在运维系统中,我认为 Alert 光发出来是不够的。每一个 Alert 发出来都需要处理,都要被解决。
我们现在设计的监控系统是这样的:
- Vmalert 是 alert rule evaluation 的组件,简单来说,它就是不断查询 TSDB 数据库中的数据,如果发现满足了 alert rule 的条件,就发送请求给 alertmanager;
- Alertmanager 会把 Alert 路由到正确的接受者,如果同一个 alert 被多个实例触发,它还会将他们聚合在一个 alert 中,只发送一条。此外,还有 Mute,高级 alert 抑制低级 alert,判断 alert 是否恢复的条件,等等功能。
- Alert reaction 是我写的一个系统,补充了开源监控系统中缺失的一部分:alert 的处理。这个系统在一次 PromCon 上分享过。Alertmanager 所有的 alert 会同时发送给 Alert reaction 一份,这个系统对于 Alertmanager 来说,就是一个普通的接受者。收到 alert 之后它会在自己的数据库中记录下来。
Alert reaction 系统能够提供的功能有:
- 对于所有触发过的 alert 进行统计,触发频率,应急事件,解决事件,等等,这些统计信息可以帮助我们优化 alert 触发的条件,让 alerting 效率更高;
- 保证所有的 alert 都有人在处理,设计了一个签到机制,alert 必须有人 ACK,如果没有 ACK 的话,过一段时间会 page 其他人;
- 有协同处理的功能,记录处理流程。比如可以在 Alert reaction 上面标记 alert,一键创建工单,评论等,所有时间会根据原先 alert 的路由策略发送更新消息。比如,Alertmanager 将 alert 发送到了 3 个群组,那么后续对于这个 alert 做出的更新会继续通知到这三个群组;
最近发现这样还是不够的。很多 alert 需要人工处理,或者需要更加复杂的判断条件,仅仅用 metrics 无法表达出这样的 alert rule。比如,当发生 A 的时候,需要去检查 B,C,如果 B 和 C 都没有问题,则认为 A 有问题,如果其中一者有问题,我们认为不是 A 的问题。
即,我们需要用代码去定制 Alert rule,或者说需要用代码去处理发生的 alert。最近就写了这么一个框架。
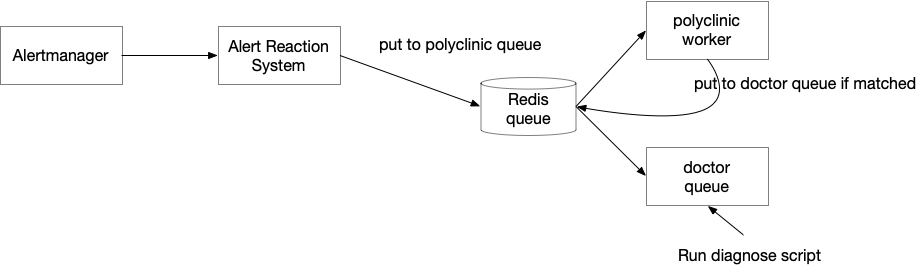
框架的原理很简单:当 Alert Reaction 系统从 Alertmanager 收到 alert 的时候,将 alert 放到一个任务队列中,队列我选择的是用基于 Redis 做 broker 的 rq。
任务队列本质上有两个:
- 第一个叫做 polyclinic (这在新加坡叫做综合医院,或者家庭门诊,人们需要看病的话首先要去这里咨询全科医生),polyclinic 会收到所有的 alert,然后匹配已注册的诊断程序(医生,doctor),如果匹配的话,将产生一个新的任务队列,放入 doctor queue
- Doctor queue 是真正执行诊断程序的 queue。没有什么逻辑,只是运行用户定义的函数
对于用户来说,如果想要使用脚本来处理 alert 的话,只需要定义两个事情:
- 我的脚本能够处理哪一些 alert
- 如何处理(即代码逻辑)
我设计的目标是让用户需要写的代码足够少,上线速度足够快。因为这个编码的场景是需要不断调试,优化,来处理各种各样 alert 的场景。
我设计了一个装饰器,用户使用一个装饰器,只需要写一个函数,就可以了:
|
1 2 3 4 |
@diagnose({"alertname": "disk_full", job="nginx"}, timeout="30s") def disk_clean(alert, alert_id): # do something with other systems post_comment(alert_id, "I am groot!") |
其中 diagnose 装饰器第一个参数就是如何 match alert,是和 PromQL 一样的 match 逻辑,不过只支持 equals match,不支持正则,not 等,因为用户函数的入参是携带了 alert 的原文的,所以如果要做更加复杂的 match 的话,可以在自己的代码中实现,如果不 match 在代码返回即可。post_comment 是框架所带的 SDK 的功能,可以回复评论到 Alert Reaction 系统上。
这个简单的实现带来了很多问题。
第一个问题是如何加载用户的代码。按照 Python 的 import 机制,如果这脚本文件从来没有被 import 过,那么不会被加载回 Python 的解释器的。一种方法是在 __init__ 里全 import 一遍,但是这样,每次添加新的诊断脚本,都需要记住要修改 import,否则,如果忘了的话,就比较难 debug 为什么我的脚本没有运行;另一种方法,就是我现在用的,worker 在启动的时候将用户脚本的目录全部扫描 import 一遍。感觉也不太优雅,也没有找到其他好的方法。
第二个问题是如何区分不同的诊断程序。比如各种 bot 都去给 alert 评论,怎么知道哪一条评论是谁发的。为了减少用户设置一个字段,这里直接用 function name 了,这个 decorator 的实现如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
def diagnose(match_alert_labels=None, enable=True, timeout="60s"): """ Args: match_alert_labels: dict, {"label": "value"}, currnetly only support equals match, `{}` will match all alerts. enable: default to True. this field is used to keep the code but disable the function. timeout: int or string, timeout specifies the maximum runtime of the job before it’s interrupted and marked as failed. Its default unit is seconds and it can be an integer or a string representing an integer(e.g. 2, '2'). Furthermore, it can be a string with specify unit including hour, minute, second (e.g. '1h', '3m', '5s'). see: https://python-rq.org/docs/jobs/ """ matchers = match_alert_labels def real_decorator(func): def real_func(*args, **kwargs): threadlocal.current_doctor_name = func.__name__ logger.info("Now doctor %s take a look...", threadlocal.current_doctor_name) return func(*args, **kwargs) is_debug = os.getenv("DIAGNOSE_DEBUG") == "1" # for debugging, there is no job queue, so we need to run the `real_func` # but for debugging, there is job queue, and worker's function is actually replaced with `real_func` if is_debug: doctor = Doctor(matchers, real_func, timeout) else: doctor = Doctor(matchers, func, timeout) if enable: polyclinic.take_office(doctor) return real_func return real_decorator |
我是选择存储在 threadlocal 里面,然后用到的时候,比如在 post_comment 里,从 threadlocal 拿出来就可以了。有几个好处:
- 用户在调用
post_comment的时候,不需要用户传递任何参数,在post_comment内部拿出来 threadlocal 就可以知道是谁想要发出评论; - 在多线程环境下,比如多个 worker 同时执行,每一个都可以拿到正确的名字;
从上面的代码中可以看到还有一段 debug 相关的逻辑,这个很有意思,不是一个很容易理解的问题。一开始,我要让用户使用这个框架很方便地 debug,提供了几个功能:
- 可以针对构造的 alert 进行诊断测试,自己生成 alert 存在本地,然后一条命令就可以测试自己的程序;
- 可以直接针对线上的 alert 进行测试,直接一条命令就可以了
但是有一个问题,通过上面的架构描述,可以看到这个 alert 要被诊断,经过了很多系统,还有 job queue,用户本地测试可以跳过这些步骤,直接运行诊断程序就行。
那么为什么需要这段代码呢?
|
1 2 3 4 |
if is_debug: doctor = Doctor(matchers, real_func, timeout) else: doctor = Doctor(matchers, func, timeout) |
这里的区别就是我们放入 queue 的函数是被装饰的函数 real_func 还是原始函数 func. debug 环境没有经过 job queue,生产环境经过了 job queue。
如果有 job queue 在的话,中间存在一个序列化的过程。我们将任务放入 queue,实际上是在 Redis 里面存储了这个字符串。如果是被装饰的函数,rq 会将函数序列话成如下:
|
1 |
decorator.diagnose.<locals>.real_decorator.<locals>.real_func |
当 worker 拿到的话,反序列化出来是出错的。因为 worker 跑的时候装饰器已经运行完了,已经没有装饰器的上下文了。
如果 enqueue 的是原始函数,那么 worker 拿出来,其实运行的还是被装饰之后的函数,因为 worker 运行的时候,装饰器已经跑完了,所以原始函数实际上是运行完装饰器之后的函数了。(有点绕,注意这段代码在跑的时候,是装饰器的初始化阶段)
Debug 的时候没有 job queue,所以也就不存在序列化和反序列化,我们如果 enqueue 的是 func,那么实际跑的就是 func,因为这个场景没有 worker,没有人把装饰器都 evaluate 一遍再去跑实际的代码。如果是 func 的话,没有注入 threadlocal 的代码,后面获取 threadlocal 的时候就会报错。
除了这一个地方比较绕,其他的都比较直观。其他人写起来也比较好上手,关键是本地测试非常方便。
后记,我之前在蚂蚁金服的时候,也参与过类似的一个项目。回忆起来让人感慨万分。
这个项目有很多团队参与:老板设想的是所有 alert 1 分钟内发现,自动定位,自动恢复。分了三个组去完成这个目标。我们要对接监控系统发出来的消息,对接业务部门(我们的用户),对接上的成本难以想象的大,API 全没文档,数据格式乱七八糟,有一个叫 sunfire 的系统返回的监控数据是一个 json,其中有一个字段的 value 是 string,但是是一个 json 形式的 string,decode 之后里面还有一个字段是 json 形式的 string,我称之为 json in json in json,如果不反序列化,看到的都是 \\\\\\"\\\\"\\" 之类嵌套 N 层的转译符号,含义全靠猜。我们项目要想做出成果,一个关键就是搞大,所以就拉了很多人参与我们的项目,强制用户来这个诊断平台(那时候还叫中台)写规则。但是平台设计的糟糕,用户不会用,触发链条很长,测试成本很高,测试的方法就是在丁丁上喊其他组的人触发一下,效率很低。
为此搞了个闭关项目,还有誓师大会,做成了运动式的项目。实际上,第一个组胡乱配告警,配了上千条,平时没事也在一直发,每次故障总是能找出来几条 alert,可以说我们的发现率是 100% 了。做定位的,因为告警配置的垃圾所以我的工作相对也好做,绩效也不错。就是自愈比较难做。
前几天前同事戏称蚂蚁的项目是“年包”项目,指项目基本上只做一年。我那个时候做的项目一年之后也确实没了。
你好,请问Alert reaction系统的源码有吗?
不好意思,这个还没有,我写的,跟内部系统耦合比较深,通知,用户系统等等,以后有精力了重新写一个开源吧。
好的,谢谢