排序和分组是非常耗费 CPU 和内存的一项操作。因为需要内存来放排序的中间结果,排序算法一般也都是 O(n*log(n)) 的复杂度。好在使用索引我们也可以优化这一项操作。原理非常简单:假如结果已经是排好序的,那么我们查出来结果之后就不需要额外的排序操作了。
- Use the Index, Luke! 笔记1
- Use the Index, Luke! 笔记2 性能、Join操作
- Use the Index, Luke! 笔记3:避免回表
- Use the Index, Luke! 笔记4:sorting 和 grouping
- Use the Index, Luke! 笔记5:查询部分结果
- Use the Index, Luke! 笔记6:增删改的索引
如何使排序命中索引
要避免排序操作,我们需要索引 cover ORDER BY 的部分。原理很简单,如果 order by 中有一部分没有在索引里面,那么我们就无法保证查出来的内容是按照索引排好序的,所以还要再对这个结果排序一遍。
比如下面这个查询,因为 product_id 不在索引里面,所以执行计划中会有排序的操作。
SELECT sale_date, product_id, quantity FROM sales WHERE sale_date = TRUNC(sysdate) - INTERVAL '1' DAY ORDER BY sale_date, product_id
--------------------------------------------------------------- |Id | Operation | Name | Rows | Cost | --------------------------------------------------------------- | 0 | SELECT STATEMENT | | 320 | 18 | | 1 | SORT ORDER BY | | 320 | 18 | | 2 | TABLE ACCESS BY INDEX ROWID| SALES | 320 | 17 | |*3 | INDEX RANGE SCAN | SALES_DATE | 320 | 3 | ---------------------------------------------------------------
假如我们再建立一个索引,覆盖住 product_id:
CREATE INDEX sales_dt_pr ON sales (sale_date, product_id)
那么排序这一步,就会从查询计划中消失了。因为结果本身一定是排好序的。
--------------------------------------------------------------- |Id | Operation | Name | Rows | Cost | --------------------------------------------------------------- | 0 | SELECT STATEMENT | | 320 | 300 | | 1 | TABLE ACCESS BY INDEX ROWID| SALES | 320 | 300 | |*2 | INDEX RANGE SCAN | SALES_DT_PR | 320 | 4 | ---------------------------------------------------------------
P.S. TABLE ACCESS 这一行,第二个执行计划的 Cost 比前一个执行计划高了,是因为新的索引的聚簇效果更差了(上一篇笔记有提到过有关聚簇的知识)。为什么呢?拿 Oracle 来讲,当索引中两条数据的值相等的时候,Oracle 会自动把 ROWID 给加到索引里面去,这样一来索引的顺序和表中数据的顺序是一样的,就有了很好的聚簇效果 (clustering factor). 但是当我们往索引中添加新的一列的时候,留给数据库这种分配索引顺序的自由就更小了,所以只会让 clustering factor 变得更差。由此一来,数据库本来在聚簇效果很好的时候,可以顺序读 table 的 block,现在不能顺序读了,可能会 access 同一个 block 很多次。但是如果是同一个 block 的话,数据库会读缓存中的 block。因此,由于缓存带来的优势,使得我们实际上给这个索引增加一列造成的性能损失,是比执行计划分析出来的,要小的。
很显然,因为联合索引是在左列的值相等的时候,按照右列的值排序的。所以在左列的值相等的情况下,我们针对右边来 order by 查询,也是可以走索引的:
|
1 2 3 4 |
SELECT sale_date, product_id, quantity FROM sales WHERE sale_date = TRUNC(sysdate) - INTERVAL '1' DAY ORDER BY product_id |
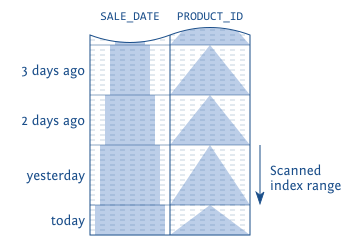
但是,如果左侧的值横跨两个的话,就无法使用索引了:
|
1 2 3 4 |
SELECT sale_date, product_id, quantity FROM sales WHERE sale_date >= TRUNC(sysdate) - INTERVAL '1' DAY ORDER BY product_id |
除了索引的顺序和 order by 的顺序不搭(上面这个例子),即使有索引,也有可能走扫表的情况,这种情况可能就是优化器认为每次从索引查到 ROWID 再回表,不如直接扫表来的快了。
升降序的问题
数据库是双向读索引的。也就是说,如果 order by 的 column 顺序和建立索引的顺序完全反向,那么也可以走索引查询。
比如下面这个查询,跟上面的查询顺序完全相反,那么也可以走索引:
|
1 2 3 4 |
SELECT sale_date, product_id, quantity FROM sales WHERE sale_date >= TRUNC(sysdate) - INTERVAL '1' DAY ORDER BY sale_date DESC, product_id DESC |
查询计划不会显示需要索引:
--------------------------------------------------------------- |Id |Operation | Name | Rows | Cost | --------------------------------------------------------------- | 0 |SELECT STATEMENT | | 320 | 300 | | 1 | TABLE ACCESS BY INDEX ROWID | SALES | 320 | 300 | |*2 | INDEX RANGE SCAN DESCENDING| SALES_DT_PR | 320 | 4 | ---------------------------------------------------------------
因为数据库是以双向链表保存索引的,所以可以以完全相反的顺序查询。
为什么要强调是完全相反呢?
考虑下面这个查询,一个是索引中的 ASC,另一个条件是 DESC。
SELECT sale_date, product_id, quantity FROM sales WHERE sale_date >= TRUNC(sysdate) - INTERVAL '1' DAY ORDER BY sale_date ASC, product_id DESC
这样实际在走索引的时候,需要“跳跃”,而这对于索引的数据结构是办不到的。
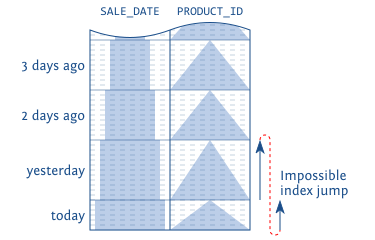
要想优化这个查询,只能重新按照 ASC DESC 的顺序再建立索引:
DROP INDEX sales_dt_pr
CREATE INDEX sales_dt_pr
ON sales (sale_date ASC, product_id DESC)
同理,新的索引建立之后,用前者 DESC,后者 ASC来查询,也是“完全相反”的顺序的,也可以走到这个索引。
Group By
SQL 数据库有两种算法来完成 group by:
- Hash算法,将所有的记录放到内存中临时的一个 Hash 表中,扫完所有记录,返回 hash 表;
- 排序-分组算法:先将所有的记录排好序,然后遍历一遍一组一组返回;
两种算法都要求有一个中间状态,并且不支持 pipeline 操作,必须全部计算完成才能返回。
但是利用前文提到的索引技术也能优化这种场景。比如下面这个查询,就可以命中索引,不需要排序,直接分组返回:
SELECT product_id, sum(eur_value) FROM sales WHERE sale_date = TRUNC(sysdate) - INTERVAL '1' DAY GROUP BY product_id
查询计划显示不需要排序(BY NOSORT):
--------------------------------------------------------------- |Id |Operation | Name | Rows | Cost | --------------------------------------------------------------- | 0 |SELECT STATEMENT | | 17 | 192 | | 1 | SORT GROUP BY NOSORT | | 17 | 192 | | 2 | TABLE ACCESS BY INDEX ROWID| SALES | 321 | 192 | |*3 | INDEX RANGE SCAN | SALES_DT_PR | 321 | 3 | ---------------------------------------------------------------
需要命中索引的条件和 order by 一样,顺序必须和建立索引的顺序完全一致或者完全相反,只不过 ASC DESC 对于 group by 来说,是无所谓的。
对顺序的要求非常合理,比如我们这个查询,过去 24 小时的销售量,按照第二列索引来 group by,那么又要“跳索引”了,这是不可能的:
|
1 2 3 4 |
SELECT product_id, sum(eur_value) FROM sales WHERE sale_date >= TRUNC(sysdate) - INTERVAL '1' DAY GROUP BY product_id |
这种情况下比如使用非 pipeline 的操作,来 group by 数据。
这种情况下,Oracle 选择的是 hash 算法,因为 hash 只需要一种中间数据,节省了排序算法分组返回时所需要的内存。
索引使得 order by 能够执行的更快之外,另外的一大好处是 pipeline,这使得我们不必处理完所有的数据就可以得到前几个结果,在只需要头部数据的时候非常有用。下一篇博客再讲。
ORDER BY product_id 这段 SQL 有额外的 HTML b 标记
谢谢,已经改正。