TPHComp - ExtTPHComp -
AtomicOpsCap : 32bit - 64bit - 128bitCAS -
DevCtl2 : Completion Timeout : 260ms to 900ms , TimeoutDis - LTR - 10BitTagReq - OBFF Disabled ,
AtomicOpsCtl : ReqEn +
LnkCap2 : Supported Link Speeds : 2.5 - 16GT / s , Crosslink - Retimer + 2Retimers + DRS -
LnkCtl2 : Target Link Speed : 16GT / s , EnterCompliance - SpeedDis -
Transmit Margin : Normal Operating Range , EnterModifiedCompliance - ComplianceSOS -
Compliance Preset / De - emphasis : - 6dB de - emphasis , 0dB preshoot
LnkSta2 : Current De - emphasis Level : - 6dB , EqualizationComplete + EqualizationPhase1 +
EqualizationPhase2 + EqualizationPhase3 + LinkEqualizationRequest -
Retimer - 2Retimers - CrosslinkRes : unsupported
. . .
关键信息是第 23 行显示 LnkSta: Speed 16GT/s, Width x8。
16 GT/s 是 PCIe 的单通道的速度,表示 Giga Transfers per second,PCIe Lane 每秒传输多少个符号(symbol),PCIe Gen 4 每 130 bit 有 2 bit 的编码开销,所以实际带宽是:
128b / 130b Encoding * 16G ≈ 15.754 Gbps
一共有 8 lane,15.754 Gbps * 8 = 126 Gbps.
上面的这张网卡是 25GE,所以 PCIe 的带宽是绰绰有余了。如果是 200 GE 的网卡,就必须插在 PCIe Gen 4 x 16 或者 PCIe Gen 5 x 8 以上才行了。
PCIe 物理插口的宽度
这里需要格外注意的一点是,我这张网卡虽然是 25GE,但是上面是有 2 个 25GE 的接口的,做了 bonding1
可以用 ethtool 查看在用网卡的实际 PCI bus 地址,都是 31:00,说明是同一个 bus,同一个 device。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
$ ethtool - i eth2
driver : mlx5_core
version : 24.04 - 0.7.0
firmware - version : 26.43.2026 ( MT_0000000531 )
expansion - rom - version :
bus - info : 0000 : 31 : 00.0
supports - statistics : yes
supports - test : yes
supports - eeprom - access : no
supports - register - dump : no
supports - priv - flags : yes
$ ethtool - i eth3
driver : mlx5_core
version : 24.04 - 0.7.0
firmware - version : 26.43.2026 ( MT_0000000531 )
expansion - rom - version :
bus - info : 0000 : 31 : 00.1
supports - statistics : yes
supports - test : yes
supports - eeprom - access : no
supports - register - dump : no
supports - priv - flags : yes
我们再来看第 2 步,网卡把数据包的信息 DMA 到内存。
内存
现代网卡得益于 DMA 机制,在网卡收到包到写入内存的时候完全不需要 CPU 参与工作。
——其实这也是一个优化的基本思路,CPU 本身就不适合处理单一的、大批量的任务,应该尽量减少 CPU 的工作。
IOMMU
Linux 里面每一个进程都有一个虚拟的,独立的内存空间,CPU 读取内存的时候,需要 MMU 把虚拟地址转换成物理内存地址。
PCIe 设备直接 DMA 内存也是一样,不过用的是是 IOMMU。简单来说,设备 DMA 的路径如下:
NIC -> IOVA -> IOMMU Page Table -> Physical Address
IOMMU 在这里负责将设备访问的 I/O 地址(IOVA)转换为物理地址,并限制设备只能访问被授权的内存。但是这里也有一层虚拟地址到物理地址的映射,会带来 overhead。
如果关闭,就可以节省这层 overhead,让设备直接写物理内存。但是这样会带来风险——如果网卡存在 bug,就可以写到其他内存地址,是比较危险的。
也可以使用 pass though 模式,让 IOMMU 使用直通模式运行,这样也没有每次内存写入的翻译成本,但是对内存有保护。配置方式是 GRUB 的启动命令添加 intel_iommu=on iommu=pt. 在 pt 模式下,设备通过 IOMMU 的开销很小,而且只能访问特定范围的内存,不能越界。
Page Pool
如果每次 DMA 的时候都申请内存,会有不小的开销。所以比较好的方式是事先规划好一部分内存,这部分内存就不回收了,直接给网卡 DMA 用。
这个功能不需要配置,但是需要网卡驱动和 kernel 支持。
可以通过 debugfs 查看实际网卡有没有使用 page pool:cat /sys/kernel/debug/page_pool/1-0x00000000abcd1234/stats。
(如果没有,也不一定就是每次分配内存,可能用了别的内存优化机制)
NUMA
网卡把包写入哪一块内存也有说法。到这里就不得不说一下现代服务器的架构。
现代的服务器一般是双路服务器,里面有 2 颗 CPU,也叫双子星服务器。注意,这里说的是 2 颗 CPU,2 Socket,而不是双核 CPU。
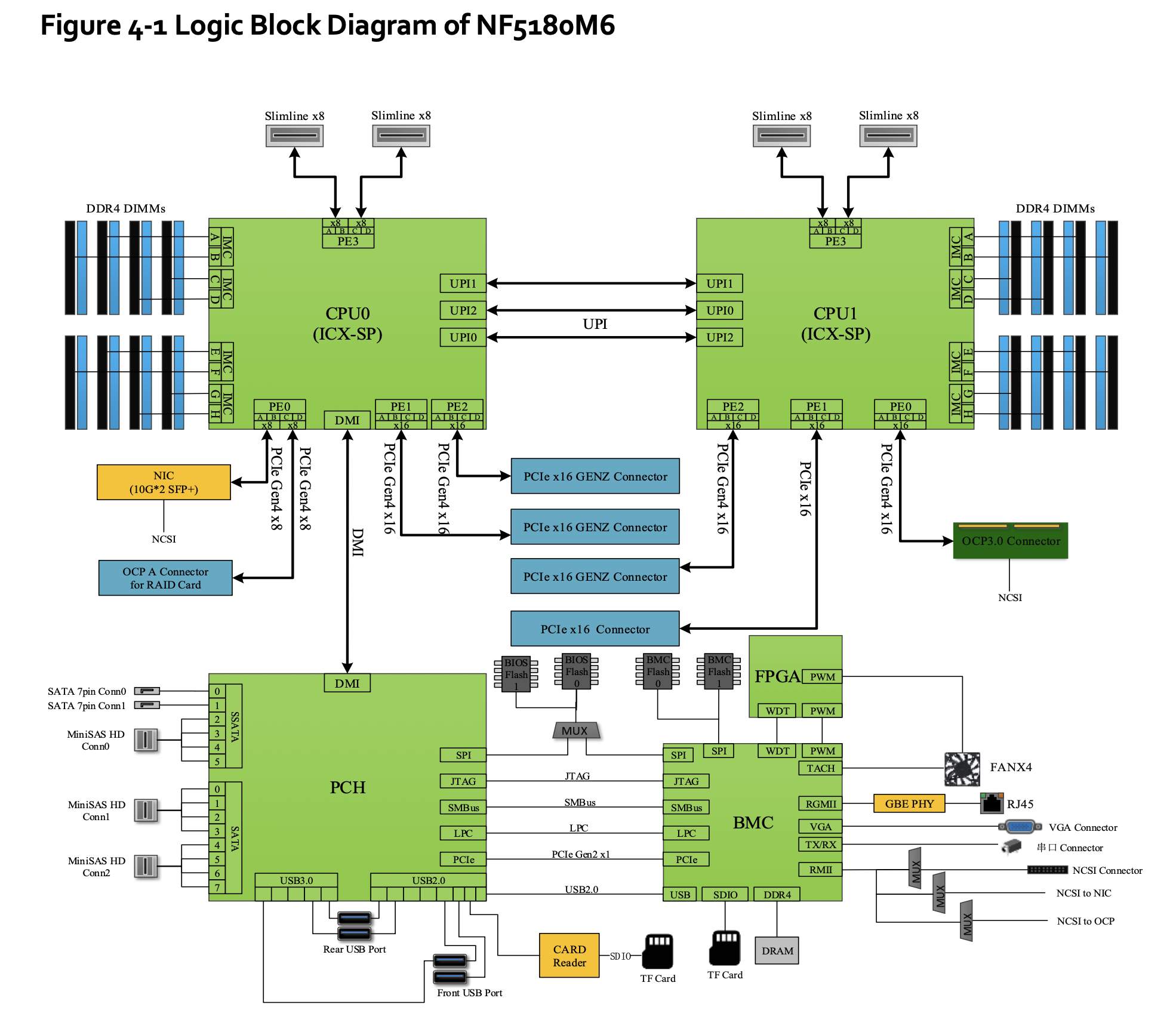
下面是浪潮 NF5180M6 服务器的物理俯视图:
图中有2个 CPU
厂商一般会提供服务器的手册2
NF5180M6 服务器的逻辑图
图中的一个重要信息是:内存也是由两部分组成,一半连接 cpu0,另一半连接 cpu1. 这意味着,物理上 cpu0 访问左边的内存比较快,如果要访问右边的内存,就要走 UPI 去另一个 CPU,比较慢。对于 cpu1 来说反之。
用 numactl 可以看到内存布局:
$ numactl - H
available : 2 nodes ( 0 - 1 )
node 0 cpus : 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62
node 0 size : 128069 MB
node 0 free : 119511 MB
node 1 cpus : 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49 51 53 55 57 59 61 63
node 1 size : 128965 MB
node 1 free : 115027 MB
node distances :
node 0 1
0 : 10 21
1 : 21 10
NUMA 的意思是 Non-Uniform Memory Access,意思是 CPU 访问不同的内存,速度是不一样的。从上面的输出中可以得知,逻辑的 CPU 0,2,4,6…62 号访问 node 0 的内存较快,访问 node 1 的内存较慢,CPU 1,3,5…63 号访问 node 1 的内存较快,访问 node 0 的内存较慢。
这就启发我们,所有内存访问,都应该尽量走 local,避免走 remote:
网卡应该 DMA 到 local node 的内存;
应该让 local node 的 CPU 来处理数据包;
用户态程序应该绑定到 local node 的 CPU 执行;
这样性能才是最优的。
从逻辑图可以看出,一个 PCI 设备只连接到一个 CPU。我们可以用 sysfs 来查看这个 PCI 设备连接的 CPU 所在的 NUMA 节点:
$ cat / sys / class / net / eth2 / device / numa _ node
0
注意:这个文件的信息本质上是 ACPI 提供的,数据来源于硬件的上报,但是有些不守规矩的厂商可能没有上报正确的数据。最准确的信息其实是上面厂商提供的逻辑图 。3
即 eth2 这个网卡是连接到 node 0 上的。那么网卡驱动在初始化的时候,应该从 node 0 申请内存,这样,后续的 DMA 都使用 node 0 的内存。这部分一般不需要调试,驱动的内存初始化一般都是 NUMA aware 的。
网卡 DMA 到内存之后,接着是 CPU 的 softirq 来处理这个包,我们希望 node 0 的 CPU 来处理,而不是 node 1 的 CPU 来处理。
首先,找到中断号。(这里,我们以其中一个 queue 1 为例,多 queue 我们后面继续讨论)
cat / proc / interrupts | grep mlx5_comp1 @
115 : 0 0 998453167 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 IR - PCI - MSI 30932994 - edge mlx5_comp1 @ pci : 0000 : 3b : 00.0
180 : 0 0 43 892854366 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 IR - PCI - MSI 30935042 - edge mlx5_comp1 @ pci : 0000 : 3b : 00.1
由于这个网卡有 2 个接口,每一个接口都有一个 1 号 queue,所以 grep 出来了 2 个。以第一个为例,它的中断号码是 115 号。我们就可以对 115 中断进行 CPU affinity 绑定:对 /proc/irq/115/smp_affinity_list 写入 2,就表示由 cpu2 来处理这个中断,即 cpu2 来处理网卡 1号 queue 的数据包。
数据包最后会通过 socket API 来给用户程序消费。(如果是 XDP 实现的 L3 或者 L4 网关,就没有这一步了),用户程序尽量放在 node 0 来执行,性能会更高。用户态程序绑定 NUMA 的方式很多,比如可以用 numactl --cpunodebind=0 --membind=0 ./app 来让程序尽量使用 node 0 的 cpu 和内存;或者在程序内部使用 pthread_setaffinity_np() 和 sched_setaffinity() 绑定 CPU。
在 200G/400G 的网卡上,内存带宽依然可能成为瓶颈,可以用 pcm-memory 和 perf 来检查瓶颈是否在内存。
说到了 CPU,我们接下来继续聊一聊 CPU 有关的优化。
CPU
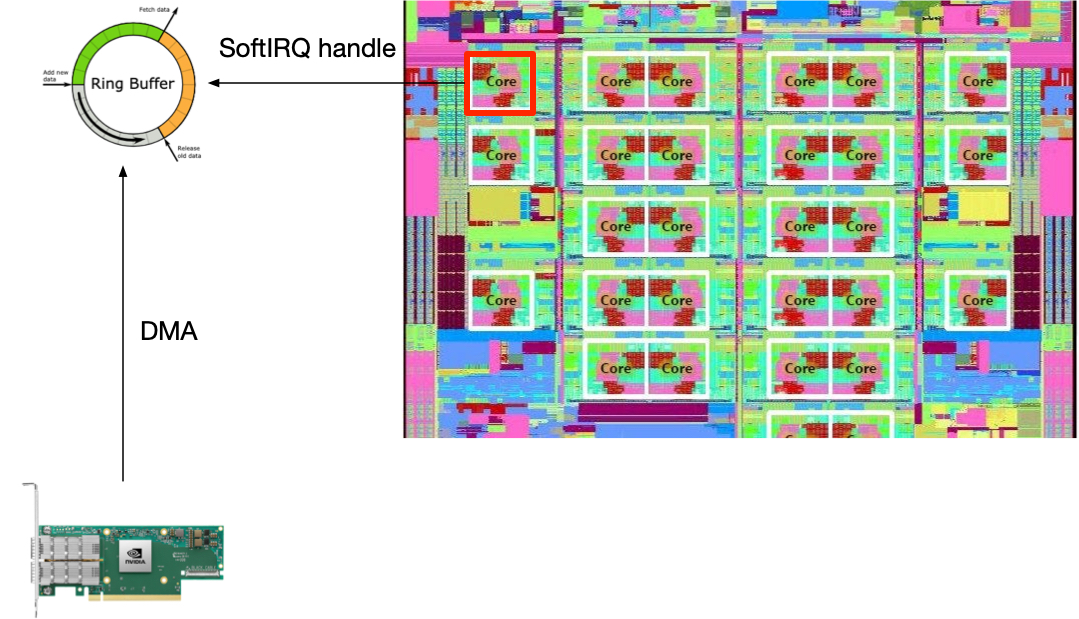
首先是网卡 queue 的数量。有一次我们发现服务器的带宽使用上不去,流量一高就会有丢包。一个 CPU 的使用率 100%,其他的 CPU 空闲。这是一个比较常见的问题,原因是网卡只开了一个 queue。网卡把所有收到的包都 DMA 到这个 queue 的 ring buffer,所以只有一个 CPU 来处理这个 ring buffer 的包。一个 CPU 是无法处理 10GE 的网卡带来的流量的。
这种情况就如下图所示:
Single NIC Queue
解决的办法就是让更多的 CPU 来干活。
但是我们不能让更多的 CPU 来处理这个 queue 的数据,原因是:
我们不希望多个 CPU 之间有竞争关系,竞争条件意味着效率下降;
我们不希望让一个 flow 的包走多个 CPU,这样会造成乱序4
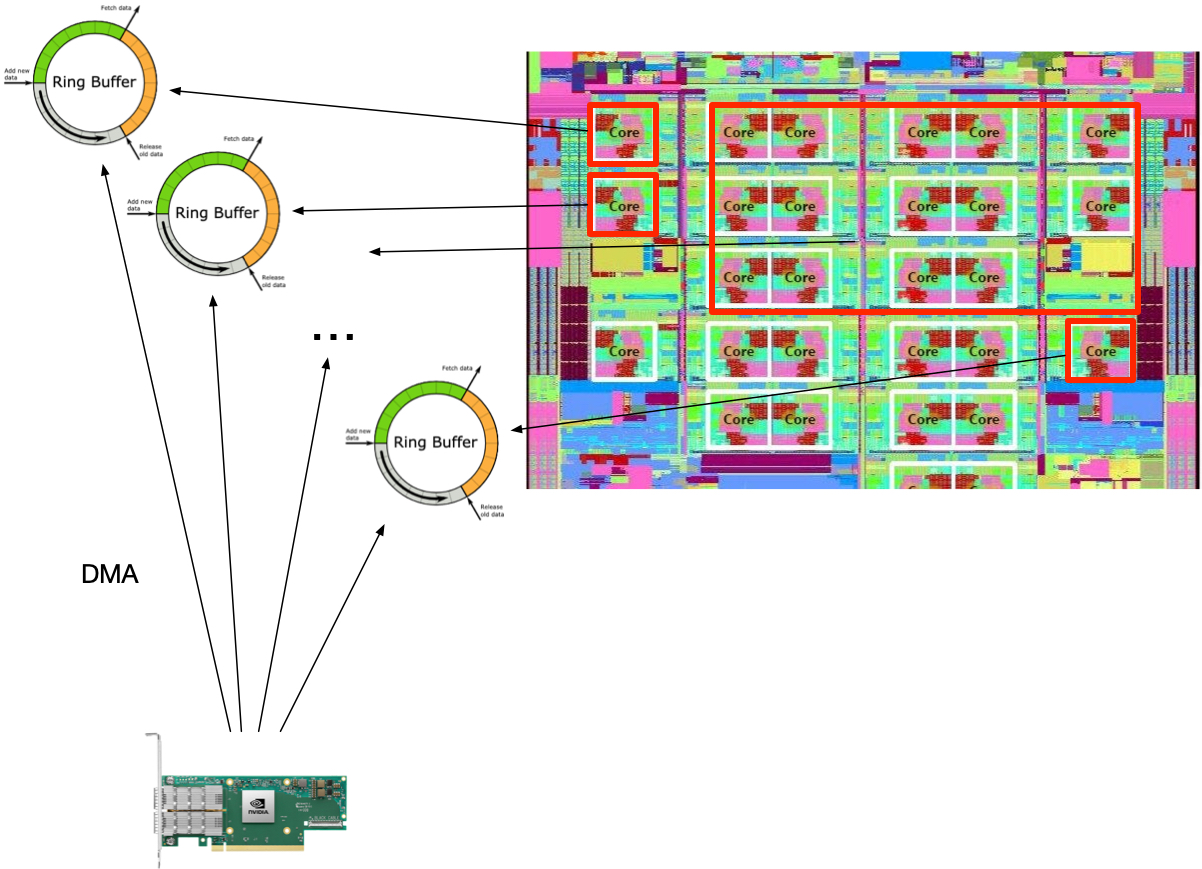
那就只能开更多的 queue,每一个 cpu 处理一个 queue。
这样,我们就需要网卡支持把收到的流量放到多个 queue,但是依然要保持 flow -> queue hash 的一致性。这个功能叫做 RSS,Receive Side Scaling,是在网卡里实现的。虽然 CPU 也支持对收到的包分流(RPS/XPS),但是这个工作也要在一个 CPU 上执行,而且太慢了,一般不用。
RSS
开多个 queue
开多个 queue 很简单,可以通过 ethtool -l eth2 查看当前 queue 的数量。
通过 ethtool -L eth2 combined 8 修改 queue 的数量为 8。
Queue 的数量越多越好吗?也不是,我们的目标是尽可能利用多的 CPU,如果 queue 的数量超过了 CPU 的数量其实也没有意义。
CPU 数量和 Queue 的数量
以下面我这台机器为例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
$ lscpu
Architecture : x86_64
CPU op - mode ( s ) : 32 - bit , 64 - bit
Address sizes : 46 bits physical , 48 bits virtual
Byte Order : Little Endian
CPU ( s ) : 64
On - line CPU ( s ) list : 0 - 63
Vendor ID : GenuineIntel
BIOS Vendor ID : Intel
Model name : Intel ( R ) Xeon ( R ) Silver 4216 CPU @ 2.10GHz
BIOS Model name : Intel ( R ) Xeon ( R ) Silver 4216 CPU @ 2.10GHz CPU @ 2.1GHz
BIOS CPU family : 179
CPU family : 6
Model : 85
Thread ( s ) per core : 2
Core ( s ) per socket : 16
Socket ( s ) : 2
Stepping : 7
Frequency boost : disabled
CPU ( s ) scaling MHz : 100 %
CPU max MHz : 2101.0000
CPU min MHz : 800.0000
BogoMIPS : 4200.00
Flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr
sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good
nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 s
sse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsa
ve avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_pp
in ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase ts
c_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushop
t clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cq
m_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req pku ospke
avx512_vnni md_clear flush_l1d arch_capabilities
Virtualization features :
Virtualization : VT - x
Caches ( sum of all ) :
L1d : 1 MiB ( 32 instances )
L1i : 1 MiB ( 32 instances )
L2 : 32 MiB ( 32 instances )
L3 : 44 MiB ( 2 instances )
NUMA :
NUMA node ( s ) : 2
NUMA node0 CPU ( s ) : 0 , 2 , 4 , 6 , 8 , 10 , 12 , 14 , 16 , 18 , 20 , 22 , 24 , 26 , 28 , 30 , 32 , 34 , 36 , 38 , 40 , 42 , 44 , 46 , 48 , 50 , 52 , 54 , 56 , 58 , 60 , 62
NUMA node1 CPU ( s ) : 1 , 3 , 5 , 7 , 9 , 11 , 13 , 15 , 17 , 19 , 21 , 23 , 25 , 27 , 29 , 31 , 33 , 35 , 37 , 39 , 41 , 43 , 45 , 47 , 49 , 51 , 53 , 55 , 57 , 59 , 61 , 63
在 node0 显示有 32 个 CPU,那么应该开 32 个 queue 绑定到这些 CPU 吗?
这就错了,其实最优的方案是用 16 个 CPU。因为 Thread(s) per core: 2,即这是一个 Hyper-Threading 的 CPU,每一个物理 core 有 2 个 thread。
如果看下 CPU 的分布,会发现 cpu0 和 cpu 32 是同一个物理 core,2 和 34 是同一个,以此类推。实际每一个 socket 只有 16 个物理 core,算上超线程才是 32 个 core。
# lscpu -e
CPU NODE SOCKET CORE L1d : L1i : L2 : L3 ONLINE MAXMHZ MINMHZ MHZ
0 0 0 0 0 : 0 : 0 : 0 yes 2101.0000 800.0000 2100.0000
. . .
2 0 0 2 7 : 7 : 7 : 0 yes 2101.0000 800.0000 2100.0000
. . .
32 0 0 0 0 : 0 : 0 : 0 yes 2101.0000 800.0000 2099.9990
. . .
34 0 0 2 7 : 7 : 7 : 0 yes 2101.0000 800.0000 2099.9990
0 和 32,2 和 34,它们的 node, socket, core 都是一模一样。CPU 的计算单元是 share 的。做网络处理,我们的瓶颈不在等待内存,而是在 cpu 的计算。超线程并不会增加 cpu 的计算能力。(不要被 Intel 骗了!)
相反,如果使用了这些 cpu,反而会造成 cache 命中率下降,网络处理极度依赖 cache 提前把下一个要处理的包 load 进来,cache 命中率下降意味着吞吐大幅度下降。
所以我对 IRQ 绑核的时候,只绑 2 个超线程核心中的一个。
或者在 GRUB 启动的时候添加 nosmt,这样超线程的功能直接被关闭了,系统启动之后只能看到物理 core。这样比开启 SMT 但是我们只用超线程中的一个逻辑 CPU 而言,会节省 5% 左右的 SMT 上下文管理成本。
话说,如果只使用 numa node0 的 CPU,那 node1 的 CPU 不是都浪费了吗?是的。
如果要低延迟的网络,推荐只用网卡的 PCIe 所在的 node 的 cpu。但是如果要更多的带宽处理能力,可以多开 16 个 queue,绑定到 node 1 的 cpu。这里是带宽和延迟的 trade off,在网络调优方面,很多地方都都是在对吞吐(带宽)和延迟做取舍。
包到 CPU 的全路径
网卡收到包之后,会先通过包的 5元组 得到一个 hash 值,然后根据 RETA(Redirection Table)选择一个 queue。
通过 ethtool -x 可以查看 RETA:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# ethtool -x enp59s0f0np0
RX flow hash indirection table for enp59s0f0np0 with 16 RX ring ( s ) :
0 : 1 2 3 4 5 6 7 8
8 : 9 10 11 12 13 14 15 1
16 : 2 3 4 5 6 7 8 9
24 : 10 11 12 13 14 15 1 2
32 : 3 4 5 6 7 8 9 10
40 : 11 12 13 14 15 1 2 3
48 : 4 5 6 7 8 9 10 11
56 : 12 13 14 15 1 2 3 4
64 : 5 6 7 8 9 10 11 12
72 : 13 14 15 1 2 3 4 5
80 : 6 7 8 9 10 11 12 13
88 : 14 15 1 2 3 4 5 6
96 : 7 8 9 10 11 12 13 14
104 : 15 1 2 3 4 5 6 7
112 : 8 9 10 11 12 13 14 15
120 : 1 2 3 4 5 6 7 8
128 : 9 10 11 12 13 14 15 1
136 : 2 3 4 5 6 7 8 9
144 : 10 11 12 13 14 15 1 2
152 : 3 4 5 6 7 8 9 10
160 : 11 12 13 14 15 1 2 3
168 : 4 5 6 7 8 9 10 11
176 : 12 13 14 15 1 2 3 4
184 : 5 6 7 8 9 10 11 12
192 : 13 14 15 1 2 3 4 5
200 : 6 7 8 9 10 11 12 13
208 : 14 15 1 2 3 4 5 6
216 : 7 8 9 10 11 12 13 14
224 : 15 1 2 3 4 5 6 7
232 : 8 9 10 11 12 13 14 15
240 : 1 2 3 4 5 6 7 8
248 : 9 10 11 12 13 14 15 1
RSS hash key :
21 : 9a : d6 : 8d : f0 : 54 : bb : c4 : 6c : 5a : b6 : d2 : 2f : b4 : 01 : f1 : 51 : c1 : d0 : 79 : 7d : cb : 7b : 02 : ee : c9 : 63 : 78 : 75 : 2a : 51 : cf : af : 69 : 3d : d3 : fb : 6a : c6 : 1e
RSS hash function :
toeplitz : on
xor : off
crc32 : off
可以看出 hash 的方法是 toeplitz,一个有 255 个 bucket。举例来说,如果 hash 的 value 是 9,那么选择的 queue 就是第 2 行的第 2 个,即 10 号 queue。
RETA 也可以通过 ethtool -X eth2 equal 16 (平均分到 16 个 queue)指定。
可以发现,即使 ethtool -l 显示有 32 个 queue,也不是说实际使用的就是 32,如果我们在 RETA 里面平均分配到 16 个 queue 的话,实际只有 16 个 queue 会有流量 (IRQ)。
选中一个 queue 之后,NIC 会 DMA 到这个 queue 对应的内存。接下来我们要绑定这个 queue 对应的 CPU。
通过上面提到过的 /proc/interrupts 文件,可以查看这个 queue 对应的中断号。然后通过 /proc/irq/115/smp_affinity_list 来绑定 cpu 号。要对所有使用的 queue 都进行 cpu 绑定。同时,要注意只绑定物理 core,不要让一个物理 core 去处理多个 irq。
我用 Intel,博通,和 Mellanox 的网卡的 RSS 都没有遇到问题,RPS/XPS 可以关闭了。这个功能可以理解是 Linux 软件实现的 RSS,ingress 和 egress 方向。我们已经设置了 RSS,就不希望内核代码再次调度 cpu,造成 cache miss。
关闭 RPS 很简单,把每个 RX Queue 的 rps_cpus 设置为 0 即可。
for f in / sys / class / net / eth0 / queues / rx - * / rps_cpus ; do
echo "$f: $(cat $f)"
done
Ring Buffer Size
开启了多个 queue,每一个 queue 都有一个 ringbuffer,这个 buffer 的大小可以用 ethtool -g eth0 来查看。也可以用 ethtool 来调整。
这个值其实不会提升性能,因为它不影响处理速度。但是把它增大可以提升稳定性,在流量突增的时候,有更多 buffer 空间,可以减少丢包。
但是 buffer 越大就越好吗?肯定不是。
首先大的 buffer 会带来延迟。比如在 10Gbps 下,buffer 是 8196,如果 buffer 满了,流量稳定 10Gbps,那么每一个包进来之后都要在 buffer 中排队约 8196 才能被处理,latency 高达几 ms。如果 buffer 只有 512,那么徒增流量会直接被丢弃,但是每一个被处理的包都只有不到 1ms 的延迟。
另外,512 的 ringbuffer 很小,所有的 descriptor 都可以放到 CPU 的 L1 cache 里面,大大提高处理速度。
这是稳定性与延迟之间的 trade off。
隔离 CPU
为了让用户程序不占用处理 irq 的 CPU,造成延迟不稳定,我们可以让用户程序只在特定的 CPU 执行,跑 irq 的 CPU 不跑用户程序。
方式可以是通过 taskset 设置每一个程序的 CPU 绑定,也可以在 GRUB 设置启动参数,内核参数添加 isolcpus=0-19,这样普通程序默认就不使用 0-19 CPU 了。
这样做对一些管理程序也有好处。比如 LACP,ARP,SSH 不进入隔离的 CPU,即使网卡流量打满了,SSH 依然可以工作。(当然,更稳的方式是用带外管理)
CPU 频率设定
CPU 有 scaling governor 设置,目的是在 CPU 空闲的时候可以进入低频模式运行来省电,对我们来说性能和稳定性更重要,所以可以改为 performance 模式。
CPU boost 需要管理。临时的性能提升不如稳定的性能,boost 可能会升高温度带来降频。
IRQ 和 NAPI 参数
我们可以设置 softirq 的处理预算,让一次 softirq 处理更多的包。让 CPU 花在更多的时间在处理 softirq 上。
net.core.dev_weight=600 设置一次 NAPI 最多处理 600 个包,默认 64;net.core.netdev_budget=3000 设置一次 softirq 触发最多处理多少个包(与上面的区别是,如果 3 个 queue 对应到一个 cpu,那么这两个的设置是,一次 softirq 触发之后,每一个 queue 最多处理 600 个包,总共处理不超过 3000 个包。)net.core.netdev_budget_usecs=10000 让 softirq 一次最多运行 10ms,默认是 2000;echo 2 > /sys/class/net/<iface>/napi_defer_hard_irqs 设置 NAPI 在连续 2 次空转之后再退出。默认情况下 NAPI poll 到没有包处理就退出了。这个设置让它空转 2 次。本质上也是让 cpu 多花时间在处理网络上;echo 200000 > /sys/class/net/<iface>/gro_flush_timeout 这个让 GRO 等待更多的时间再 flush,这样可以把更多的小包合成一个大包,节省后续网络栈处理的包,提高 PPS。(但是对于 XDP转发 程序来说作用不到,XDP 工作在 driver,在内核的 GRO 前面,不会执行到 GRO)。
Interrupt Coalescing
最后来到了操作系统的 IRQ 处理网络栈。
如果每次来一个包,都触发一次 CPU 中断,这样中断的数量就太多了。
我们可以告诉网卡:收到包之后,先不要中断给 CPU,如果一共攒了 64 个包,或者时间等了 32 usecs,再发送一次中断:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
$ ethtool - c eth2
Coalesce parameters for eth2 :
Adaptive RX : on TX : on
stats - block - usecs : n / a
sample - interval : n / a
pkt - rate - low : n / a
pkt - rate - high : n / a
rx - usecs : 32
rx - frames : 64
rx - usecs - irq : n / a
rx - frames - irq : n / a
tx - usecs : 8
tx - frames : 128
tx - usecs - irq : n / a
tx - frames - irq : n / a
这就是中断合并。
这个值的设置也是 trade-off——如果设置得太大,那么延迟会升高,但是可以节省 CPU 资源,吞吐增加,适合存储类服务;如果设置地太小,延迟就很低,但是资源占用就比较高,适合低延迟网络,如量化交易,游戏等等。
——如果我们让网卡在包比较少的情况下使用低的中断合并,在包多的时候使用高的中断合并,不就完美了吗?
这就是自适应的中断合并功能,在上面的网卡设置中,可以看到 Adaptive RX: on TX: on,网卡就会根据实际的网络流量来自动调节中断合并的参数。
NIC Offload
CPU 的资源很宝贵,所以硬件优化的思路就是尽可能的把工作交给网卡来做,网卡的 ASIC 芯片很适合重复劳动。
比如:
checksum offload – 网卡算好了,CPU 就不需要检查一遍 checksum 了;
TSO/GRO – 网卡把多个包合并成一个大包交给 CPU 处理,同样的 PPS 可以带来更大的带宽;
VLAN offloading;
VXLAN offloading;
…
网卡支持的 offloading 越来越多,根据使用的协议可以看网卡是否支持。
总结
参数调优,首先要明确调优的目标:低延迟优先,高吞吐优先,稳定不丢包优先,还是成本最小(比如省电)优先?所有参数调整都是在做 trade off,不然的话这些参数没道理默认不是最优的。
提高性能的思路无非就是:
节省计算资源,把 CPU 的工作交给其他硬件去做;
了解整个路径,缩短这个路径,比如一些直通的技术,NUMA 使用 local node;
了解整个路径,在路径上做加速,比如加快 IRQ 的处理速度,加快内存的分配速度;
可观测性也很重要,无法观测每一个路径的成本,也就无法优化。所以不要盲目优化,先找到瓶颈在哪里,再去解决瓶颈。