前面我们讨论的都是查询语言,但是 SQL 不仅仅是查询,还需要修改数据。索引是完全冗余的数据,是用空间换时间的一种形式。对于修改数据来说,这就意味着不仅要修改表中的数据,还要修改索引中的数据,索引对修改数据来说会带来负面的性能影响。
- Use the Index, Luke! 笔记1
- Use the Index, Luke! 笔记2 性能、Join操作
- Use the Index, Luke! 笔记3:避免回表
- Use the Index, Luke! 笔记4:sorting 和 grouping
- Use the Index, Luke! 笔记5:查询部分结果
- Use the Index, Luke! 笔记6:增删改的索引
Insert
Insert 语句几乎是唯一无法从索引获益的语句,因为 insert 没有 where 条件。
索引越多,insert 执行的就越慢。
在表中添加一条记录的过程如下:首先,在数据库中找一个地方放这条记录。在一般的 heap table 中,没有对 row 的顺序的要求,所以随便找一个空闲的 table block 放就可以了。基本上都是顺序写,速度很快。
但是如果有索引的话,必须要保证在索引中能找到这条数据,所以也要在索引中添加这条数据。
索引中的数据都是有顺序的,并且还要保证索引的 BTree 添加了这条记录之后还是平衡的。这个操作就慢很多。虽然数据库的索引本身可以帮助这个过程快速的找到这个记录所在的 block 位置,但是依然要查几(1-4)个block。
找到这个 block 之后,数据库需要确认这个 block 现在是否有足够的空间放这个记录,如果没有的话,就要将叶子节点分裂,将当前 block 的记录平均分在新老的叶子节点中,保持树的平衡。最糟糕的情况下,如果父节点这个时候也同时满了,就需要再来一次分裂。
下图是没有索引到有5个索引的情况下,插入的性能:
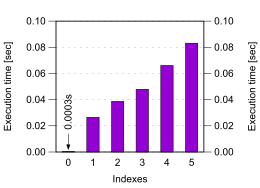 可以看到,在第一个索引出现的时候,性能相比没有索引下降了上千倍。随着索引的增加,性能在不断的下降。所以尽可能的复用索引也很重要。
可以看到,在第一个索引出现的时候,性能相比没有索引下降了上千倍。随着索引的增加,性能在不断的下降。所以尽可能的复用索引也很重要。
那么什么索引都不建的情况下不是插入很快吗?但是没有是索引的话,这些数据几乎没办法使用,也就没什么价值了。即使 write-only log 表也有一个主键索引。
但是有一种情况,就是从其他的 SQL 系统 load 大量的数据的时候,暂时 drop 掉索引是一个加速数据加载的好方法。数据仓库里面这样操作比较常见。
Delete
Delete 可以受益于索引了,因为 delete 可以有 where 语句。所以我们在前文中讨论过的使用索引的场景,同样适用于 delete。(基本上就是索引可以用于 select 的地方都可以用于 delete)
找到了要删除的数据之后,就可以从 table 中删除这条数据,同 insert 一样,在 table 中删除之后,还要在 BTree 索引中执行删除。这一步操作和 insert 是一样的,在索引中删除之后可能要设计叶子节点的合并,是比较耗时的。所以随着索引越多,性能下降的跟上面 insert 那个图差不多。
Update
Update 操作同样需要更新索引,所以跟上 insert delete 差不多。
有一点不同的是,update 可能更多多列,可能更新一列,更新的列数更多,涉及需要更新的索引就越多。
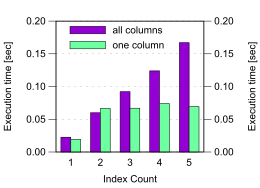 显然,如果一列数据没有变,那我们就最好不要更新它。
显然,如果一列数据没有变,那我们就最好不要更新它。
这句话看起来是废话,但是很多 ORM 的 save() 操作,每次都会更新所有的属性的。比如 Hibernate,只有显示地关闭 dynamicUpdate 才不会每次都去更新。这一点格外重要。
一个保险的办法是在开发的时候打开 ORM 的真正执行的 SQL 日志,进行审计。