这篇文章是我读 https://use-the-index-luke.com/ 第一章的笔记。这对开发者来说是一本不错的教材,读起来也非常轻松,在捕蛇者说的节目中也推荐过。我阅读的时候会做一些简略的笔记,逐步分享在博客上。
SQL 写起来就像英语(比 Python 更像)。SQL 只要求你描述你想要的数据,而不要求你关心数据库如何把这些数据库查出来。在这方面,这个语言的抽象很好。但是涉及到性能,这种抽象就不完美了。写 SQL 的人必须了解一些数据库的工作原理才能写出性能比较好的 SQL 语句。
影响数据库性能最关键的因素是数据库的索引,而要建立合适的索引,不是运维或者 DBA 的职责,而是开发者的。因为建立索引需要的最关键的信息是查数据的“路径”,这些信息正好开发是最熟悉的。
这本书就是面向开发的索引教程。不涉及其他数据库的复杂知识。
这一系列的笔记一共 6 篇,第一篇写了基本的原理,后面的内容基本都是基于第一篇的原理的,聪明的人应该可以通过索引的原理推理出来后面的内容,以及那么做的道理。第2篇性能和 Join,第4篇 sort group,第5篇部分查询以及第6篇DML,都很简单,基本上让你实现一个数据库你也会直觉地那么选择。第3篇非常有技巧性,不可错过。英语水平足够好可以直接阅读原文,只想看一些可以 take away 的知识的话我觉得我整理的笔记也可以。我删去了我觉得的一些比较啰嗦的解释,如果看不懂的话,可能还是需要回去读原文:)
最后,我也是一遍学习一遍记的,如果有不懂的,或者文中有错误,欢迎留言交流。
- Use the Index, Luke! 笔记1
- Use the Index, Luke! 笔记2 性能、Join操作
- Use the Index, Luke! 笔记3:避免回表
- Use the Index, Luke! 笔记4:sorting 和 grouping
- Use the Index, Luke! 笔记5:查询部分结果
- Use the Index, Luke! 笔记6:增删改的索引
1. 索引
索引在数据库中,跟 table 中的数据是分开的,重复的数据。假如删掉索引,也不会丢失任何数据。类似一些专业书籍最后面的名词索引,会单独占用很多页,但是没有额外的信息,只是加速读者的查阅速度。
但是索引还要比“附录”复杂的多,因为附录不需要更新,只需要下一次印刷重新排版就好了。但是索引要面临和数据共同更新、增加、删除,并且保持一致。还需要解决中间部分的空间放不下新的索引的问题。
数据库一般结合两种数据结构:双向链表,加一个树,来解决这个问题。
索引要解决的根本问题是,提供一种有序的数据,这样查找起来更快。
如果使用连续的数组的话,那么插入数据的时候,需要顺序移动后面所有的元素。太慢了,这是无法接受的。所以这里数据库维护的是一个“逻辑顺序”。实际存储的索引在内存中并不是连续的,但是一个节点指向下一个节点,保持了一个逻辑上的顺序。
每个节点都保存了上一个节点和下一个节点的位置,这样数据库可以向前或向后查找。这个数据结构叫做双向链表(doubly linked list)这样每次插入和更新数据的时候,只要修改前后节点的指向就好了。
数据库将这些节点存放在文件系统的 block 中,这也是文件系统读写的最小单位。在一个 block 中存储尽可能多的 block。这样,索引就有两层,要找一个特定的索引,首先要找到它在哪个 block,然后读出来这个 block,找到这个 block 中的索引。
B-Tree(省略)
这部分对我是已知内容,所以忽略了,读者如果有兴趣可以去搜索一下相关的资料,比较丰富的。
2. 使用索引也可能很慢
即使使用索引,也可能查询很慢。有些人说重建索引可以解决问题,但长期来看并没有用。为什么使用了索引还可能很慢呢?原因有以下几点:
- 存在多个相同的值。这个时候会有多个 B-Tree 的叶子节点是相等的,为了确保找到其他叶子节点符合查询条件的数据,还要遍历把这些叶子节点都遍历一遍。所以除了 Tree 遍历的时间,还有顺着叶子节点找到最终的叶子节点的时间;
- 找到索引之后,还要去表中查找数据。这些数据散落在磁盘的不同地方,读比较耗时;
所以通过索引查找数据实际上是分 3 步:
- 遍历树;
- 顺着命中的叶子节点找相邻的叶子节点;
- 拿到索引中保存的数据的问题,读数据;
很多人认为,如果命中索引,查询还很慢,一定是由于索引腐坏了。实际上不是这样的。
甚至有时候,命中索引的情况可能比 TABLE SCAN 还要慢。举个例子,假如有一个人名的数据库,对 Lastname 建立索引,但是 Lastname 相同的人很多。在下面这个 SQL 中,TABLE SCAN 可能比按照索引查询还要快。
|
1 2 3 |
SELECT address FROM people WHERE lastname = "Pinkman" and firstname = "Jesse"; |
因为在索引查找的过程中,虽然 Tree 遍历很快,但是还要遍历一个 Linked List,找到所有的符合 lastname = "Pinkman" 的数据,然后将这些 ROW 全部都读出来,依次判断它们是否符合另一个条件 firstname = "Jesse"。相比于 TABLE SCAN,这两个操作都很耗时,而且 TABLE SCAN 虽然扫的数据量要大一些,但它是顺序读的,硬盘顺序读更快,而且可以利用一些 Kernel 的 read ahead 的技术。注意 TABLE SCAN 比 INDEX RANGE SCAN 快的条件并不是数据量有多少,而是索引中相等的值有多少。
很多数据库提供命令,可以查看索引的使用方式。比如 Oracle:
- INDEX UNIQUE SCAN:只遍历数,用于检查数据是否已经存在;
- INDEX RANGE SCAN:遍历树+遍历相邻叶子节点;
- TABLE ACCESS BY INDEX ROWID:根据索引中的
ROWID读出数据(完整的3步)。
3. 什么时候会使用索引
当使用 INDEX UNIQUE SCAN 的时候,一般不会出现 slow query。因为要找的数据只会命中一条,不会需要遍历叶子节点,Table Access 也只需要一次。
串联索引(Concatenated Indexes,某些地方可能翻译成联合索引,但是联合这个词丢失了“必须按顺序”这个关键的信息,所以 Concatenated Index 这个词可能比 esmulti-column, composite or combined index 更合适)
如果一个索引有相同的值,那么如果要作为主键的话,就要和其他列一起,作为串联索引了。
什么时候会通过串联索引查询,什么时候不会,这个细节必须要明白。
串联索引也只是一个索引,以两列的串联索引为例,与单列索引不同的是,如果第一列的值相同,就会使用第二列索引排列这些第一列相同的索引。类似于一本书的目录同一个章节下的小结。你可以按照章节、小结两列一起搜索,也可以搜索某一章的所有小结。但是不能在没有章节的情况下直接搜索小结。即,不能使用串联索引后面的列进行搜索。这样不会走到串联索引,而是会扫全表。
所以在建立索引的时候要根据查询场景,建立联合索引的时候,列的顺序很重要,将需要单独查询的 Column 放到前面。
同样的,如果建立 3 列的串联索引,那么以下三种情况可以走索引,其他的不可以:
- 根据第一列查询;
- 根据第一列和第二列查询;
- 根据三列查询;
虽然串联索引可以带来更好的性能,但是第一列重复数据不多的情况下,尽可能使用单列的索引。因为这样可以1)节省空间;2)使数据的增加,修改,删除更快。因为索引也需要空间来存储,并且每次数据更新都需要更新索引。
但是,并不一定是有索引可用,就会用。上面我们说过,在某些情况下,使用索引可能要比不使用索引更慢。
数据库会有一个专门的组件,叫做“优化器”,当有很多选择的时候,优化器会决定选择哪一种。优化器有两种,一种给所有的可用查询方案进行评分(Cost-based optimizers, CBO);另一种通过固定的、提前设定的规则决定使用哪种方案(Rule-based optimizers, RBO)。第二种不灵活,很少用了。在前面提到的这种 TABLE SCAN 可能比 INDEX RANGE SCAN 更快的情况,优化器会使用表的统计数据(关键的数据比如 row 的量级,index tree 的深度等),来决定方案。如果在某种情况下没有统计数据的话,优化器会使用默认数据。如果提供了准确的统计数据,优化器通常会工作的很好。Oracle 数据库在新建索引之后,不会自动更新统计数据,最好手动更新一下。
4. 口吞玻璃而不伤身体
使用索引可以提高查询速度,但是有一些限制,比如必须大小写准确。
这里提供一种既可以使用索引,又可以大小写不敏感的方法。
数据库之所以无法使用索引,是因为如下的查询函数对它来说是和黑盒。
|
1 2 3 |
SELECT first_name, last_name, phone_number FROM employees WHERE UPPER(last_name) = UPPER('winand') |
它看到的是这样:
|
1 2 3 |
SELECT first_name, last_name, phone_number FROM employees WHERE BLACKBOX(...) = 'WINAND' |
而且它的索引是基于比较字符串建立的大小写敏感的索引,所以无法在索引树中进行忽略大小写的遍历。
解决方法非常简单,我们建立索引的时候,使用大写简历索引即可。这种索引叫做基于函数的索引,function-based index (FBI).
|
1 2 |
CREATE INDEX emp_up_name ON employees (UPPER(last_name)) |
如果优化器发现索引的字段一模一样的出现在了查询语句中,就会使用索引。
MySQL 和 SQL Server 不支持 FBI,但是有另一种方法,就是增加一个字段,对这个字段建索引。
|
1 2 3 4 |
ALTER TABLE employees ADD COLUMN last_name_up VARCHAR(255) AS (UPPER(last_name)); CREATE INDEX emp_up_name ON employees (last_name_up); |
除了 UPPER 这种函数,你还可以使用其他的函数建索引,甚至可以使用用户自己定义的函数。但是通过 FBI 的原理,很显然可以联想到,你所使用的函数必须在任何情况下执行都得到相同的结果。因为 FBI 的原理不过是用同样的函数处理查询条件,和索引数据,相当于基于一个 mapping 索引了 mapping 之后的数据。下面是一个反例,其余用一个用了外部变量(时间)的函数做 FBI。
|
1 2 3 4 5 6 7 |
CREATE FUNCTION get_age(date_of_birth DATE) RETURN NUMBER AS BEGIN RETURN TRUNC(MONTHS_BETWEEN(SYSDATE, date_of_birth)/12); END |
这样的问题是,随着时间增加,人的年龄会变,但是索引好的数据不会变。
|
1 2 3 |
SELECT first_name, last_name, get_age(date_of_birth) FROM employees WHERE get_age(date_of_birth) = 42 |
数据最终会腐烂。
不要 Over indexing!
第一次听说 FBI 的人,可能倾向于索引 Everything。每一个索引都不是零成本的,都需要维护。尽量优化索引和查询路径,使一种索引能够尽可能用于很多查询。
5. Parameterized Queries
这个东西简单来说,就是我们在执行 SQL 的时候,我们并不是直接告诉数据库我们要执行的 SQL。而是先告诉数据库我们要执行的语句是什么,再告诉数据库这个语句中某些变量是什么。一般 ORM 会这么做,因为 ORM 都是在执行相同的 SQL 语句,只不过每次执行的语句中的一些变量不同。
比如下面这个例子:
|
1 2 3 4 5 6 7 |
int subsidiary_id; PreparedStatement command = connection.prepareStatement( "select first_name, last_name" + " from employees" + " where subsidiary_id = ?" ); command.setInt(1, subsidiary_id); |
我们告诉数据库 Statement 是什么,但是里面有一个 ? 作为占位符(也可以是其他的字符)。然后再通过一个函数告诉它每一个位置的 ? 分别是什么。
这么做有两个好处:
- 防止 SQL 注入。你无法使用一个 ; 结束当前的 SQL 然后再插入恶意的 SQL,无论这个地方填上什么都会作为一个“参数”;
- 加速选择执行方案。如果每次都是执行相同的语句,只是中间有一些值不同。那么数据库每次都会选择相同的执行方案,这节省了每次都要选择执行方案的时间;
但是这也不是完全免费的。前面说过有些情况下,使用索引可能更慢。要选择最佳的执行计划,需要根据表中重复数据的分布决定。如果使用 Bind parameters 的话,因为数据库是根据 ? 占位符的 SQL 语句来选择执行计划的,考虑下面这样的 SQL:
|
1 2 3 |
SELECT first_name, last_name FROM employees WHERE subsidiary_id = ? |
如果 subsidiary_id 重复的很多的话,使用 TABLE SCAN 会快一些,如果重复很少的话,使用索引会快一些。这个时候数据库并不知道这个 ? 会是什么,也就无法选择执行计划。这时数据库会假设这个分布是均匀的,每次通过索引会得到相同数量的 ROW,从而选择一种查询计划。
和编译器类比的话,bind variables 就像是代码中的变量,直接写的 SQL 就像是常量。编译器可以对常量进行优化,甚至在编译的时候将它们计算好。但是变量,直到程序运行之后,编译器都不知道这个值是什么,也就无法做针对的优化。
简单来说,对一个 SQL 语句使用固定的查询计划可以减少评估查询计划的时间。对每个 SQL 都评估查询计划,可以总是使用最优的查询计划。举个例子,TODO List 中,大部分数据都是 Done 的状态,小部分数据是 Todo 的状态。所以查找 Done 的数据用 TABLE SCAN,查询 Todo 的数据使用索引,是比较合适的。所以开发者应该是最了解数据获取方式的角色。
6. Range 查找
上文中已经提到,INDEX RANGE SCAN 的瓶颈在于要遍历叶子节点,要提高性能,就要让需要遍历的叶子节点越少越好。即索引中相等的值越少越好。
考虑下面的 SQL:
|
1 2 3 4 5 |
SELECT first_name, last_name, date_of_birth FROM employees WHERE date_of_birth >= TO_DATE(?, 'YYYY-MM-DD') AND date_of_birth <= TO_DATE(?, 'YYYY-MM-DD') AND subsidiary_id = ? |
假设我们对搜索的这两列( date_of_birth & subsidiary_id )建立索引的话,怎么建才能让查询更快呢?
这里的顺序很重要。假如是 date_of_birth & subsidiary_id 这样的顺序的话,那么查询先使用第一列 date_of_birth 的索引过滤出来一些 ROW,然后再这些 ROW 中寻找合适的 subsidiary_id。这个时候,第二列 subsidiary_id 是无法用上的,因为我们前面已经说过,只有在第一列的数据相同的时候,才会使用第二列索引。对于 date_of_birth 不同的这些 ROW 来说,subsidiary_id 的索引用不上。这个时候会有很大一个范围的 TABLE SCAN 了。但是如果我们建立的顺序是 subsidiary_id & date_of_birth 呢?由于第一列的 WHERE 条件是 =,那么在进行后面的 WHERE 条件的时候,即使还是有很多 ROW,但是这些 ROW 的第一列索引都是相同的,所以我们在选择第二列的数据的时候依然可以命中 date_of_birth 的索引。
简单来说,就是建立多列索引的时候,将需要用 = 查询的列的索引放在最左侧,RANGE 搜索的列往后放。
LIKE 查询
LIKE 可能使用索引,也可能不使用,通配符的位置很重要。
因为索引是按照字符串对比来建立的,所以很显然,% 并不能用于索引匹配。简单来说,% 之前的内容会通过索引 access,% 开始就不会了。
比如下面这个例子:
|
1 2 3 |
SELECT first_name, last_name, date_of_birth FROM employees WHERE UPPER(last_name) LIKE 'WIN%D' |
Postgres 的查询计划如下:
|
1 2 3 4 5 6 7 |
QUERY PLAN ---------------------------------------------------------- Index Scan using emp_up_name on employees (cost=0.01..8.29 rows=1 width=17) Index Cond: (upper((last_name)::text) ~>=~ 'WIN'::text) AND (upper((last_name)::text) ~<~ 'WIO'::text) Filter: (upper((last_name)::text) ~~ 'WIN%D'::text) |
从 % 开始就要 RANGE SCAN 了,所以 % 放的越往后越好。
% 不同的几个位置的查询对比:
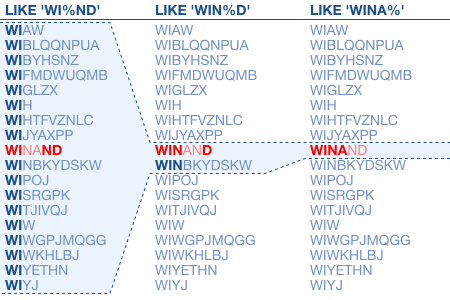
如果 % 在很前面,要 INDEX RANGE SCAN 一大部分数据的话,那就没有 TABLE SCAN 快了。所以优化器要决定是否走索引。
当使用上文提到的 Bind Parameters 的时候,就比较麻烦了。因为优化器并不知道传进来的 LIKE 参数,% 在什么地方。大多数数据库在这种情况下都假设 % 不会出现在开头的地方,从而使用索引。如果需要全文查询的话,只能不使用 Bind Parameters,自己拼接 SQL 查询了。但是这样优化器的成本要高一些,并且用户需要自己防止 SQL 注入。但是 Postgres 数据库除外,Postgres 假设 % 会出现在前面,从而不使用索引。所以如果是 PG 的话,要走索引才需要拼接 SQL。不同的数据库有不同的行为,这个时候用执行计划确认一下最靠谱。
Index Merge
某些情况下,无论怎么建立索引都避免不了 RANGE SCAN,比如下面这个查询:
|
1 2 3 4 |
SELECT first_name, last_name, date_of_birth FROM employees WHERE UPPER(last_name) < ? AND date_of_birth < ? |
如果数据分布是平局的,那么对这两列建立索引的话,总是避免不要 RANGE SCAN 一大部分的数据。
这种情况其实分别对这两列建立索引更好。数据库会分别用两列的索引查出数据,然后将两个结果合并,这样就避免了大量的读表。
7. 部分索引
Postgres 和 Oracle 支持部分索引,这样有什么好处呢?
考虑实现一个任务队列,最常用的操作是从队列中取出未处理过的任务,而处理过的任务很少需要读。
|
1 2 3 4 |
SELECT message FROM messages WHERE processed = 'N' AND receiver = ? |
因为这两个 WHERE 条件都是 = ,所以在这里索引的顺序无所谓。如果我们这样建立索引,是可以通过索引查询的。
|
1 2 |
CREATE INDEX messages_todo ON messages (receiver, processed) |
考虑到我们要查询的目标行是 processed = 'N' 的,而这个表中大部分的数据都是已经处理过的,都不是我们要找的。那能否只对这部分数据建立索引呢?
|
1 2 3 |
CREATE INDEX messages_todo ON messages (receiver) WHERE processed = 'N' |
这样只索引了一部分数据,查询未处理过的数据才会用到这个索引。另外注意到我们索引的字段也改变了,之前要索引 (receiver, processed) 两个字段,现在只索引 receiver 一个字段。因为索引本身已经包含一个信息:“使用索引查找的都是 processed = 'N' 的,这个字段也就不需要保存了。
综上,部分索引从两个维度节省了空间:
- 索引的行数变少了,只索引为处理过的;
- 索引的列变少了,因为被索引的都是未被处理过的数据;
其他一些不会使用索引的情况:
Date 类型
有些数据库(比如 Oracle ),没有 Date 类型,只有带 Time 的表示时间的类型。所以要查询日期的时候,常用的一个函数是 TRUNC,这个函数将时间部分设置为 Midnight。比如,查询昨天的销售额:
|
1 2 3 |
SELECT ... FROM sales WHERE TRUNC(sale_date) = TRUNC(sysdate - INTERVAL '1' DAY) |
这个时候如果有 sale_date 的索引的话,是不会使用的。原因在上文 FBI 已经介绍个过了,函数对于数据库来说是个黑盒,不同的函数以为着不同的索引。
解决方法是使用 TRUNC 函数建立 FBI。或者直接指定查询范围到时间精度。但是要注意,BETWEEN 包含查询边界,所以这里手动拼接 SQL 的时间范围话,一定是从开始时间,到下一天的时间减去 1 个最小的时间精度单位。
以下是用 Postgres 实现的一个例子:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE FUNCTION quarter_begin(dt timestamp with time zone) RETURNS timestamp with time zone AS $$ BEGIN RETURN date_trunc('quarter', dt); END; $$ LANGUAGE plpgsql CREATE FUNCTION quarter_end(dt timestamp with time zone) RETURNS timestamp with time zone AS $$ BEGIN RETURN date_trunc('quarter', dt) + interval '3 month' - interval '1 microsecond'; END; $$ LANGUAGE plpgsql |
当然,更准确的一种方法是在应用的代码内拼接 SQL 的时间边界。或者不要用 BETWEEN,用 >= start_date AND < end_date.
数字和字符串
原理类似的,数据数据库用字符创(TEXT, VARCHAR)来保存数字的话(当然这是一个 bad practice),那么查询的时候也要格外小心。
这样查询,是走不到索引的。
|
1 2 3 |
SELECT ... FROM ... WHERE numeric_string = 42 |
原理是数据库发现要查的 = 的值,和数据库里面的列值是不一样的,就会进行隐式的类型转换,效果其实类似下面这样:
|
1 2 3 |
SELECT ... FROM ... WHERE TO_NUMBER(numeric_string) = 42 |
如此,就和我们前面提到过的 FBI 一样,函数对于优化器来说是一个黑盒的存在,所以优化器会决定 TABLE SCAN。
要解决这个问题也很简单,只要避免隐式的类型转换(避免使用函数就好了)。我们在查询的时候就转换好类型。
|
1 2 3 |
SELECT ... FROM ... WHERE numeric_number = '42' |
使用冗余的 where 语句暗示走索引
有时候我们要结合多列来查询,举个简单的例子,比如一列存了日期,一列存了时间,查询过去 24 小时的数据,需要以下的 SQL:
|
1 2 3 4 |
SELECT ... FROM ... WHERE ADDTIME(date_column, time_column) > DATE_ADD(now(), INTERVAL -1 DAY) |
这个查询显然是无法使用任何一列的索引的。当然,最好是将时间和日期存到一列中,但是在修改表结构比较麻烦的情况下,我们可以想办法让这个查询走索引(即使是部分索引)。
这里的技巧是多使用一个 where,优化器会决定先用索引过滤出一部分数据,然后再扫表。
|
1 2 3 4 |
WHERE ADDTIME(date_column, time_column) > DATE_ADD(now(), INTERVAL -1 DAY) AND date_column >= DATE(DATE_ADD(now(), INTERVAL -1 DAY)) |
类似的技巧也可以用在 Bind Parameters 上。
还记得下面这个查询吗?
|
1 2 3 4 |
SELECT last_name, first_name, employee_id FROM employees WHERE subsidiary_id = ? AND last_name LIKE ? |
由于事先不知道这两列的分布情况,所以优化器无法做出选择。但是假如我们知道 LIKE 总是会有 % 的话,我们可以用一个 trick 暗示优化器不要走索引。
|
1 2 3 4 |
SELECT last_name, first_name, employee_id FROM employees WHERE subsidiary_id = ? AND last_name || '' LIKE ? |
虽然和一个空字符串连接是冗余的,但是优化器会因为这个,不考虑 last_name 这一列的索引。
Smart Logic
SQL 强大的一个功能是支持嵌套查询。这个功能之所以可能,是因为优化器是作用在运行时,可以动态的给出查询计划。但是每次选择查询计划也带来了开销,这个开销可以使用 Bind Parameter 来解决。
有一个常见的错误,是想用静态 SQL 来替代动态 SQL。
举下面的例子,假设有一个表,这个表的三列中任何一列都可能用于查询。有人就想出用下面这个 SQL 代替:
|
1 2 3 4 5 |
SELECT first_name, last_name, subsidiary_id, employee_id FROM employees WHERE ( subsidiary_id = :sub_id OR :sub_id IS NULL ) AND ( employee_id = :emp_id OR :emp_id IS NULL ) AND ( UPPER(last_name) = :name OR :name IS NULL ) |
这个静态 SQL,可以实现使用三列中的任何一(二/三都可)查询,只要将其他没有用到的列设置为 NULL 就好。
但是优化器在面对这个 SQL 的时候,只能按照最坏的 Case 准备,所以它做出的选择是扫全表。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
---------------------------------------------------- | Id | Operation | Name | Rows | Cost | ---------------------------------------------------- | 0 | SELECT STATEMENT | | 2 | 478 | |* 1 | TABLE ACCESS FULL| EMPLOYEES | 2 | 478 | ---------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter((:NAME IS NULL OR UPPER("LAST_NAME")=:NAME) AND (:EMP_ID IS NULL OR "EMPLOYEE_ID"=:EMP_ID) AND (:SUB_ID IS NULL OR "SUBSIDIARY_ID"=:SUB_ID)) |
所以最好的使用方式,应该 SQL 中只写用到的 filter:
|
1 2 3 |
SELECT first_name, last_name, subsidiary_id, employee_id FROM employees WHERE UPPER(last_name) = :name |
The most reliable method for arriving at the best execution plan is to avoid unnecessary filters in the SQL statement.
Math
最后一个经常引起误解的带有数学计算的 SQL,考虑下面这个 SQL,能使用索引嘛?
|
1 2 3 |
SELECT numeric_number FROM table_name WHERE numeric_number - 1000 > ? |
下面这个呢?
|
1 2 3 |
SELECT a, b FROM table_name WHERE 3*a + 5 = b |
如果换个角度考虑问题,如果你是一个数据库开发者,你会在你的数据库里面加一个计算器吗?大多数的回答,都是 No。所以以上两个查询都无法使用索引。
类似的,为了暗示优化器不要使用索引,你可以在查询中加0.
|
1 2 3 |
SELECT numeric_number FROM table_name WHERE numeric_number + 0 = ? |
如果必须要用的话,可以使用 FBI 对这个表达式创建索引。
|
1 2 3 |
SELECT a, b FROM table_name WHERE 3*a - b = -5 |
|
1 |
CREATE INDEX math ON table_name (3*a - b) |
Pingback: Use the Index, Luke! 笔记4:sorting 和 grouping | 卡瓦邦噶!