你一定听说过一种加速查询的技术,使得只使用索引就可以得到查询的内容,而“避免回表”,至少应该在别人的面试经验中看过,或者自己面试中被问到过吧。这篇文章是 use the index luke! 中 clusting data 这一章节的笔记,解释了这样做的原理,实践。
- Use the Index, Luke! 笔记1
- Use the Index, Luke! 笔记2 性能、Join操作
- Use the Index, Luke! 笔记3:避免回表
- Use the Index, Luke! 笔记4:sorting 和 grouping
- Use the Index, Luke! 笔记5:查询部分结果
- Use the Index, Luke! 笔记6:增删改的索引
Data Cluster
Data Cluster 的意思是将连续的,相关的数据尽量存储在一起,这样查找的时候 IO 的成本更低,因为顺序读比随机读速度快,磁头移动少。我们的索引也有这样的功能,帮我们安排数据的顺序,让读的速度更快。
我们通过索引可以达到这一目的。之前,我们介绍过通过执行计划的 filter 可以推测出哪些索引创建的不合理,因为 filter 是一个遍历操作,速度很慢,access 的速度很快。其实,filter 的信息信息很有用,还能帮助我们将数据聚集,来加速查询。
索引的第一大能力是 B-Tree 比那里,第二大能力就是数据聚集。
比如下面这个查询:
|
1 2 3 4 |
SELECT first_name, last_name, subsidiary_id, phone_number FROM employees WHERE subsidiary_id = ? AND UPPER(last_name) LIKE '%INA%' |
因为 LIKE 条件是以 % 开头的,所以无论是对 last_name 建立索引还是对 UPPER(last_name) 建立索引,查询都不会用到。
所以,这个查询的瓶颈在于,按照 subsidiary_id 过滤之后,找到符合 LIKE 条件的 row。这一步的流程是这样:取出一个 row,判断它的属性是否满足条件,然后再去取出下一个 row,再判断。对于这样的操作,如果 row 分散在不同的 block 上的话,一个一个取出来读的话,性能是很差的。如果这些 row 能尽量在同一个 block 上,或者相邻的 block 上,读起来就会快很多了。
有一种方式是将 row 按照索引查找的顺序排序,这样就可以将 filter 的这个操作从随机读,变成顺序读了。但是这样会影响整个表的顺序,只能根据一个索引优化,如果出现另一个查询,就无法根据另一个查询重新设定 row 的顺序了。并且数据库提供的这种 “row sequencing” 的技术和工具都颇为古老,很少使用。
更实用的一个解决方案是将 last_name 也放到索引中。这样就相当于将要查找的 column 放到了一起,我们遍历索引的时候,直接可以得到 last_name 这一利,不需要根据索引读出来 row 再进行判断。这时候索引中 last_name 这个数据不再是提供遍历树的索引功能,而是提供查询功能。
|
1 2 |
CREATE INDEX empsubupnam ON employees (subsidiary_id, UPPER(last_name)) |
在执行计划中,可以看到 filter 这一步的成本显著降低。因为我们不需要去读表中的数据了,在索引的数据中就可以完成 access,判断是否符合 LIKE 这两步操作。
Covering Index
如果一个索引,能使一次查询避免 table access,那么这个索引就叫做 covering index.
比如我们建立下面这个索引:
|
1 2 3 |
CREATE INDEX sales_sub_eur ON sales ( subsidiary_id, eur_value ) |
那么这个查询就不需要 table access:
|
1 2 3 |
SELECT SUM(eur_value) FROM sales WHERE subsidiary_id = ? |
因为索引中已经有一份 eur_value 的 copy 了。Oracle 中的执行计划如下:
|
1 2 3 4 5 6 7 8 9 10 11 |
---------------------------------------------------------- | Id | Operation | Name | Rows | Cost | ---------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 104 | | 1 | SORT AGGREGATE | | 1 | | |* 2 | INDEX RANGE SCAN| SALES_SUB_EUR | 40388 | 104 | ---------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("SUBSIDIARY_ID"=TO_NUMBER(:A)) |
执行计划中的 INDEX ONLY SCAN 极大地提高了性能,执行计划说一共要聚合 40388 行,假如不是 INDEX ONLY SCAN 的话,这意味着数据库要读 40388(最多,如果这些 row 都没有在同一个 block 的话)次。
INDEX ONLY SCAN 是一种非常激进的优化策略,潜在的增加了数据的维护成本。比如会降低 update 操作的速度。使用 INDEX ONLY SCAN 需要三思。
另外,INDEX ONLY SCAN 也会带来潜在的性能问题。比如下面这个查询:
|
1 2 3 4 |
SELECT SUM(eur_value) FROM sales WHERE subsidiary_id = ? AND sale_date > ? |
假如一个同事写了这样的查询,认为这个查询查到的 row 更少,理应更快才是。
但实际上却不是的,这个查询增加了一个不在索引中的 row,原来不需要 table access 的,现在需要了。所以查询的速度会慢很多。
Oracle 的查询计划:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
-------------------------------------------------------------- |Id | Operation | Name | Rows |Cost | -------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 371 | | 1 | SORT AGGREGATE | | 1 | | |*2 | TABLE ACCESS BY INDEX ROWID| SALES | 2019 | 371 | |*3 | INDEX RANGE SCAN | SALES_DATE| 10541 | 30 | -------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - filter("SUBSIDIARY_ID"=TO_NUMBER(:A)) 3 - access("SALE_DATE">:B) |
在无法使用 INDEX ONLY SCAN 的时候,优化器会选择第二优的执行计划。在这个例子中,选择了 SALE_DATE 这个索引。这里的选择原因有2:1)通过 sale_date 过滤出来的 row 更少,执行计划显示是 ~10000 行,而上面的 subsidiary_id 有 ~40000 行。2)sale_date 这个索引,数据更加聚集。因为订单创建的顺序和时间是相关的,都是 append 在最后面。这可以可以看出,有些索引“自然”具有 cluster 的性质。
这个例子中使用 sale_date 这个索引正好是一个巧合,虽然它让 INDEX ONLY SCAN 失效了,但是使用它的这个索引,聚集效果也是很好的。但是通常,给 select 添加查询条件会导致聚集很差的查询路径,所以记得用 comment 或者其他的形式,来提醒自己这里的查询是一个 INDEX ONLY SCAN。避免后来添加查询条件导致性能急剧下降。
另外要格外注意,很多数据库多索引大小是有限制的。比如 Postgres 数据库,从 9.2 开始支持 index-only scans,B-Tree Entry 最大为 2137 bytes(硬编码)。如果插入或更新的时候超过了这个大小,会得到错误 “index row size … exceeds btree maximum, 2713” ,B-Tree 索引最多有 32 列。
Clustered Index
由上面一小节自然而然就会想到:那我们可以将整个表都保存在索引中吗?这样都不用回表查询了。答案是可以的。Oracle 将这种所有的数据都在索引中的形式,叫做 index-organized tables (IOT),名字很好的反应了它表达的意思,即表是完全按照索引组织的。另一些数据库将这个术语叫做 clustered index. 其实他们都是一回事。
简单说,clustered index 就是 B-Tree 索引中保存了所有数据,没有 heap table。
这样有两个好处:
- 省掉了表的空间,即 heap 的空间,因为所有的数据都在索引中;
- 每次查询都不需要回表操作,所有的查询都是 index-only scan;
坏处也显而易见:
因为 row 都是按照索引来组织的,所以 row 的顺序(物理位置)无法固定。正常情况下,我们在 heap table 中保存 row 的时候,我们随便找到一个空的地方保存下来就好了,然后在索引中更新 ROWID 的位置。这个 row 一旦保存好了,它的物理位置永远不会变了,我们只会更新索引中这个 ROWID 的位置。
然而这在 clusted index 中是无法做到的,因为 row 的顺序是按照索引来组织的,一个 row 的位置无法固定。一个 row 即使没有更新它,添加新的 row 的时候,它的位置也可能受到影响,跟着索引移动。
这是根本问题,导致的表面问题是什么呢?
假如我们现在有第二个查询语句,不是根据主索引来的(secondary index),按照有 heap table 的情况下,我们是这么查询的:先在 secondary index 中找到 ROWID 的位置,然后去 heap table 中找到这个 ROW。
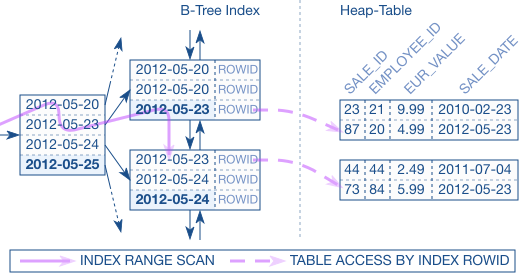
但是在 clustered index 中,我们没有 ROWID,只有主索引,所以必须在 secondary index 中找到主索引,然后再去主索引中查找这个 row 的位置。
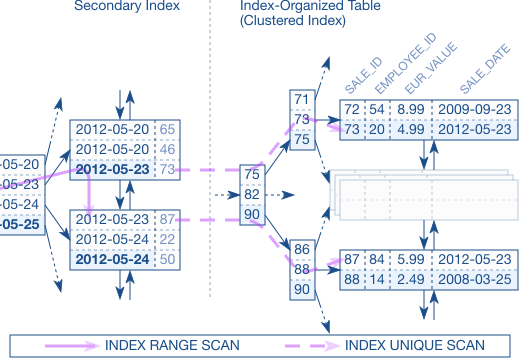
clustered index 中的这个查询(文中第二个)比 heap table 查询要慢很多,因为第一个查询是 INDEX RANGE SCAN + TABLE ACCESS 的操作,第二个操作需要经过两个索引,INDEX RANGE SCAN + INDEX UNIQUE SCAN 的操作。
当然,对于这个查询,其实可以针对 secondary index 再建立一个 index-only scan,这样针对这个查询又避免了回表操作。比起上面两个查询都是最优的。
总的来讲,clustering index 并不实用,clustering index 的 key 也比 ROWID 要长很多,所以占用更多的空间,适用场景非常有限。
如果 table 能确定,查询总是按照一个顺序的,绝对不会需要 secondary index 的话,可以考虑使用这种索引。
另外,不同的数据库对 index-organized tables 的支持差异很多。PG 不支持没有 heap table,但是可以用 CLUSTER 来将整个 table 放到 index 中。
我最近正好也在看数据库,看的是《高性能 Mysql 》这本书。Mysql 的 InnoDB 用的就是聚簇索引。所以怎么理解文章的这句话:
“总的来讲,clustering index 并不实用,clustering index 的 key 也比 ROWID 要长很多,所以占用更多的空间,适用场景非常有限”
这本书我也打算看来着。
聚簇索引如果和我读的 clusering index 一样的话,那么这句话应该表达的是 “InnoDB 对主键建立的索引是聚簇索引”,这样的话想想应该问题不大。
“clustering index 的 key 也比 ROWID 要长很多” 是因为如果是非主键的聚簇索引的话,比如 DATE+SUBID,那么即使是以 NAME 查找,找到之后也必须按照 DATE+SUBID 从聚簇索引中找到真实的数据。但是如果聚簇索引是 ROW ID 的话,就不会有额外的空间了。这也是按照 Secondary index 查两次会慢的原因。但是如果查的第二次是 ROWID 的话,应该不会至于慢。
我也没仔细研究,看完这个书我也去看看高性能 MySQL :)
我一开始把你的文章默认当成 clustered index 是在主键上了,所以看到说这种情况不实用的时候,以为自己的理解有问题。但是你图中给的就是在主键上的二级索引查找情况吧?
是的。我也有点迷糊了,innodb 默认对主键建立聚簇索引的话,那像图中这种情况,按照我读的资料, secondary index 查找会慢才对啊,不知道它怎么处理的。我去研究一下。use the index luke 没有怎么讲 MySQL,感觉他对 Oracle 比较擅长。
我昨天重写看了下,mysql InnoDB有个自适应哈希索引。二级索引这种情况,多次访问会自动建立哈希索引直接指向数据的地址,不用再次在主键上查找。
Cool 相当于缓存了。这样的话,一般主键也都是连续递增的,即使是聚簇索引,那也都是顺序写。innodb 这么做我也想不到啥弊端了,应该也是挺好的。