由于工作中经常遇到需要性能分析,所以自己写了一个能在终端看火焰图(后面打算再写篇博客介绍下火焰图以及如何阅读)的小工具:https://github.com/laixintao/flameshow。这篇文章先记录一下,在开发过程中遇到的一些性能问题,以及优化方法。
之所以记录这篇博客,是因为这个问题思考了很久,尝试过很多方法,最后解决的时候,感觉太爽了,跟当前解决了 iredis 那个巨大正则表达式编译速度太慢的问题一样。所以迫不及待地想分享一下。
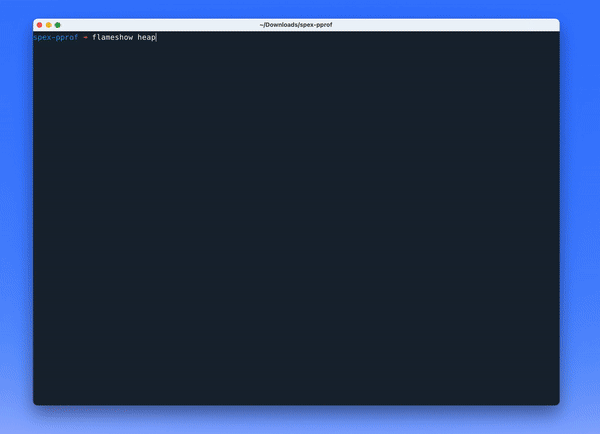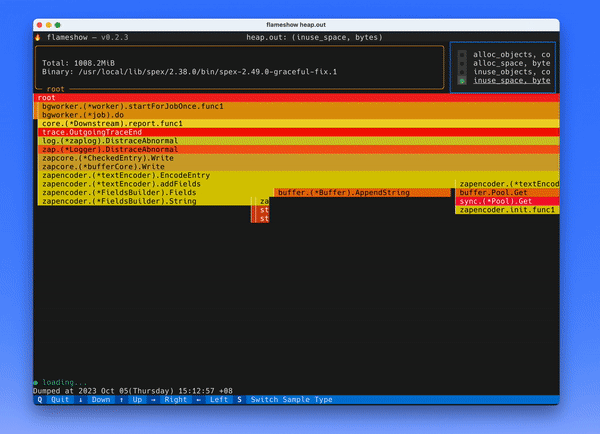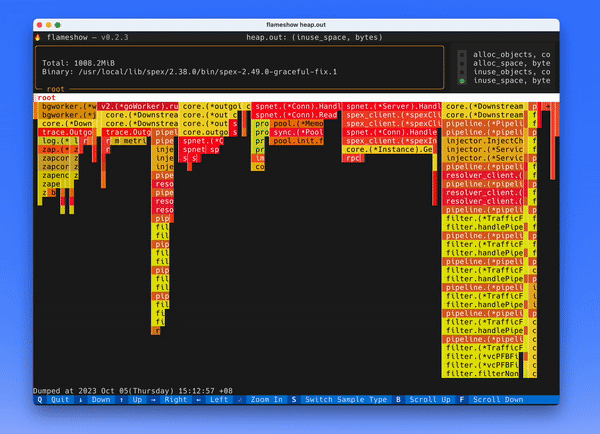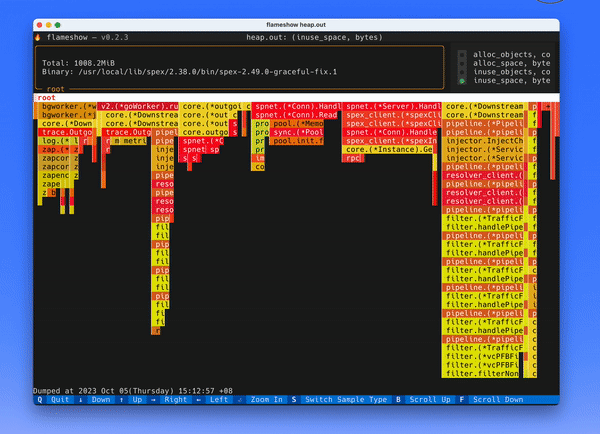
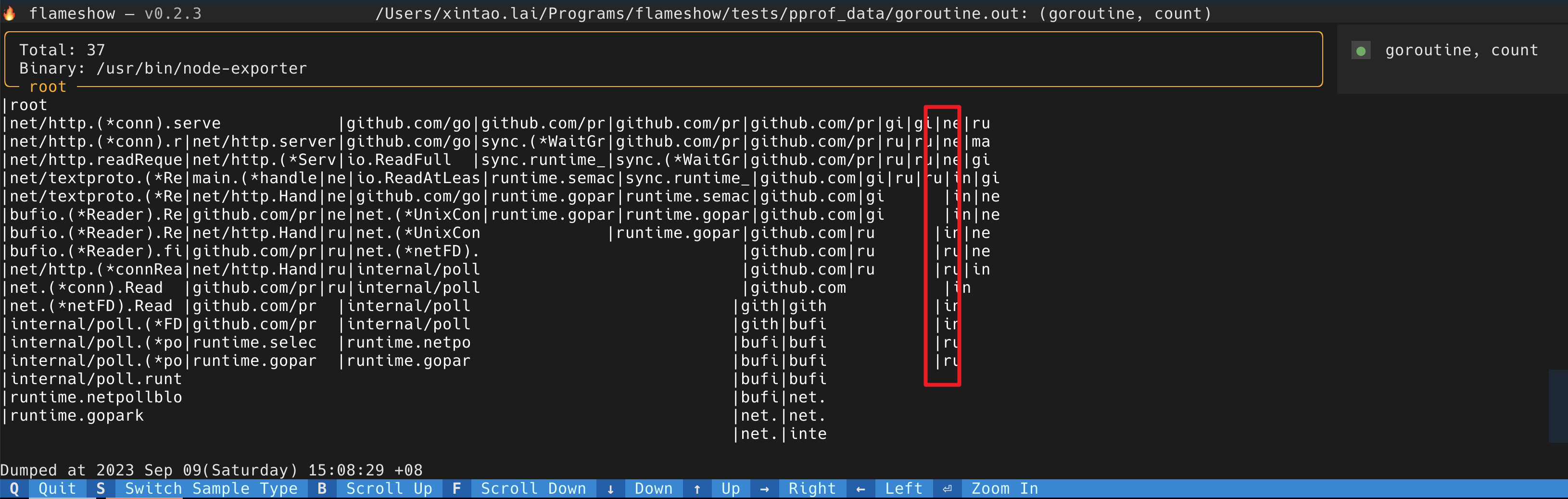
先介绍一下这个项目的背景。这个程序做的事情,本质上就是按照程序在 stack 上花费的时间,渲染出如下一张火焰图,方便快速定位程序都把时间花在了什么地方。
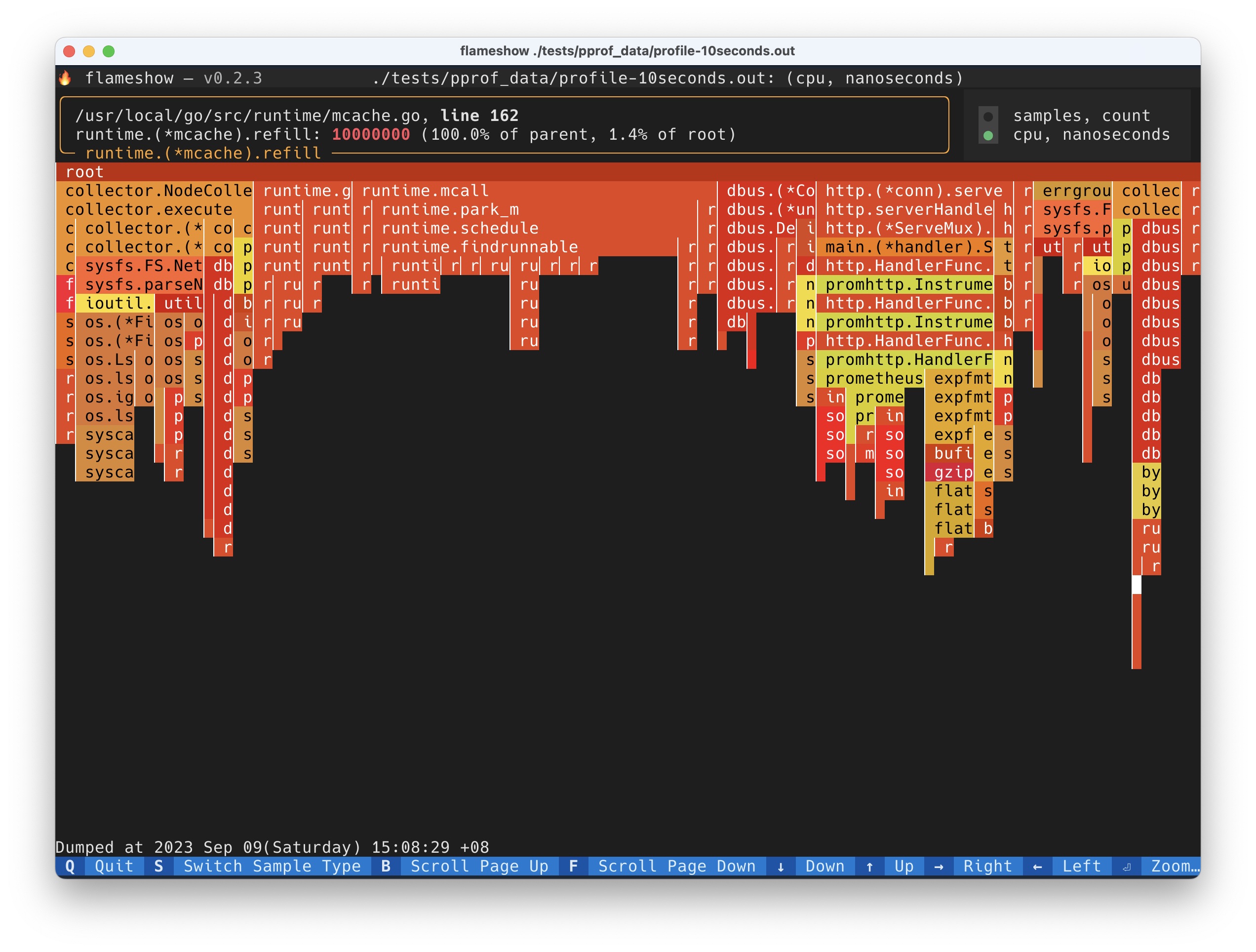
本质上就是将 frame 按照一层一层地渲染出来,如果程序在这个 frame 花费的时间长,就渲染的长度多一些,如果花的时间短,就渲染的长度短一些。
我是用 textual 这个库(很赞的一个库,准备单独写一篇博客来赞美这个库!)来做渲染的,只花了两个小时就写出来了原形。但是速度非常慢,效果如下:
优化之后的效果如下:
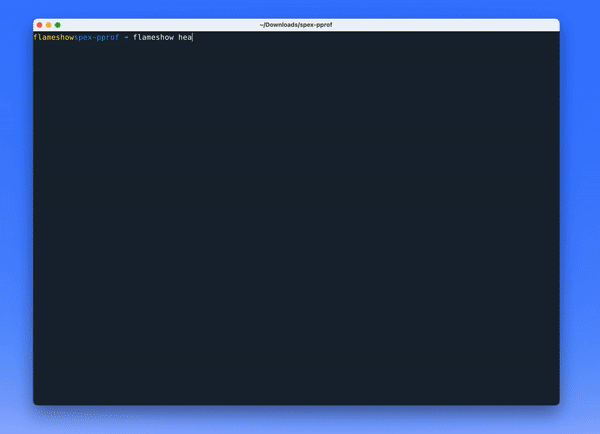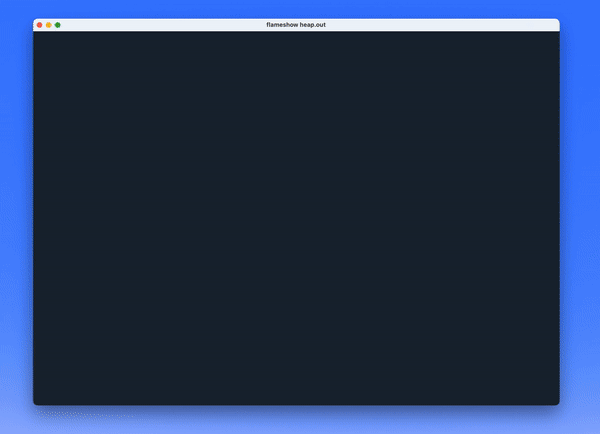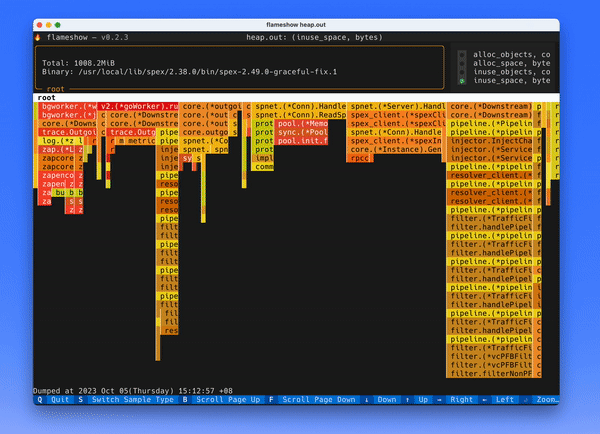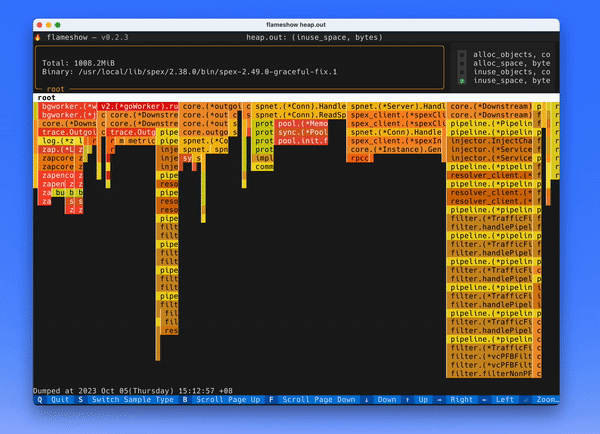
上面的 GIF 都没有经过裁剪,可以看到效果非常明显,原来需要 5s 左右渲染出来,优化之后只需要 100ms 左右。下面就介绍一些优化的方法。
从 Golang 到 Python
目前火焰图渲染支持的格式主要是 Golang 定义的 pprof 的格式,是 golang 定义主要使用的一种格式(其实很多其他语言的工具,导出的格式也是 pprof)。那么解析这种格式,就是需要用 golang。
所以最开始的解析就是通过 Python 代码,再通过 cffi,去调用 golang 生成的 .so 库。
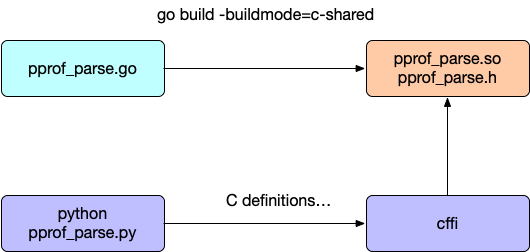
这就有一个问题,使用 golang 解析完成 pprof 文件,通过什么数据格式来传给 Python 呢?这里面还要经过 C,所以得用很基本的数据类型才行。我就选择了 json。
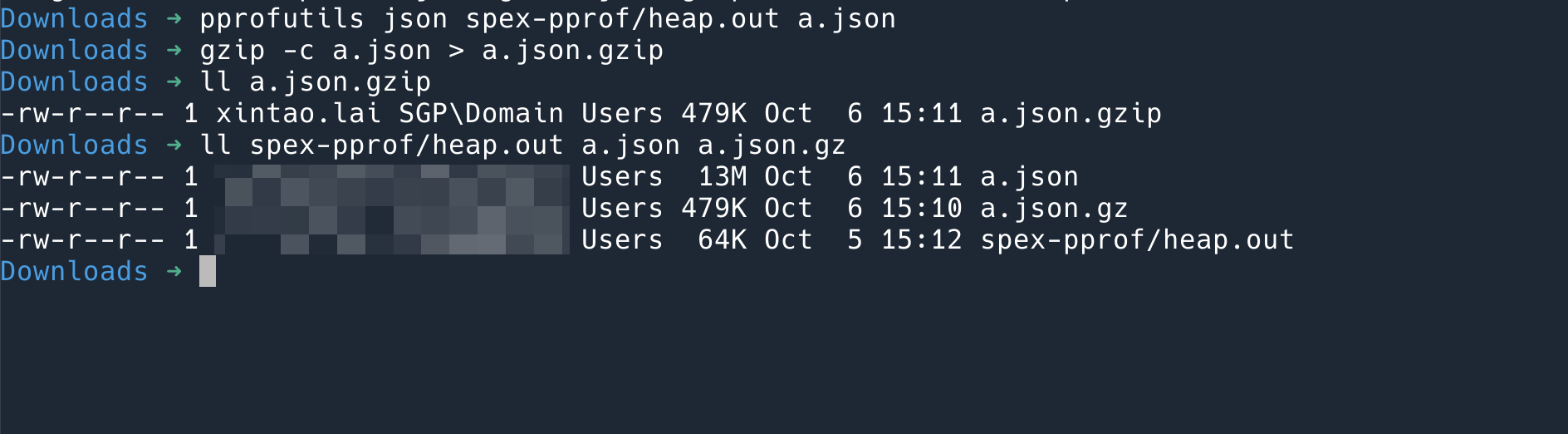
但是这个 Json 非常大,一个原本 64KiB 的 pprof 文件,解析成 json 之后,就变成了 13MiB! 所以在 Python 中反序列化就耗时很久。
跨语言调用还带来一个问题就是安装麻烦,要么我去给每一个平台 build wheel 分发,要么用户安装环境需要有 go 才能编译这个扩展。这个工具定位就是能够直接在服务器上进行性能分析的,所以如果不依赖 go 编译器就好啦!
求助 messense 编译 wheel 的问题是,他建议用 Python 实现一下 pprof 文件的解析(这个主意真好!)。
于是我看了下这部分的 golang 代码,发现也不复杂,,核心逻辑是:
- 如果是 gzip 压缩的文件,就先 uncompress
- 然后通过 protobuf 来做解析
- 做数据恢复
(3)数据恢复步骤很有趣,我发现,pprof 里面有很多 id 引用,比如一个 Function 里有 binary map,line,等各种信息,表达多个 function 的 stack 关系的时候,并不是直接将每一个 function 像 json 那样列出来,而是将所有的 function id 列出,一个是 int 类型的 array。然后有一个 function table,记录了每一个 function 的内容。其中,最精彩的部分是,所有的数据结构都不是 string,然后有一个 string_table 字段记录了所有的 string,这样,整个 pprof 文件中,一个重复的 string 都没有出现。这样,压缩效率非常高。代价就是,我们在解析的时候,读完 protobuf 还要将这些 id 还原回去。
压缩效率有多高呢?
如果直接 pprof 转换成 json,是 13M,用 gzip 压缩之后是479K,但是原本的 pprof 只有 64K。
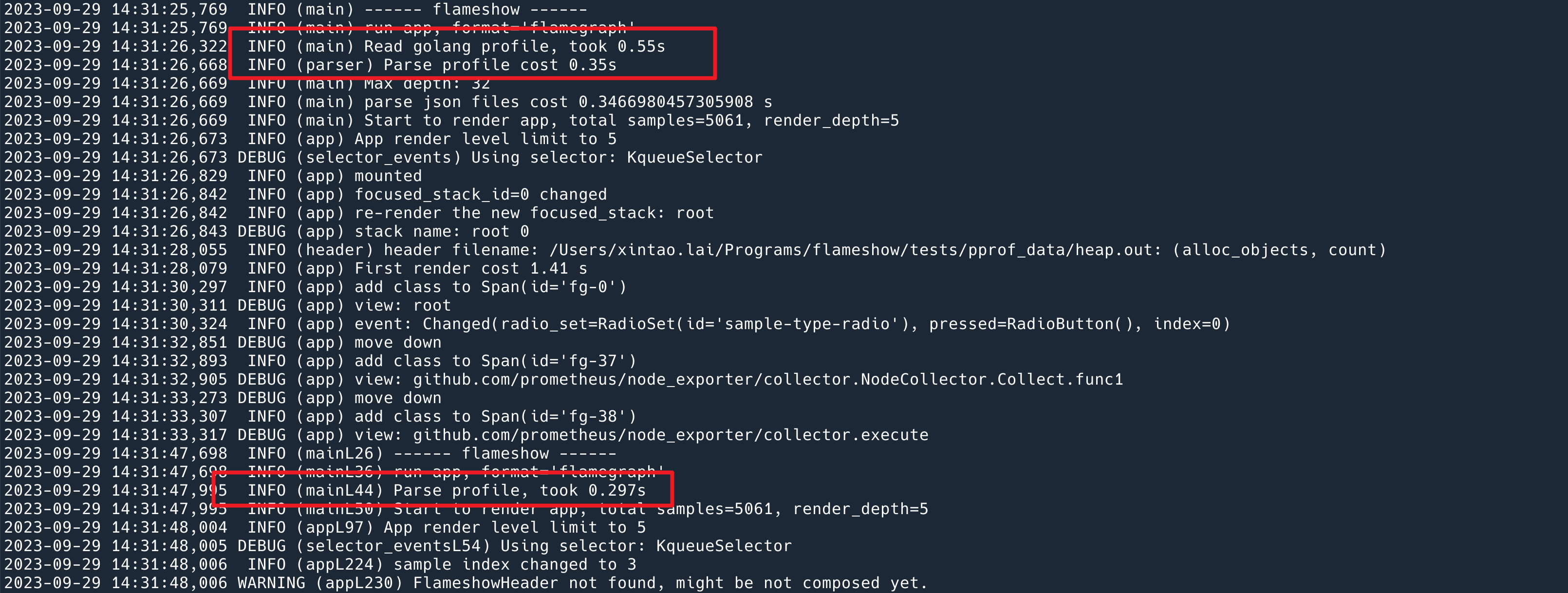
这部分工作做完之后,读取 pprof 的环节加快了 70% 左右。下面的日志是前后版本分别运行,计算的解析 pprof 解析的时间。
渲染部分优化
从上面的 Gif 可以看到,即使数据读取完了,渲染,看到最后的火焰图也经过了不少的时间,看起来就比较 “卡”。
这是因为最开始写的时候,直接用了 textual 的 widget,每一个颜色的 frame 都是一个单独的 widget。
一开始也没有想到为什么这么做会慢。于是用 py-spy perf 了一下(咦,是谁在用火焰图去分析火焰图分析工具?是我!)
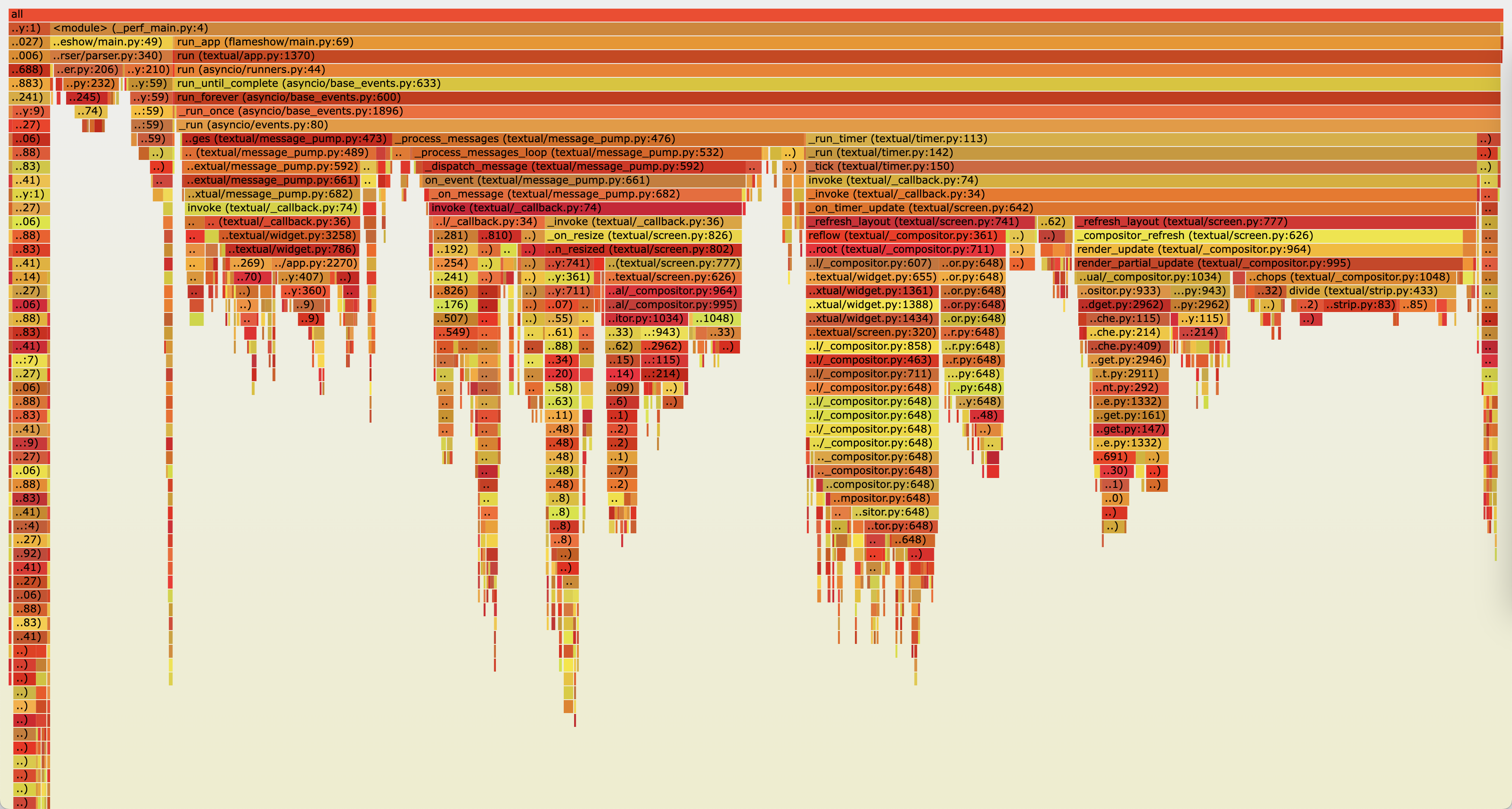
可以看到,主要的时间都在 compositor.py, 并且这个函数也在不断嵌套。
一个想到的办法,就是先通过减少渲染的层级,来节省时间。因为我们看火焰图的时候,注意点在哪一条最长,短的其实不太关心。所以,我做了以下优化:
- 如果 sample 数量超过 N,sample 越多,横向渲染的 span 越少;比如,在 sample 有 3000 多的时候,只渲染最长的 5 条 span 的 children,其他的,只显示一个
+more; - 同理,向下的层级也是越少;
- 如果当前的 Frame 只有一个 child,那么不使用嵌套 widget 的方法,直接在当前的 widget 加一个 Span 堆下去;
- loading 的时候,显示
loading...字样,稍微提高一下用户体验。
渲染一个巨大的 sample 的时候,如下图:
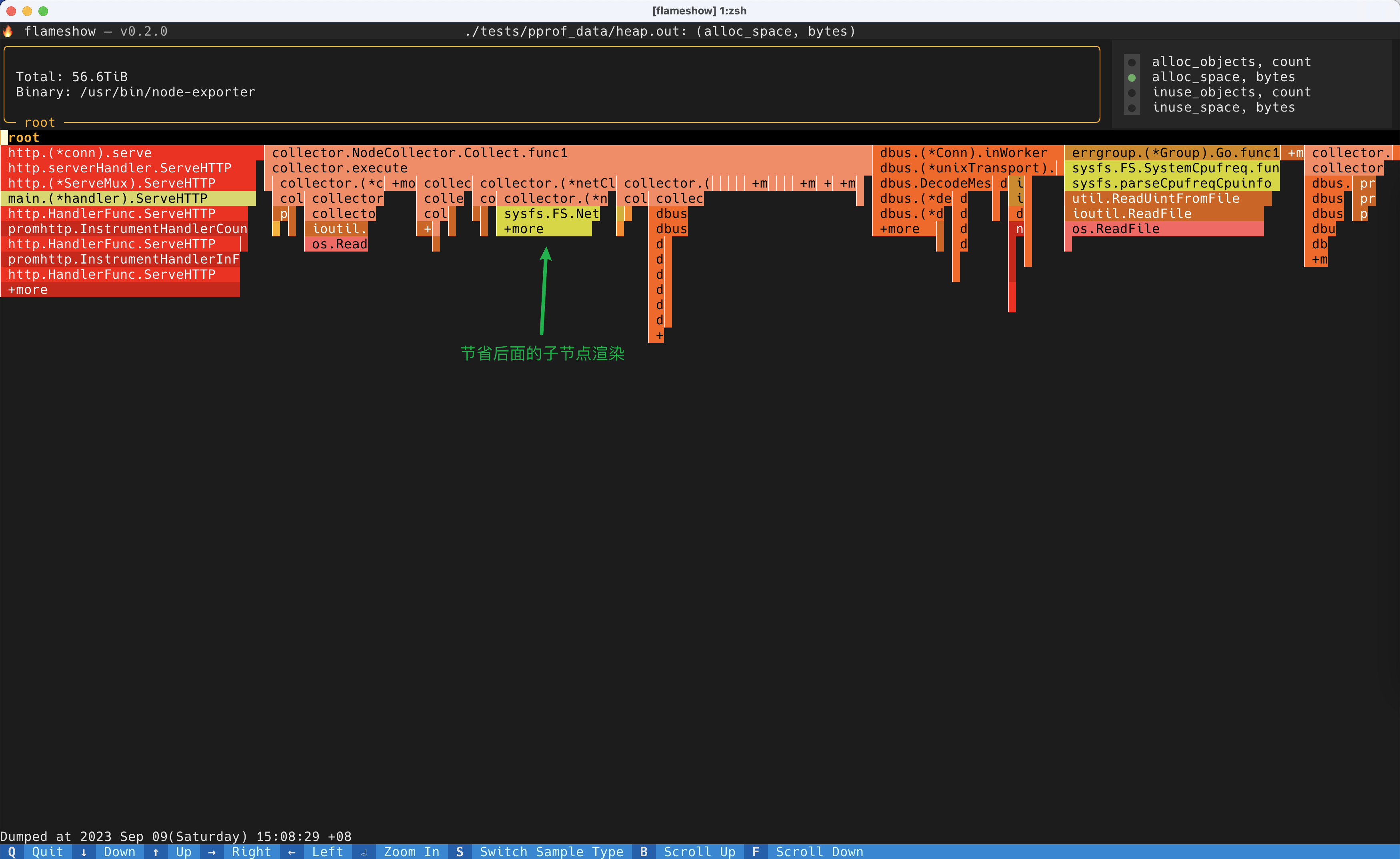
+more 但是还是能看的但是这些都是治标不治本。有一天朋友跟我说:你这个工具都是终端渲染,全都是字符而已,渲染速度应该很快吧?我直接破防了。
通过 Line API 来渲染
最根本的解决办法,就是改变渲染的逻辑,不应该用嵌套(递归好爽,这个工具的 0.1 版本我记得写过五六次递归……),而是直接一行一行 print 出来,这样直觉上应该做到秒开。
textual 正好有这么个 API,可以让你自定义渲染的方式:line API. (要么这么说这个库做的好呢,你需要的人家都想到了。)
API 的格式就是 def render_line(self, line_no: int)。
textual 渲染的时候,就来调用你的这个函数,你返回在 line_no 的内容。
其余的就是大量的重写工作了,因为不是 widget 直接嵌套了,所以很多宽度和偏移的计算要自己做。做完之后,果然可以做到秒开了!
这之间遇到一些奇奇怪怪的问题,比如有一个很有意思的:下面有 3 行,括号内,表示一个 Span 的 offset 和 value。
第一个行的内容是: Root(0, 100)
第二行:Frame1(0, 5.4), Frame2(5.4, 2.4), Frame3(7.8, 92.2)
如果渲染这两行,我们按照他们的 value 比例进行宽度渲染,假设当前屏幕宽度为 100 字符(终端最小单位是字符,无法打印出来 1.4 个字哈,要么是1,要么是2,所以必须将上面的 float 比例转换成 int 的宽度和偏移)。
第一行,直接 100 个字符,很简单。
第二行:
- Frame1 按照 5.4 value,四舍五入,打印 5 个字符;
- Frame2 偏移 5.4,宽度 2.4 四舍五入之后是 offset 5,占用宽度2;
- 那么第三个 frame 就麻烦了,还是按照四舍五入吗?那么就是偏移等于 8,宽度 92;这就出问题了,前面一共宽度是 5+2,Frame3 从偏移 8 开始,就空出来一个。
核心问题是,如果简单的四舍五入,那么原来的 value 总和,并不等于对所有 value 四舍五入之后的总和。
这样就导致…… 渲染出来的纵向不是直的,而是歪歪扭扭的。
这个问题可太有意思了,让我简化一下需求:请实现一个功能:给一个数组,float 类型,把每一个元素都变成 int,要求:
- 前后相同 index 的差值不能超过1
- 并且前后相加总和要想等(float精度问题造成的差值可以忽略,可以假设前后的 sum 都一定是 int)
读者可以想想,你会怎么实现呢?
答案在这里。
关于saferound的问题,自己的方法是这样,先计算累加和列表,然后对累加和列表元素做round,再求diff,得到saferound。没太看明白答案中的difference的策略,不知道是不是一样的。
import random
from itertools import accumulate
origin_target_sum = 100
target_sum = 100
list_len = 5
float_list = []
for i in range(list_len - 1):
x = random.uniform(0, target_sum)
# x = round(x, 4)
float_list.append(x)
target_sum = target_sum - x
float_list.append(target_sum)
print(f"float_list: {float_list}, sum: {sum(float_list)}")
cumulative_sums = list(accumulate(float_list))
rounded_lst = [round(num) for num in cumulative_sums]
safe_round = [rounded_lst[0]] + [
rounded_lst[i] - rounded_lst[i - 1] for i in range(1, len(rounded_lst))
]
print(f"safe_round: {safe_round}, sum: {sum(safe_round)}")
assert sum(safe_round) == origin_target_sum
emmm 回复代码块应该怎么设置? 没有缩进了。
应该可以使用 <code></code> 这个 tag。(wordpress 的评论框,上面的评论给你加了 tag 了)
不太一样,你这方法也可以,相当于循环 round,每一次 round 都将前一个 item 的 diff 给补偿到当前的 item round 里面去,这样最终差值是不变的。
iteround 里面是先计算出来 round,然后判断 sum == original_sum,如果不想等,就补偿一次(支持不同的补偿方案),while 循环一直补偿,直到两个 sum 之间没有差值。
您这种方法,因为本质上可以 2 次循环完成,所以更快。
iteround 的效果会更好,因为是考虑整个 list 补偿,而您的算法只能两两之间补偿。
但是 iteround 性能会差,代码中有 3 次循环,一次排序,还有一次 O(logn) 的循环。
关于最后一个问题,我第一直觉是记住累积误差,并把它加到下一个数上再进行舍入。
用你的例子,
第一段是 5,误差 0.4
误差加到第二个数上变成 2.8,取 3,误差-0.2
加到第三个数上变成 92.0,取 92
感觉应该可行,因为没有任何误差被丢弃
是可行的,跟上面读者 wxzhu 的评论一样。其实我也是这么想的。
但是搜到 iteround 这个库的时候发现它做的更巧妙。比如 5.49, 5.01, 我们会 round 成 5, 6,但是 iteround 会挑选最该补的去补,可以变成 6, 5, 效果好一些。