这篇文章是 IRedis 的第三篇开发笔记。一直以来,IRedis 的补全都是基于 prompt_toolkit 的 regular_language 来实现的(一个例子)。我需要用正则表达式来验证用户输入的 Redis 命令是否合法,从中抓出来 token,然后对这些 token 进行自动补全。随着开发,支持的 Redis 的命令越来越多,这个正则表达式已经膨胀到 200+ 行了,编译速度也令人难以忍受。
这个问题困扰了我将近3个月,我尝试过各种各样的方法,从身边的朋友那里听取不同的思路和建议,终于在最近近乎完美地解决了这个问题。以至于兴奋的睡不着觉。
这篇文章分享一下这个问题,为了解决这个问题尝试过的方案,以及最终采用的方案的工作原理。读者从这个问题和方案本身可能并不会学到什么可以 Take away 的东西,因为很难在遇到这种问题(这也是这个问题比较难解决的原因之一)。但是我更想分享一下解决的思路,以及它带给我的启发。可能对于将来的我,再回来看的时候,会发现解决问题是如此美妙的一个过程,编程本身又是多么充满乐趣的事情。
问题:用正则来匹配输入……
为了接下来的讨论,我先描述一下我面临的问题。
我要写一个 Redis 命令行的客户端,支持对 Redis 命令的自动补全。(相关文章 IRedis 开发记录:Redis 命令语法的处理 )。但是我不会从头开始写这个命令行客户端的输入输出,而是选择了 IPython 和 mycli/pgcli 都用的一个库:prompt_toolkit. 它是用了 Python 的正则表达式的 named group 功能,从输入的内容中抓出来 token。比如这个例子中,语法的正则是这么写的:
|
1 2 |
(\s* (?P<operator1>[a-z]+) \s+ (?P<var1>[0-9.]+) \s+ (?P<var2>[0-9.]+) \s*) | (\s* (?P<operator2>[a-z]+) \s+ (?P<var1>[0-9.]+) \s*) |
当输入 abc (注意后面有个空格)的时候,abc 就匹配到了 <operator1> ,然后空格匹配到了 \s+ ,框架就知道后面要输入的是一个 var1 了。
类似的,我写的 Redis 的命令节选如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
REDIS_COMMANDS = fr""" (\s* (?P<command_commandname>({t['command_commandname']})) \s+ {COMMANDNAME} \s*)| (\s* (?P<command_slots>({t['command_slots']})) \s+ {SLOTS} \s*)| (\s* (?P<command_node>({t['command_node']})) \s+ {NODE} \s*)| (\s* (?P<command_slot>({t['command_slot']})) \s+ {SLOT} \s*)| (\s* (?P<command_failoverchoice>({t['command_failoverchoice']})) \s+ {FAILOVERCHOICE} \s*)| (\s* (?P<command_resetchoice>({t['command_resetchoice']})) \s+ {RESETCHOICE} \s*)| (\s* (?P<command_slot_count>({t['command_slot_count']})) \s+ {SLOT} \s+ {COUNT} \s*)| (\s* (?P<command_key_samples_count>({t['command_key_samples_count']})) \s+ {KEY} \s+ {SAMPLES} \s+ {COUNT} \s*)| (\s* (?P<command>({t['command']})) \s*)| ... |
因为 Redis 的命令不像 SQL 那样是结构化的语法,每个数据类型的命令格式都不一样,所以写起来要用或 | 将这些语法都连接起来。
另外还要补充一点的是,我写的这个正则并不是直接拿去匹配用户输入了,因为框架需要知道这个 token 的下一个 token 可能是什么,以此来做自动补全的提示。所以其实我的这个正则是交给框架去解析了,而不是直接 re.compile() 。框架会将这个正则拆散,然后一个一个编译。这一点也导致了后面会讲到的一些方案行不通。
另另外要补充的是,不光是拆开这些正则就可以了,如果这样到好了,也就是不到 100 个正则,编译一下也是很快的。作为用来匹配用户输入的问题是,即使用户只输入了一部分,也应该认为是合法的。比如正则是要匹配 SET 命令,而用户输入了 SE,那么也应该认为这是一个合法输入,而不应该显示成下图这样的非法提示。
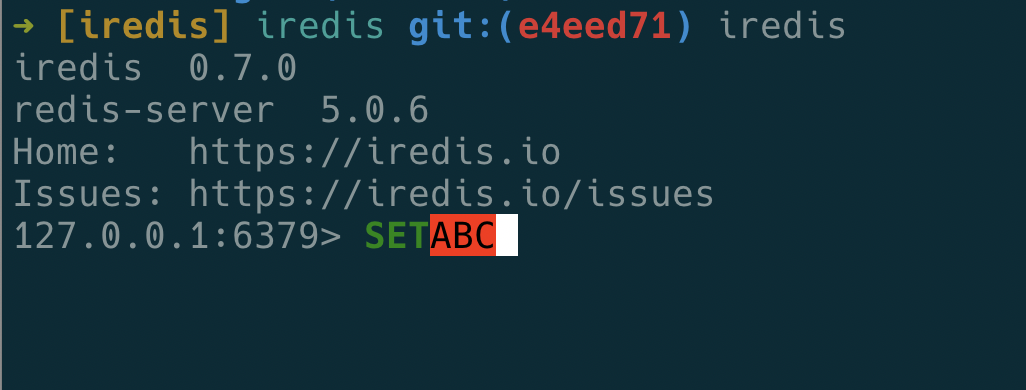
那么怎么做到这一点呢?这个框架的方案是解析正则,然后分析出更多的正则来匹配部分输入。比如 SET,那么根据此应该生成 SET|SE|S,看起来也不复杂,但是如果支持的参数越来越多,需要编译的正则的数量将会呈指数级上涨。
举个简单的例子,下面这个语法:
|
1 2 3 4 5 |
REDIS_COMMANDS = fr""" (\s* (?P<command_key>({t['command_key']})) \s+ {KEY} \s*)| (\s* (?P<command_type_conntype_x>({t['command_type_conntype_x']})) (\s+ {TYPE_CONST} \s+ {CONNTYPE})? \s*) """ |
最终生成的正则是这样子:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 |
^(?:(?:(?:\s){0,}(?P<n5>(?:(?:(?:C)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n6>(?:(?:C(?:L)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n7>(?:(?:CL(?:U)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n8>(?:(?:CLU(?:S)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n9>(?:(?:CLUS(?:T)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n10>(?:(?:CLUST(?:E)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n11>(?:(?:CLUSTE(?:R)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n12>(?:(?:CLUSTER(?:\s)*(?:(?:\s)?)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n13>(?:(?:CLUSTER(?:\s){1,}(?:K)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n14>(?:(?:CLUSTER(?:\s){1,}K(?:E)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n15>(?:(?:CLUSTER(?:\s){1,}KE(?:Y)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n16>(?:(?:CLUSTER(?:\s){1,}KEY(?:S)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n17>(?:(?:CLUSTER(?:\s){1,}KEYS(?:L)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n18>(?:(?:CLUSTER(?:\s){1,}KEYSL(?:O)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n19>(?:(?:CLUSTER(?:\s){1,}KEYSLO(?:T)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n20>(?:(?:(?:D)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n21>(?:(?:D(?:U)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n22>(?:(?:DU(?:M)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n23>(?:(?:DUM(?:P)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n24>(?:(?:(?:P)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n25>(?:(?:P(?:E)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n26>(?:(?:PE(?:R)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n27>(?:(?:PER(?:S)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n28>(?:(?:PERS(?:I)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n29>(?:(?:PERSI(?:S)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n30>(?:(?:PERSIS(?:T)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n31>(?:(?:(?:P)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n32>(?:(?:P(?:T)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n33>(?:(?:PT(?:T)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n34>(?:(?:PTT(?:L)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n35>(?:(?:(?:T)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n36>(?:(?:T(?:T)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n37>(?:(?:TT(?:L)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n38>(?:(?:(?:T)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n39>(?:(?:T(?:Y)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n40>(?:(?:TY(?:P)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n41>(?:(?:TYP(?:E)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n42>(?:(?:(?:H)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n43>(?:(?:H(?:G)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n44>(?:(?:HG(?:E)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n45>(?:(?:HGE(?:T)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n46>(?:(?:HGET(?:A)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n47>(?:(?:HGETA(?:L)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n48>(?:(?:HGETAL(?:L)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n49>(?:(?:(?:H)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n50>(?:(?:H(?:K)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n51>(?:(?:HK(?:E)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n52>(?:(?:HKE(?:Y)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n53>(?:(?:HKEY(?:S)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n54>(?:(?:(?:H)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n55>(?:(?:H(?:L)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n56>(?:(?:HL(?:E)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n57>(?:(?:HLE(?:N)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n58>(?:(?:(?:H)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n59>(?:(?:H(?:V)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n60>(?:(?:HV(?:A)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n61>(?:(?:HVA(?:L)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n62>(?:(?:HVAL(?:S)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n63>(?:(?:(?:L)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n64>(?:(?:L(?:L)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n65>(?:(?:LL(?:E)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n66>(?:(?:LLE(?:N)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n67>(?:(?:(?:L)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n68>(?:(?:L(?:P)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n69>(?:(?:LP(?:O)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n70>(?:(?:LPO(?:P)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n71>(?:(?:(?:R)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n72>(?:(?:R(?:P)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n73>(?:(?:RP(?:O)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n74>(?:(?:RPO(?:P)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n75>(?:(?:(?:D)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n76>(?:(?:D(?:E)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n77>(?:(?:DE(?:B)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n78>(?:(?:DEB(?:U)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n79>(?:(?:DEBU(?:G)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n80>(?:(?:DEBUG(?:\s)*(?:(?:\s)?)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n81>(?:(?:DEBUG(?:\s){1,}(?:O)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n82>(?:(?:DEBUG(?:\s){1,}O(?:B)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n83>(?:(?:DEBUG(?:\s){1,}OB(?:J)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n84>(?:(?:DEBUG(?:\s){1,}OBJ(?:E)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n85>(?:(?:DEBUG(?:\s){1,}OBJE(?:C)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n86>(?:(?:DEBUG(?:\s){1,}OBJEC(?:T)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n87>(?:(?:(?:S)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n88>(?:(?:S(?:C)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n89>(?:(?:SC(?:A)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n90>(?:(?:SCA(?:R)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n91>(?:(?:SCAR(?:D)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n92>(?:(?:(?:S)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n93>(?:(?:S(?:M)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n94>(?:(?:SM(?:E)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n95>(?:(?:SME(?:M)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n96>(?:(?:SMEM(?:B)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n97>(?:(?:SMEMB(?:E)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n98>(?:(?:SMEMBE(?:R)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n99>(?:(?:SMEMBER(?:S)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n100>(?:(?:(?:Z)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n101>(?:(?:Z(?:C)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n102>(?:(?:ZC(?:A)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n103>(?:(?:ZCA(?:R)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n104>(?:(?:ZCAR(?:D)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n105>(?:(?:(?:D)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n106>(?:(?:D(?:E)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n107>(?:(?:DE(?:C)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n108>(?:(?:DEC(?:R)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n109>(?:(?:(?:G)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n110>(?:(?:G(?:E)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n111>(?:(?:GE(?:T)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n112>(?:(?:(?:I)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n113>(?:(?:I(?:N)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n114>(?:(?:IN(?:C)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n115>(?:(?:INC(?:R)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n116>(?:(?:(?:S)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n117>(?:(?:S(?:T)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n118>(?:(?:ST(?:R)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n119>(?:(?:STR(?:L)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n120>(?:(?:STRL(?:E)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n121>(?:(?:STRLE(?:N)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n122>(?:(?:(?:c)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n123>(?:(?:c(?:l)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n124>(?:(?:cl(?:u)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n125>(?:(?:clu(?:s)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n126>(?:(?:clus(?:t)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n127>(?:(?:clust(?:e)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n128>(?:(?:cluste(?:r)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n129>(?:(?:cluster(?:\s)*(?:(?:\s)?)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n130>(?:(?:cluster(?:\s){1,}(?:k)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n131>(?:(?:cluster(?:\s){1,}k(?:e)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n132>(?:(?:cluster(?:\s){1,}ke(?:y)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n133>(?:(?:cluster(?:\s){1,}key(?:s)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n134>(?:(?:cluster(?:\s){1,}keys(?:l)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n135>(?:(?:cluster(?:\s){1,}keysl(?:o)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n136>(?:(?:cluster(?:\s){1,}keyslo(?:t)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n137>(?:(?:(?:d)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n138>(?:(?:d(?:u)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n139>(?:(?:du(?:m)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n140>(?:(?:dum(?:p)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n141>(?:(?:(?:p)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n142>(?:(?:p(?:e)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n143>(?:(?:pe(?:r)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n144>(?:(?:per(?:s)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n145>(?:(?:pers(?:i)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n146>(?:(?:persi(?:s)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n147>(?:(?:persis(?:t)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n148>(?:(?:(?:p)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n149>(?:(?:p(?:t)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n150>(?:(?:pt(?:t)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n151>(?:(?:ptt(?:l)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n152>(?:(?:(?:t)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n153>(?:(?:t(?:t)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n154>(?:(?:tt(?:l)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n155>(?:(?:(?:t)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n156>(?:(?:t(?:y)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n157>(?:(?:ty(?:p)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n158>(?:(?:typ(?:e)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n159>(?:(?:(?:h)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n160>(?:(?:h(?:g)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n161>(?:(?:hg(?:e)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n162>(?:(?:hge(?:t)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n163>(?:(?:hget(?:a)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n164>(?:(?:hgeta(?:l)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n165>(?:(?:hgetal(?:l)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n166>(?:(?:(?:h)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n167>(?:(?:h(?:k)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n168>(?:(?:hk(?:e)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n169>(?:(?:hke(?:y)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n170>(?:(?:hkey(?:s)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n171>(?:(?:(?:h)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n172>(?:(?:h(?:l)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n173>(?:(?:hl(?:e)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n174>(?:(?:hle(?:n)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n175>(?:(?:(?:h)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n176>(?:(?:h(?:v)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n177>(?:(?:hv(?:a)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n178>(?:(?:hva(?:l)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n179>(?:(?:hval(?:s)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n180>(?:(?:(?:l)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n181>(?:(?:l(?:l)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n182>(?:(?:ll(?:e)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n183>(?:(?:lle(?:n)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n184>(?:(?:(?:l)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n185>(?:(?:l(?:p)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n186>(?:(?:lp(?:o)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n187>(?:(?:lpo(?:p)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n188>(?:(?:(?:r)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n189>(?:(?:r(?:p)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n190>(?:(?:rp(?:o)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n191>(?:(?:rpo(?:p)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n192>(?:(?:(?:d)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n193>(?:(?:d(?:e)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n194>(?:(?:de(?:b)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n195>(?:(?:deb(?:u)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n196>(?:(?:debu(?:g)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n197>(?:(?:debug(?:\s)*(?:(?:\s)?)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n198>(?:(?:debug(?:\s){1,}(?:o)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n199>(?:(?:debug(?:\s){1,}o(?:b)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n200>(?:(?:debug(?:\s){1,}ob(?:j)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n201>(?:(?:debug(?:\s){1,}obj(?:e)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n202>(?:(?:debug(?:\s){1,}obje(?:c)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n203>(?:(?:debug(?:\s){1,}objec(?:t)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n204>(?:(?:(?:s)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n205>(?:(?:s(?:c)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n206>(?:(?:sc(?:a)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n207>(?:(?:sca(?:r)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n208>(?:(?:scar(?:d)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n209>(?:(?:(?:s)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n210>(?:(?:s(?:m)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n211>(?:(?:sm(?:e)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n212>(?:(?:sme(?:m)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n213>(?:(?:smem(?:b)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n214>(?:(?:smemb(?:e)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n215>(?:(?:smembe(?:r)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n216>(?:(?:smember(?:s)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n217>(?:(?:(?:z)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n218>(?:(?:z(?:c)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n219>(?:(?:zc(?:a)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n220>(?:(?:zca(?:r)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n221>(?:(?:zcar(?:d)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n222>(?:(?:(?:d)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n223>(?:(?:d(?:e)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n224>(?:(?:de(?:c)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n225>(?:(?:dec(?:r)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n226>(?:(?:(?:g)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n227>(?:(?:g(?:e)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n228>(?:(?:ge(?:t)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n229>(?:(?:(?:i)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n230>(?:(?:i(?:n)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n231>(?:(?:in(?:c)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n232>(?:(?:inc(?:r)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n233>(?:(?:(?:s)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n234>(?:(?:s(?:t)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n235>(?:(?:st(?:r)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n236>(?:(?:str(?:l)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n237>(?:(?:strl(?:e)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n238>(?:(?:strle(?:n)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n239>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s)*(?:(?:\s)?)?))?$ ^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n241>(?:(?:(?:")?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n242>(?:(?:"(?:(?:[^"]|\\"))*?(?:(?:(?:[^"])?)?)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n243>(?:(?:"(?:(?:[^"]|\\"))*?(?:(?:(?:(?:\\)?))?)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n244>(?:(?:"(?:(?:[^"]|\\"))*?(?:(?:(?:\\(?:")?))?)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n245>(?:(?:"(?:(?:[^"]|\\")){0,}?(?:")?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n246>(?:(?:(?:')?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n247>(?:(?:'(?:(?:[^']|\\'))*?(?:(?:(?:[^'])?)?)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n248>(?:(?:'(?:(?:[^']|\\'))*?(?:(?:(?:(?:\\)?))?)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n249>(?:(?:'(?:(?:[^']|\\'))*?(?:(?:(?:\\(?:')?))?)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n250>(?:(?:'(?:(?:[^']|\\')){0,}?(?:')?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n240>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n251>(?:(?:[^\s"])*(?:(?:[^\s"])?)?)?)))?$ ^(?:(?:(?:\s){0,}(?P<n252>(?:CLUSTER(?:\s){1,}KEYSLOT|DUMP|PERSIST|PTTL|TTL|TYPE|HGETALL|HKEYS|HLEN|HVALS|LLEN|LPOP|RPOP|DEBUG(?:\s){1,}OBJECT|SCARD|SMEMBERS|ZCARD|DECR|GET|INCR|STRLEN|cluster(?:\s){1,}keyslot|dump|persist|pttl|ttl|type|hgetall|hkeys|hlen|hvals|llen|lpop|rpop|debug(?:\s){1,}object|scard|smembers|zcard|decr|get|incr|strlen))(?:\s){1,}(?P<n253>(?:"(?:(?:[^"]|\\")){0,}?"|'(?:(?:[^']|\\')){0,}?'|(?:[^\s"]){1,}))(?:\s)*(?:(?:\s)?)?))?$ ^(?:(?:(?:\s)*(?:(?:\s)?)?))?$ ^(?:(?:(?:\s){0,}(?P<n254>(?:(?:(?:C)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n255>(?:(?:C(?:L)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n256>(?:(?:CL(?:I)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n257>(?:(?:CLI(?:E)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n258>(?:(?:CLIE(?:N)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n259>(?:(?:CLIEN(?:T)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n260>(?:(?:CLIENT(?:\s)*(?:(?:\s)?)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n261>(?:(?:CLIENT(?:\s){1,}(?:L)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n262>(?:(?:CLIENT(?:\s){1,}L(?:I)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n263>(?:(?:CLIENT(?:\s){1,}LI(?:S)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n264>(?:(?:CLIENT(?:\s){1,}LIS(?:T)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n265>(?:(?:(?:c)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n266>(?:(?:c(?:l)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n267>(?:(?:cl(?:i)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n268>(?:(?:cli(?:e)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n269>(?:(?:clie(?:n)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n270>(?:(?:clien(?:t)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n271>(?:(?:client(?:\s)*(?:(?:\s)?)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n272>(?:(?:client(?:\s){1,}(?:l)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n273>(?:(?:client(?:\s){1,}l(?:i)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n274>(?:(?:client(?:\s){1,}li(?:s)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n275>(?:(?:client(?:\s){1,}lis(?:t)?))?)))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s)*(?:(?:\s)?)?))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n279>(?:(?:(?:T)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n280>(?:(?:T(?:Y)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n281>(?:(?:TY(?:P)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n282>(?:(?:TYP(?:E)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n283>(?:(?:(?:t)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n284>(?:(?:t(?:y)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n285>(?:(?:ty(?:p)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n286>(?:(?:typ(?:e)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n287>(?:TYPE|type))(?:\s)*(?:(?:\s)?)?))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n289>(?:(?:(?:N)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n290>(?:(?:N(?:O)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n291>(?:(?:NO(?:R)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n292>(?:(?:NOR(?:M)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n293>(?:(?:NORM(?:A)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n294>(?:(?:NORMA(?:L)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n295>(?:(?:(?:M)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n296>(?:(?:M(?:A)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n297>(?:(?:MA(?:S)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n298>(?:(?:MAS(?:T)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n299>(?:(?:MAST(?:E)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n300>(?:(?:MASTE(?:R)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n301>(?:(?:(?:R)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n302>(?:(?:R(?:E)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n303>(?:(?:RE(?:P)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n304>(?:(?:REP(?:L)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n305>(?:(?:REPL(?:I)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n306>(?:(?:REPLI(?:C)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n307>(?:(?:REPLIC(?:A)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n308>(?:(?:(?:P)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n309>(?:(?:P(?:U)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n310>(?:(?:PU(?:B)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n311>(?:(?:PUB(?:S)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n312>(?:(?:PUBS(?:U)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n313>(?:(?:PUBSU(?:B)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n314>(?:(?:(?:n)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n315>(?:(?:n(?:o)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n316>(?:(?:no(?:r)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n317>(?:(?:nor(?:m)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n318>(?:(?:norm(?:a)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n319>(?:(?:norma(?:l)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n320>(?:(?:(?:m)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n321>(?:(?:m(?:a)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n322>(?:(?:ma(?:s)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n323>(?:(?:mas(?:t)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n324>(?:(?:mast(?:e)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n325>(?:(?:maste(?:r)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n326>(?:(?:(?:r)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n327>(?:(?:r(?:e)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n328>(?:(?:re(?:p)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n329>(?:(?:rep(?:l)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n330>(?:(?:repl(?:i)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n331>(?:(?:repli(?:c)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n332>(?:(?:replic(?:a)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n333>(?:(?:(?:p)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n334>(?:(?:p(?:u)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n335>(?:(?:pu(?:b)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n336>(?:(?:pub(?:s)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n337>(?:(?:pubs(?:u)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n276>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n277>(?:TYPE|type))(?:\s){1,}(?P<n278>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){,0}(?:(?:(?:\s){1,}(?P<n288>(?:TYPE|type))(?:\s){1,}(?P<n338>(?:(?:pubsu(?:b)?))?)))?))?$ ^(?:(?:(?:\s){0,}(?P<n339>(?:CLIENT(?:\s){1,}LIST|client(?:\s){1,}list))(?:(?:\s){1,}(?P<n340>(?:TYPE|type))(?:\s){1,}(?P<n341>(?:NORMAL|MASTER|REPLICA|PUBSUB|normal|master|replica|pubsub))){0,1}(?:\s)*(?:(?:\s)?)?))?$ |
这就很恐怖了。
当 IRedis 支持 Redis-server 的 197 个命令语法的时候,需要编译的正则已经达到了 ~8000 个。IRedis 启动的时候需要等待 ~8s 编译正则完成。
这就是问题了。作为一个命令行客户端(对比一下 mysql/redis-cli/mongo 这种客户端),需要等待 8s 才能使用,是非常影响体验的。
缓兵之计:异步线程加载
这个问题没解决之前,我将这些正则的编译改到了一个 daemon 线程中去编译(这个PR)。在编译结束之前,最下方的 bottom-bar 会显示一个 ascii 动画提示正在编译,并且 Lexer 高亮,补全这些功能都没有激活,像一个 redis-cli 那样只有基本的功能。
但是这段时间 CPU 在不停的做正则编译,占用量会很高。以及用户体验也有影响,相比 redis-cli 秒开,太伤了。
如果要从根本上解决这个问题,现在看来有以下几个思路:
- 能否缓存下来正则,不要每次都编译?
- 能不能替换掉编译正则的方案?
- 能否加速正则的编译?
- 减少需要编译的正则的数量;
- 不要一下子编译好所有的正则,用到哪个编译那个。
尝试1:缓存正则
这是一个比较直觉的方案。我尝试过用 pickle/dill (应该还尝试过一个,不过名字忘记了)。发现 dump 出来,下次启动直接 load,从方案上是可行的。但是速度依然很慢。后来发现 pickle 只是去打包一个对象的 __init__ 参数,当 load 的时候,再用类初始化一次(这样对于大部分 pickle 的使用场景来说是合理的)。所以还是相当于编译了一次。(资料)
理论上,直接缓存 C 语言层面的 regex 编译结果也是可行的,但是会遇到 Python 跨版本不兼容的问题,因为这部分并没有公开的 API,所以没有人能保证它的兼容性。
我觉得这将会是一个大坑,所以没有继续沿着这条路走下去了。
尝试2:另寻没有正则的方案
老实说,用正则来处理语法并不是很好。比如 Redis 的命令有一些是下面的这种语法,而这种是无法用正则来表达的:
|
1 |
ZINTERSTORE dest <numkeys> key key ... WEIGHTS ... |
ZINTERSTORE 这个命令 后面有个 numkeys 表示后面紧跟着几个 key,然后再是 WEIGHTS。只有知道了 key 的数量,才不会将 WEIGHT 也作为 一个 key。而正则是不支持从前面解析出来数字然后应用到后面的 match 中的。
于是我想拿 pygments 来做一个基于状态机的 Grammar。参考 这个PR。理论上是可行的,但是并没有最终采用这个方案。原因是工作量太大了。如果我直接用正则,那么我可以用 prompt_toolkit 框架中的一些补全,Lexer。否则的话,我就要重写 Grammar,match 前缀的逻辑,Lexer,判断下一个 token 可能是什么来推测补全列表。相当于另外写一个 prompt_toolkit 了。所以这条路也放弃了。
Jonath(prompt_toolkit的作者)建议过我用状态机实现,这个方案同样也是工作量太大。本来 IRedis 就是因为另一个项目而生的,我不太想因为 IRedis 要先去完成另一外一个新的项目 :)
尝试3:编译更快的正则
这个方案比较好理解,Python 的 re 比较慢,能否用更快的 re 来替换呢。Python monkey patch 比较简单,我只要将系统 buildin 的那个 re 替换掉就好了。大部分其他 re 的库也是兼容 buildin re 的 API的。
我尝试过的库有:
效果不是很好,原因很简单:这些库可能在一些情况下编译正则的速度快一些。但是我这里的问题并不是编译一个正则太慢,而是要编译的正则太多。对于 8000 个正则来说,就算能快上一倍,效果也不明显的。
尝试4:减少编译正则的数量
guyskky 提到可以将正则 merge 一下,类似 werkzeug 处理 URL 的方式(werkzeug.routing.Rule.compile)。我觉得这个比较可行,但是还没有尝试。
但是跟 Jonath 讨论之后,Jonath 开始优化这一块正则的 merge,这个 PR 到我写这篇文章的时候,已经 work 了。
经过优化之后,需要正则的数量降低到了 496 个,1.7s 就可以编译完成。
尝试5:即时编译
上面的方案4是一个治本的方案,但是在我这个方案之前,我并不是方案4是不是可行的(因为对 prompt_toolkit 读的代码不多),所以我上周用“即时编译”的思路进行了重构。
这个想法很简单:既然启动的时候编译那么多正则表达式很慢,那么我为什么要一开始就全部编译好呢?用到哪一个再编译哪一个不就好了吗?
比如用户输入了 KEYS 那么我就编译好 KEYS 的语法,然后将当前的语法替换成这个。当用户输入了 GET,我再编译 GET 的语法并进行替换。
能够这么做基于两点:
- Python 在运行时动态地替换一个对象的属性非常简单,并且我这个 client 也是单线程的,不会存在线程安全问题;
- Redis 的不同命令的语法都是独立的,不像 SQL 那样,你不能只编译一部分。当然,问题的根源也是它。
核心代码是下面这个 Processor,Processor 是框架的一个概念,每次用户按下什么键都会执行。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
class GetCommandProcessor(Processor): """ Update Footer display text while user input. """ def __init__(self, command_holder, session): # processor will call for internal_refresh, when input_text didn't # change, don't run self.session = session self.command_holder = command_holder def apply_transformation( self, transformation_input: TransformationInput ) -> Transformation: input_text = transformation_input.document.text try: command, _ = split_command_args(input_text, all_commands) except InvalidArguments: self.command_holder.command = None self.session.completer = default_completer self.session.lexer = default_lexer else: self.command_holder.command = command.upper() # compile grammar for this command grammar = get_command_grammar(command) lexer = GrammarLexer(grammar, lexers=lexers_mapping) completer = GrammarCompleter(grammar, completer_mapping) self.session.completer = completer self.session.lexer = lexer return Transformation(transformation_input.fragments) |
核心代码是 24-27 行,当用户输入的命令匹配到 Redis 命令了,就替换当前的 Lexer 和 Completer。
这样问题就完美的解决了,当然还有一些细节问题。
比如当用户输入了一个命令语法比较复杂的时候,会感觉到一点卡顿,因为在编译正则。我在编译的函数上加个一个装饰器 @lru_cache(maxsize=256) ,将编译结果直接缓存下来,这样只在第一次输入的时候会卡,后面就好多了。
等 prompt_toolkit 那个 PR 合并,配合我修改的“即时编译”,这个问题就算完美的解决了。
解决这个问题,大概花了 3 个月。但是最终解决的那一刻,感觉真的很奇妙。这件事情给我一些很强烈的感受:
- 编程这件事情本身,我是说就算没有带来任何名誉、财富上的收获,也实在太有意思了;
- Python 社区的人太好了,除了 Jonath 给我很多很多建议,Dbcli 的 amjith 还和我视频通话,跟我说他之前也想做一个 redis 的 cli,跟我说了一些他的想法,非常有用。此外还得到了很多很多其他人的帮助和建议。Python 社区很温暖!
- 用 Python 编程太快乐了!比如本文的 @lru_cache ,这一行能完美解决问题!IRedis 项目中,我遇到了很多类似的体验,我打算单独写一篇文章讨论这个。
Happy hacking!
点赞
你让我发现了原来我的博客有点赞功能!
怒赞!回想起来似乎很显然但是真正能想到确实不容易!想起来哥伦布立鸡蛋的故事……
现在想想,也许这些尝试都不是白费的。这个方案难想出来的点在于,Redis 的每一个命令之间都是不相关的,而我们设计语法的时候总是默认用一个树形来表示(所以叫做语法树),而 Redis 的更像一个 Hash。
Redis我并不懂,但是所有的尝试都绝不是白费的,它们组成了生活本身。(这话说出来太装了,我自己都要吐了)
学习了,没结婚就是好哈,每天可以熬夜
也没有每天都熬,身体也不行 XD
路过帮顶。。希望以后有时间也能为iredis做点贡献。。
解决问题成功的美妙程度不输于来一发。
我咋觉得状态机或许挺不错呢- -,可能就是debug的时候比较痛苦。
还是工作量太大,写起来也比较复杂。不过状态机好处是支持的语法更加灵活,可以做到“完全正确”吧,不像现在有一些文中提到的情况识别不了的。不过我不想花太多的精力在这个项目上面,解决90%的使用场景就够了,剩下10%要花很多精力才能完美,我还是忍一忍……
不是特别能看得懂…太弱了么
Pingback: Flameshow 性能优化小记 | 卡瓦邦噶!