这篇文章介绍如何使用 PromQL 查询 Prometheus 里面的数据。包括如何使用函数,理解这些函数,Metrics 的逻辑等等,因为看了很多教程试图学习 PromQL,发现这些教程都直说有哪些函数、语法是什么,看完之后还是很难理解。比如 [1m] 是什么意思?为什么有的函数需要有的函数不需要?它对 Grafana 上面展示的数据有什么影响?rate 和 irate 的区别是什么?sum 和 rate 要先用哪个后用哪个?经过照葫芦画瓢地写了很多 PromQL 来设置监控和告警规则,我渐渐对 PromQL 的逻辑有了一些理解。这篇文章从头开始,通过介绍 PromQL 里面的逻辑,来理解这些函数的作用。本文不会一一回答上面这些问题,但是我的这些问题都是由于之前对 PromQL 里面的逻辑和概念不了解,相信读完本文之后,这些问题的答案就显得不言而喻了。
本文不会深入讲解 Prometheus 的数据存储原理,Prometheus 对 metrics 的抓取原理等问题;也不会深入介绍 PromQL 中每一个 API 的实现。只会着重于介绍如何写 PromQL 的原理,和它的设计逻辑。但是相信如果理解了本文这些概念,可以更透彻地理解和阅读 Prometheus 官方的文档。
Metric 类型
Prometheus 里面其实只有两种数据类型。Gauge 和 Counter。
Gauge
Gauge 是比较符合直觉的。它就是表示一个当前的“状态”,比如内存当前是多少,CPU 当前的使用率是多少。
Counter
Counter 有一些不符合直觉。我想了很久才理解(可能我有点钻牛角尖了)。Counter 是一个永远只递增的 Metric 类型。
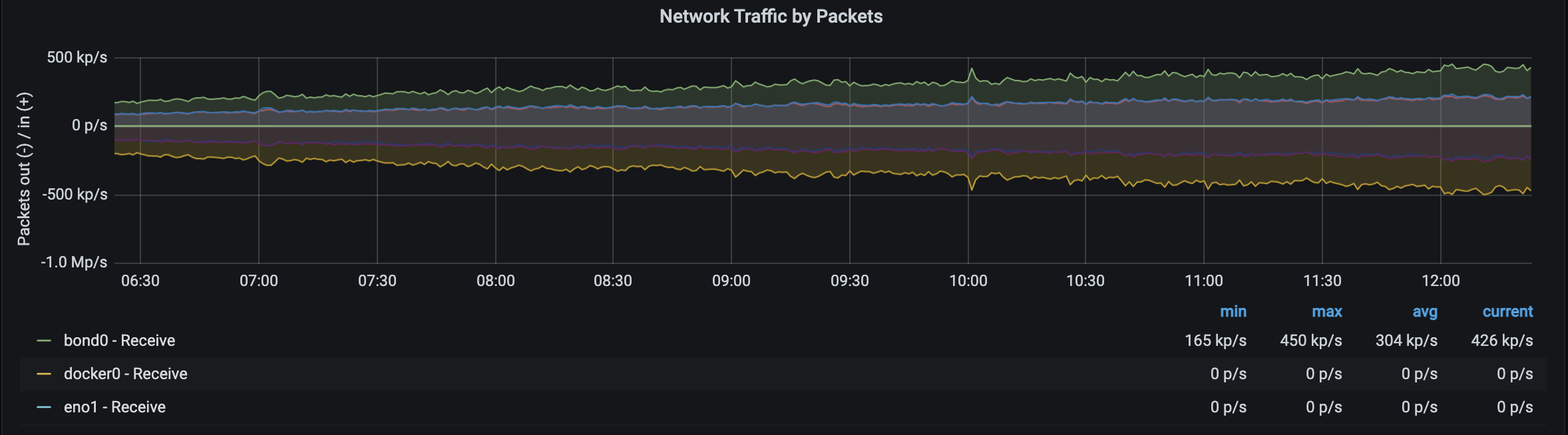
使用 Counter 计算得到的,每秒收到的 packet 数量
典型的 Counter 举例:服务器服务的请求数,服务器收到了多少包(上图)。这个数字是只增不减的,用 Counter 最合适了。因为每一个时间点的总请求数都会包含之前时间点的请求数,所以可以理解成它是一个“有状态的”(非官方说法,我这么说只是为了方便读者理解)。使用 Counter 记录每一个时间点的“总数”,然后除以时间,就可以得到 QPS,packets/s 等数据。
为什么需要 Counter 呢?先来回顾一下 Gauge,你可以将 Gauge 理解为“无状态的”,即类型是 Gauge 的 metric 不需要关心历史的值,只需要记录当前的值是多少就可以了。比如当前的内存值,当前的 CPU 使用率。当然,如果你想要查询历史的值,依然是可以查到的。只不过对于每一个时间点的“内存使用量”这个 Gauge,不包含历史的数据。那么可否用 Gauge 来代替 Counter 呢?
Prometheus 是一个抓取的模型:服务器暴露一个 HTTP 服务,Prometheus 来访问这个 HTTP 接口来获取 metrics 的数据。如果使用 Gauge 来表示上面的 pk/s 数据的话,只能使用这种方案:使用这个 Metric 记录自从上次抓取过后收到的 Packet 总数(或者直接记录 Packet/s ,原理是一样的)。每次 Prometheus 来抓取数据之后,就将这个值重置为 0. 这样的实现就类似 Gauge 了。
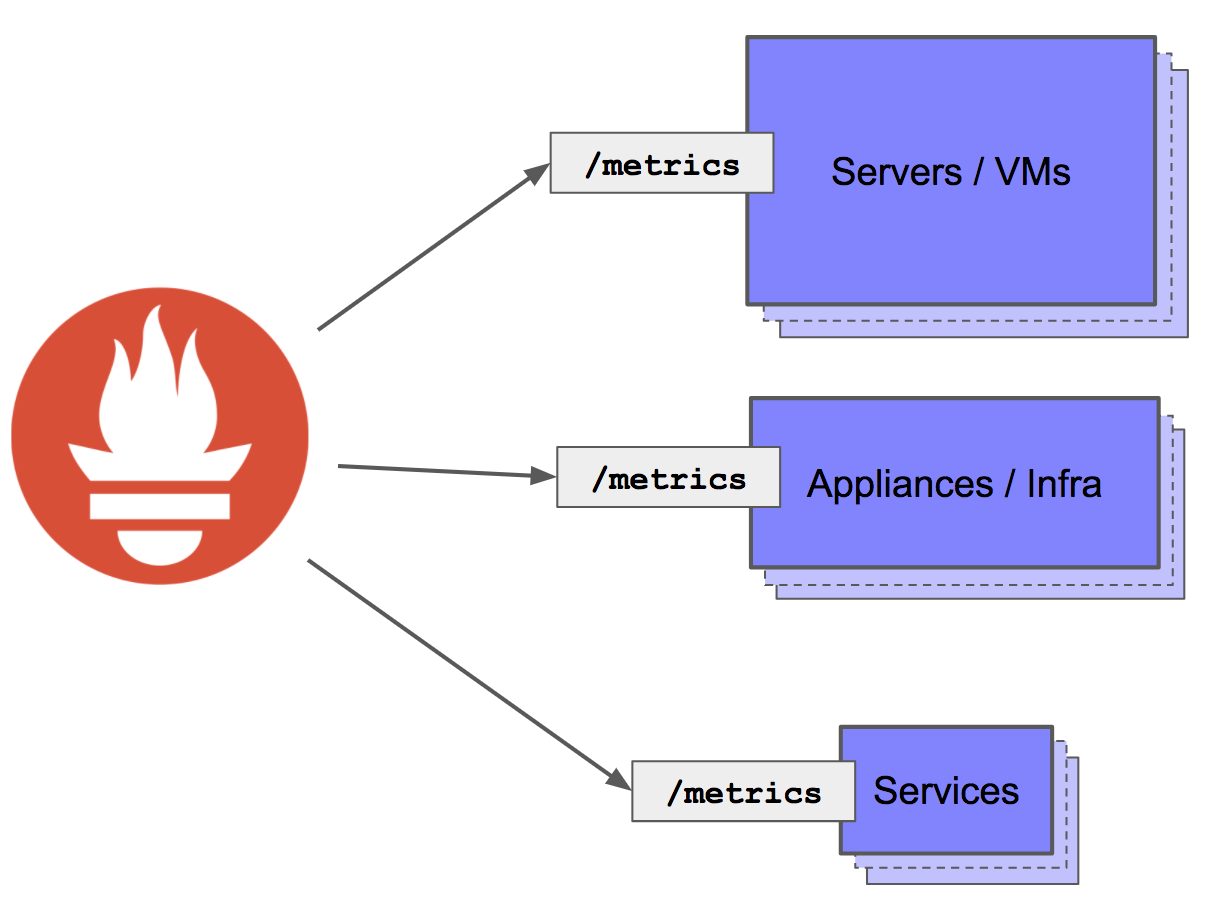
Prometheus 的抓取模型,去访问服务的 HTTP 来抓取 metrics
这种实现的缺点有:
- 抓取数据本质是 GET 操作,但是这个 GET 操作却会修改数据(将 metric 重置为0),所以会带来很多隐患,比如一个服务每次只能由一个 Prometheus 来抓取,不能扩展;不能 cURL 这个
/metrics来进行 debug,因为会影响真实的数据,等等。 - 如果服务器发生了重启,数据将会清零,会丢失数据(虽然 Counter 也没有从本质上解决这个问题)。
Counter 因为是一个只递增的值,所以它可以判断数字下降的问题,比如现在请求的 Count 数是 1000,然后下次 Prometheus 来抓取发现变成了 20,那么 Prometheus 就知道,真实的数据不可能是 20,因为请求数是不可能下降的。所以它会将这个点认为是 1020。
然后用 Counter 也可以解决多次读的问题,服务器上的 /metrics,可以使用 cURL 和 grep 等工具实时查看,不会改变数据。Counter 有关的细节可以参考下 How does a Prometheus Counter work?
其实 Prometheus 里面还有两种数据类型,一种是 Histogram,另一种是 Summary.
但是这两种类型本质上都是 Counter。比如,如果你要统计一个服务处理请求的平均耗时,就可以用 Summary。在代码中只用一种 Summary 类型,就可以暴露出收到的总请求数,处理这些请求花费的总时间数,两个 Counter 类型的 metric。算是一个“语法糖”。
Histogram 是由多个 Counter 组成的一组(bucket)metrics,比如你要统计 P99 的信息,使用 Histogram 可以暴露出 10 个 bucket 分别存放不同耗时区间的请求数,使用 histogram_quantile 函数就可以方便地计算出 P99(《P99是如何计算的?》). 本质上也是一个“糖”。假如 Prometheus 没有 Histogram 和 Summary 这两种 Metric 类型,也是完全可以的,只不过我们在使用上就需要多做很多事情,麻烦一些。
讲了这么说,希望读者已经明白 Counter 和 Gauge 了。因为我们接下来的查询会一直跟这两种 Metric 类型打交道。
Selectors
下面这张图简单地表示了 Metric 在 Prometheus 中的样子,以给读者一个概念。
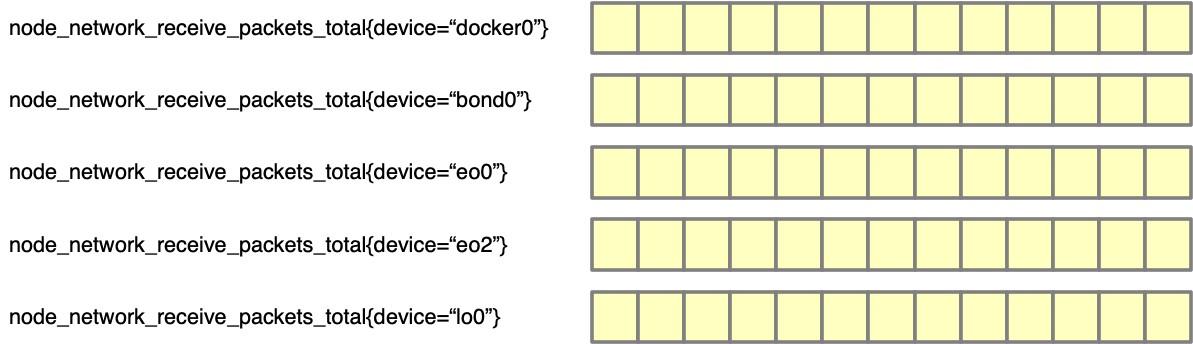
如果我们直接在 Grafana 中使用 node_network_receive_packets_total 来画图的话,就会得到 5 条线。

Counter 的值很大,并且此图基本上看不到变化趋势。因为它们只增加,可以认为是这个服务器自存在以来收到的所有的包的数量。
Metric 可以通过 label 来进行选择,比如 node_network_receive_packets_total{device=”bond0″} 就会只查询到 bond0 的数据,绘制 bond0 这个 device 的曲线。也支持正则表达式,可以通过 node_network_receive_packets_total{device=~”en.*”} 绘制 en0 和 en2 的曲线。
其实,metric name 也是一个 “label”, 所以 node_network_receive_packets_total{device="bond0"} 本质上是 {__name__="node_network_receive_packets_total", device="bond0"} 。但是因为 metric name 基本上是必用的 label,所以我们一般用第一种写法, 这样看起来更易懂。
PromQL 支持很复杂的 Selector,详细的用法可以参考文档。 值得一提的是,Prometheus 是图灵完备 (Turing Complete)的(Surprise!)。
实际上,如果你使用下面的查询语句,将会仅仅得到一个数字,而不是整个 metric 的历史数据(node_network_receive_packets_total{device=~"en.*"} 得到的是下图中黄色的部分。

这个就是 Instant Vector:只查询到 metric 的在某个时间点(默认是当前时间)的值。
PromQL 语言的数据类型
为了避免读者混淆,这里说明一下 Metric Type 和 PromQL 查询语言中的数据类型的区别。很简单,在写 PromQL 的时候,无论是 Counter 还是 Gauge,对于函数来说都是一串数字,他们数据结构上没有区别。我们说的 Instant Vector 还是 Range Vector, 指的是 PromQL 函数的入参和返回值的类型。
Instant Vector
Instant 是立即的意思,Instant Vector 顾名思义,就是当前的值。假如查询的时间点是 t,那么查询会返回距离 t 时间点最近的一个值。
常用的另一种数据类型是 Range Vector。
Range Vector
Range Vector 顾名思义,返回的是一个 range 的数据。
Range 的表示方法是 [1m],表示 1 分钟的数据。也可以使用 [1h] 表示 1 小时,[1d] 表示 1 天。支持的所有的 duration 表示方法可以参考文档。
假如我们对 Prometheus 的采集配置是每 10s 采集一次,那么 1 分钟内就会有采集 6 次,就会有 6 个数据点。我们使用node_network_receive_packets_total{device=~“.*”}[1m] 查询的话,就可以得到以下的数据:两个 metric,最后的 6 个数据点。

Prometheus 大部分的函数要么接受的是 Instant Vector,要么接受的是 Range Vector。所以要看懂这些函数的文档,就要理解这两种类型。
在详细解释之前,请读者思考一个问题:在 Grafana 中画出来一个 Metric 的图标,需要查询结果是一个 Instant Vector,还是 Range Vector 呢?
答案是 Instant Vector (Surprise!)。
为什么呢?要画出一段时间的 Chart,不应该需要一个 Range 的数据吗?为什么是 Instant Vector?
答案是:Range Vector 基本上只是为了给函数用的,Grafana 绘图只能接受 Instant Vector。Prometheus 的查询 API 是以 HTTP 的形式提供的,Grafana 在渲染一个图标的时候会向 Prometheus 去查询数据。而这个查询 API 主要有两种:
第一种是 /query:查询一个时间点的数据,返回一个数据值,通过 ?time=1627111334 可以查询指定时间的数据。
假如要绘制 1 个小时内的 Chart 的话,Grafana 首先需要你在创建 Chart 的时候传入一个 step 值,表示多久查一个数据,这里假设 step=1min 的话,我们对每分钟需要查询一次数据。那么 Grafana 会向 Prometheus 发送 60 次请求,查询 60 个数据点,即 60 个 Instant Vector,然后绘制出来一张图表。

Grafana 的 step 设置
当然,60 次请求太多了。所以就有了第二种 API query_range,接收的参数有 ?start=<start timestamp>&end=<end timestamp>&step=60。但是这个 API 本质上,是一个语法糖,在 Prometheus 内部还是对 60 个点进行了分别计算,然后返回。当然了,会有一些优化。
然后就有了下一个问题:为什么 Grafana 偏偏要绘制 Instant Vector,而不是 Range Vector 呢?
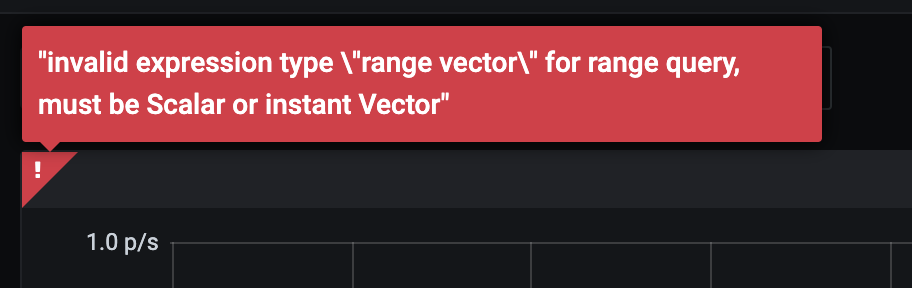
Grafana 只接受 Instant Vector, 如果查询的结果是 Range Vector, 会报错
因为这里的 Range Vector 并不是一个“绘制的时间”,而是函数计算所需要的时间区间。看下面的例子就容易理解了。
来解释一下这个查询:
rate(node_network_receive_packets_total{device=~”en.*”}[1m])

查询每秒收到的 packet 数量
node_network_receive_packets_total 是一个 Counter,为了计算每秒的 packet 数量,我们要计算每秒的数量,就要用到 rate 函数。
先来看一个时间点的计算,假如我们计算 t 时间点的每秒 packet 数量,rate 函数可以帮我们用这段时间([1m])的总 packet 数量,除以时间 [1m] ,就得到了一个“平均值”,以此作为曲线来绘制。
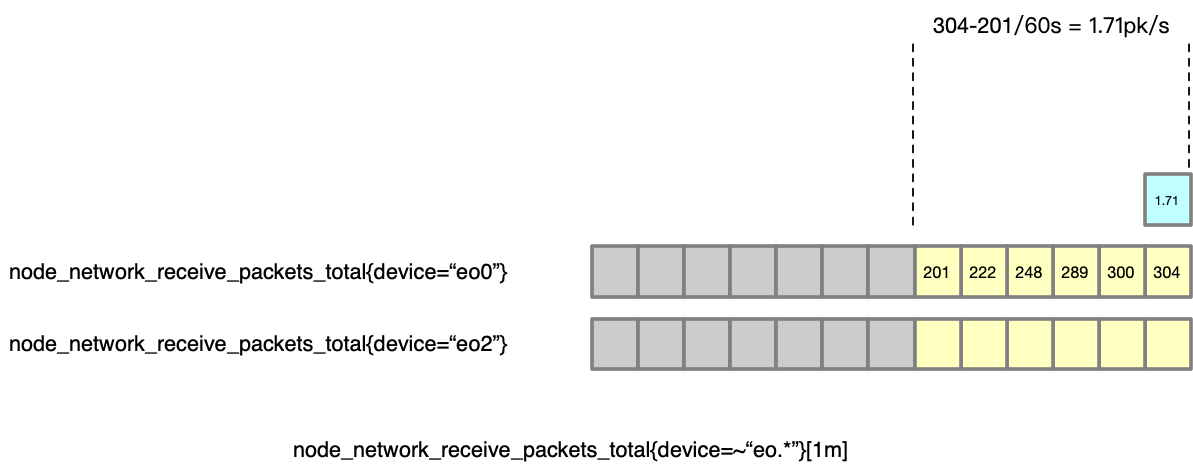
以这种方法就得到了一个点的数据。
然后我们对之前的每一个点,都以此法进行计算,就得到了一个 pk/s 的曲线(最长的那条是原始的数据,黄色的表示 rate 对于每一个点的计算过程,蓝色的框为最终的绘制的点)。
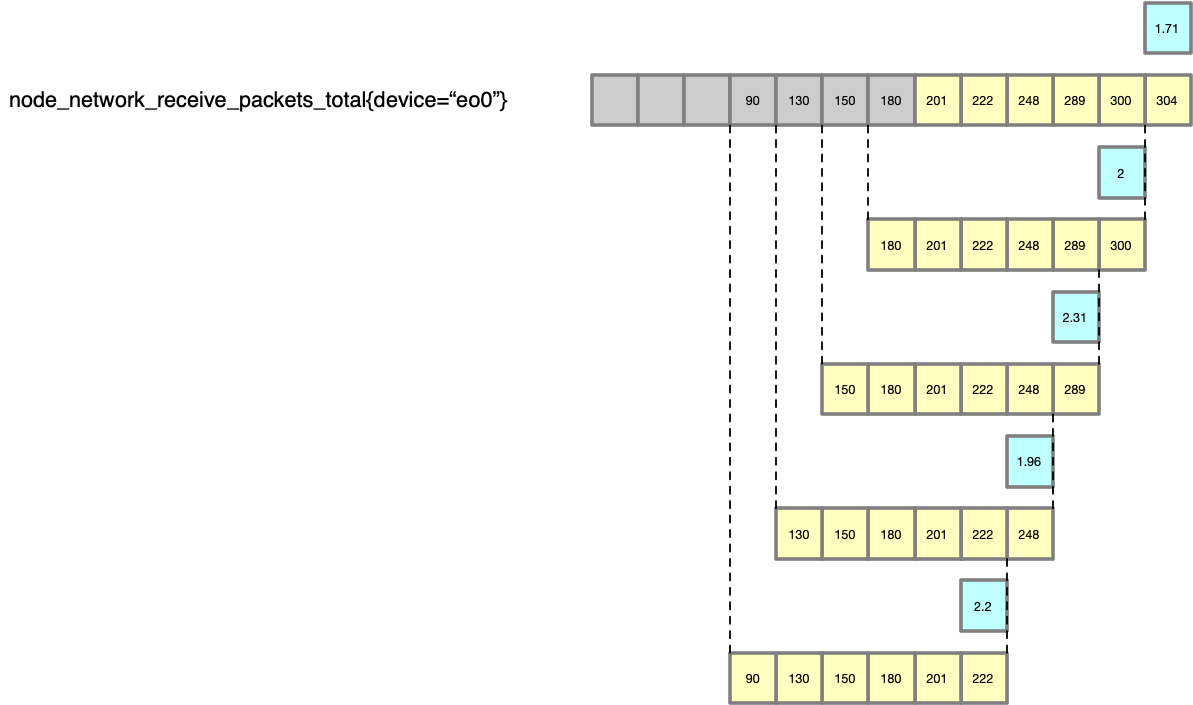
所以这个 PromQL 查询最终得到的数据点是:… 2.2, 1.96, 2.31, 2, 1.71 (即蓝色的点)。
这里有两个选中的 metric,分别是 en0 和 en2,所以 rate 会分别计算两条曲线,就得到了上面的 Chart,有两条线。
rate, irate 和 increase
很多人都会纠结 irate 和 rate 有什么区别。看到这里,其实就很好解释了。
以下来自官方的文档:
irate()
irate(v range-vector) calculates the per-second instant rate of increase of the time series in the range vector. This is based on the last two data points.
即,irate 是计算的最后两个点之间的差值。可以用下图来表示:
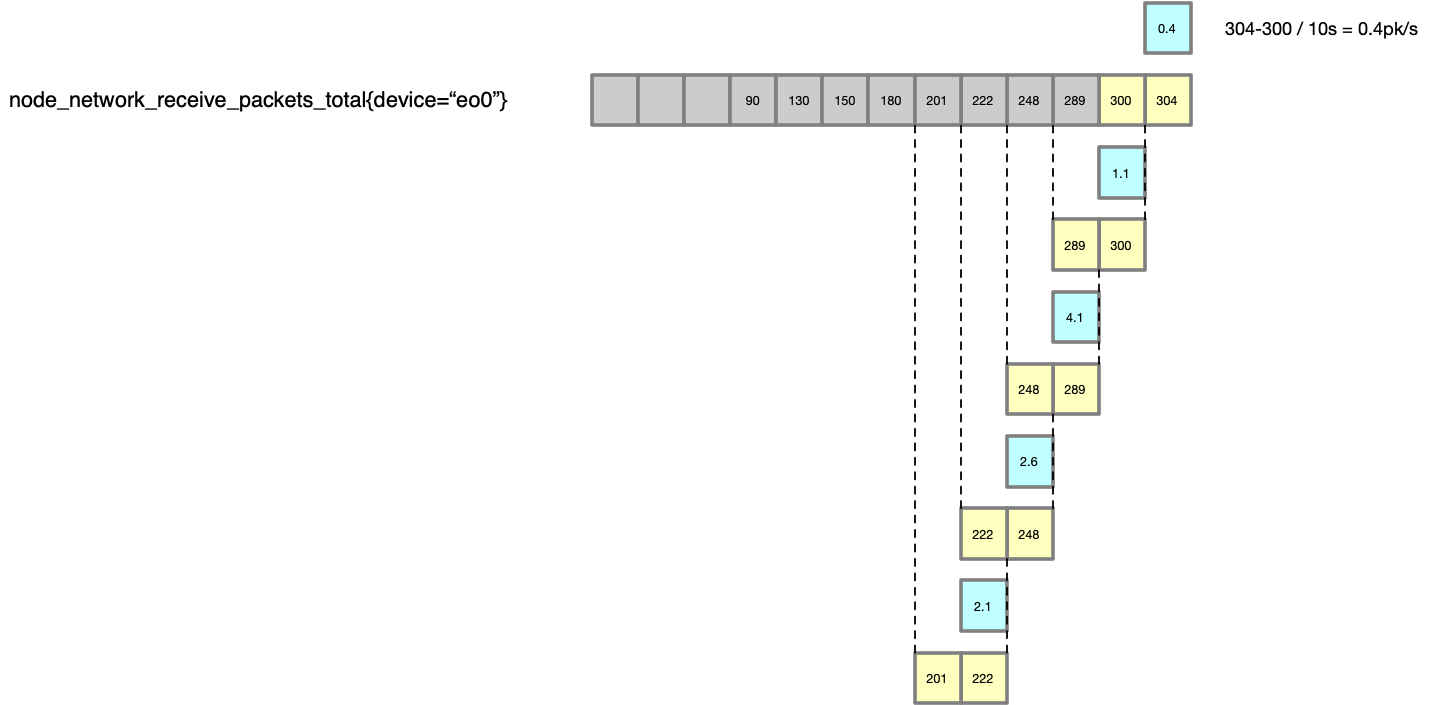
irate 的计算方式
自然,因为只用最后两个点的差值来计算,会比 rate 平均值的方法得到的结果,变化更加剧烈,更能反映当时的情况。那既然是使用最后两个点计算,这里又为什么需要 [1m] 呢?这个 [1m] 不是用来计算的,是用来限制找 t-2 个点的时间的,比如,如果中间丢了很多数据,那么显然这个点的计算会很不准确,irate 在计算的时候会最多向前在 [1m] 找点,如果超过 [1m] 没有找到数据点,这个点的计算就放弃了。
在现实中的例子,可以将上面查询的 rate 改成 irate。
irate(node_network_receive_packets_total{device=~”en.*”}[1m])

对比与之前的图,可以看到变化更加剧烈了。
那么,是不是我们总是使用 irate 比较好呢?也不是,比如 requests/s 这种,如果变化太剧烈,从面板上你只能看到一条剧烈抖动导致看不清数值的曲线,而具体值我们是不太关心的,我们可能更关心一天中的 QPS 变化情况;但是像是 CPU,network 这种资源的变化,使用 irate 更加有意义一些。
还有一个函数叫做 increase,它的计算方式是 end - start,没有除。计算的是每分钟的增量。比较好理解,这里就不画图了。
这三个函数接受的都是 Range Vector,返回的是 Instant Vector,比较常用。
另外需要注意的是,increase 和 rate 的 range 内必须要有至少 4 个数据点。详细的解释可以见这里:What range should I use with rate()?
介绍了这两种类型,那么其他的 Prometheus 函数应该都可以看文档理解了。Prometheus 的文档中会将函数这样标注:
changes()
For each input time series, changes(v range-vector) returns the number of times its value has changed within the provided time range as an instant vector.
我们就知道,changes() 这个函数接受的是一个 range-vector, 所以要带上类似于 [1m] 。不能传入不带类似 [1m] 的 metrics,类似于这样的使用是不合法的:change(requests_count{server="server_a"},这样就相当于传入了一个 Instant Vector。
看到这里,你应该已经成为一只在 Prometheus 里面自由翱翔的鸟儿了。接下来可以抱着文档去写查询了,但是在这之前,让我再介绍一点非常重要的误区。
使用函数的顺序问题
在计算 P99 的时候,我们会使用下面的查询:
|
1 2 3 4 |
histogram_quantile(0.99, sum by (le) (rate(http_request_duration_seconds_bucket[10m])) ) |
首先,Histogram 是一个 Counter,所以我们要使用 rate 先处理,然后根据 le 将 labels 使用 sum 合起来,最后使用 histogram_quantile 来计算。这三个函数的顺序是不能调换的,必须是先 rate 再 sum,最后 histogram_quantile。
为什么呢?这个问题可以分成两步来看:
rate 必须在 sum 之前。前面提到过 Prometheus 支持在 Counter 的数据有下降之后自动处理的,比如服务器重启了,metric 重新从 0 开始。这个其实不是在存储的时候做的,比如应用暴露的 metric 就是从 2033 变成 0 了,那么 Prometheus 就会忠实地存储 0. 但是在计算 rate 的时候,就会识别出来这个下降。但是 sum 不会,所以如果先 sum 再 rate,曲线就会出现非常大的波动。详细见这里。
histogram_quantile 必须在最后。在《P99是如何计算的?》这篇文章中介绍了 P99 的原理。也就是说 histogram_quantile 计算的结果是近似值,去聚合(无论是 sum 还是 max 还是 avg)这个值都是没有意义的。
以上都是个人理解,可能存在错误,请在评论批评指正。
最后推荐一个入门的视频,讲得非常好:https://www.youtube.com/watch?v=hTjHuoWxsks
1. 总请求书 -> 总请求数
2. `在现实中的例子,可以将上面查询的 rate 改成 irate。` 下面的示例查询语句是 `rate`
非常感谢,都已经改正。
其实计算 histogram_quantile 的时候不一定非得用 rate,用 increase 也是一样的。是吗?
用 increase 也是 valid 的,但是像博客里面写到的,increase 没有除,代表的不是每秒的增量而是一段时间的增量,所以语义变了。
其实感觉没什么问题,因为 histogram_quantile 计算的时候关心的是比例,语义上感觉也没啥问题。
是的我感觉是一样的,虽然一个计算的是平均值,一个计算的是一段时间的增量,但是本质上每个 bucket 之间的比例是一样的。
我实际去画了一下,发现也是一样的。
两个typo:
1. 图标题“Grafana 只接受 Range Vector, 如果查询的结果是 Instant Vector, 会报错” 好像搞反了
2. “不能传传入不带类似 [1m] 的 metrics”
https://www.robustperception.io/blog 绝对是个神奇的网站,我就是在那儿搞懂rate和irate的区别的。。。
https://www.robustperception.io/irate-graphs-are-better-graphs
另外rate的时间区间至少要是4倍抓取时间间隔,也是之前解决了我的一个问题
https://www.robustperception.io/what-range-should-i-use-with-rate
谢谢,两处错误都已经改正。
链接很有用! https://www.robustperception.io/ 很不错,貌似就是 Prometheus 的人做的,代表了 Prometheus 的官方理解,我也订阅了。
指的一提的是 —> 值得一提
谢谢,已经改正
histogram_quantile(0.9,
sum by (le)
(rate(http_request_duration_seconds_bucket[10m]))
)
计算P99, 这里的入参应该传0.99, 而不是0.9吧, 0.9是P90
谢谢,已经改正。
Pingback: PromQL 使用多个 label 组合过滤 | 卡瓦邦噶!
Pingback: 用 PromQL 计算 SLI 和 SLO | 卡瓦邦噶!
Pingback: Alert 自动诊断系统的设计 | 卡瓦邦噶!