之前的文章中,分析过 Google 和 Cloudflare 的四层负载均衡设计,都是使用了 DSR 的模式,但是在技术细节方面根据自己的业务需求作了不同的决策。今天,我们继续来讨论一种与这两家公司都不一样的设计:美团的 MGW。
美团的架构设计在中国的互联网公司比较流行,我知道的很多公司都是类似的设计,所以很有代表性。选择美团 MGW 来介绍,是因为可以参考这篇美团技术博客,其他公司公开的资料好像不多。其中一些细节问题,美团没有介绍的,我来根据我知道的补充一下细节,扩展讨论一下。
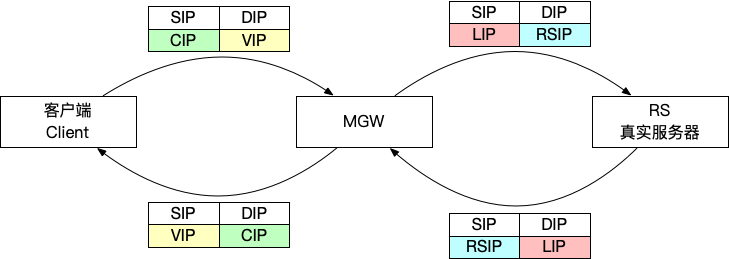
FullNAT 转发架构
FullNAT 转发模式,类似于 Nginx,和客户端建立连接,然后再和 RS 建立一个 TCP 连接。架构上比较简单,对网络设施的要求少(几乎没要求)。缺点是性能差一点。然后 RS 看不到客户端真实 IP,需要通过其他技术方案解决透传 IP 问题。
之前讨论的 DSR 好处很明显:因为回包不走 LB,直接是 RS 通过路由发给客户端,所以性能很高,非常适合大部分的服务场景:发进来的请求很小,出去的响应很大。相比之下,FullNAT 进出都要走 LB,所以 LB 要多花很多计算资源给回包,效率低很多。
FullNAT 相比于 DSR 的优点有:
- FullNAT 可以做端口转换,例如对同一个 VIP 来说,可以配置让 1.1.1.1:80 到一组 RS 的 80 端口,然后配置让 1.1.1.1:8080 到另一组 RS 的 80 端口。DSR 模式是做不到的,因为在 DSR 模式下,对于 RS 来说,感受不到 LB 的存在,入的包看起来就是客户端 IP 发给 VIP 的,它回包也是用 VIP 回给客户端 IP。所以暴露的端口必须是客户端访问的端口。
我认为只有这一个优点。看起来很不起眼,为什么会称之为「优点」呢?因为这让不同的 RS 可以灵活地 listen 不同的端口,但是通过 FullNAT 暴露出去的端口都是一致的。比如,如果容器部署模式选择了 Host 模式,那么所有的容器其实都运行在 Linux Host 的 root network namespace, 同一个端口只能有一个进程 Listen。如果部署很多个实例,不能让它们都 listen 在同一个端口,要给不同的服务分配不同的端口。所以,一个服务 A 的内网地址列表可能是 10.1.1.10:8080, 10.2.2.20:8081,这样的话,通过 FullNAT 的转换,客户端始终可以通过 VIP:80 来访问。
有的地方提到,另一个「优点」是 FullNAT 可以做地址转换。这个显而易见是可以做到的,因为这就是 FullNAT 的含义。不过,向 RS 隐藏了客户端的真实 IP,大部分情况是一个缺点,而不是一个优点吧?在 DSR 的模式下,所有的 RS 都需要配置 VIP,以便向客户端直接发送回包。美团博客将此列为一个缺点,但是我不明白为什么是缺点。如果说 VIP 暴露出去会被攻击,这个是可以避免的,只要不对这个 VIP 发送路由出去就好了,只保留在本地作为回包用的 src IP。那么缺点可能是多一步部署?但是我觉得配置 VIP 没有多麻烦。
连接保持方案
FullNAT 下,TCP 连接保持有两个难点。
一个是 session 的同步,如图所示,假设 TCP 连接是在 MGW-1 新建,那么假设 MGW-1 挂了,RS 把包发给了 MGW-2 的时候,MGW-2 要知道这个 MGW-RS TCP 连接对应哪一个 RS-MGW 连接。
这个问题其实不难解决,通过 IP Multicast 或者外部的同步服务都可以做到 session 同步。
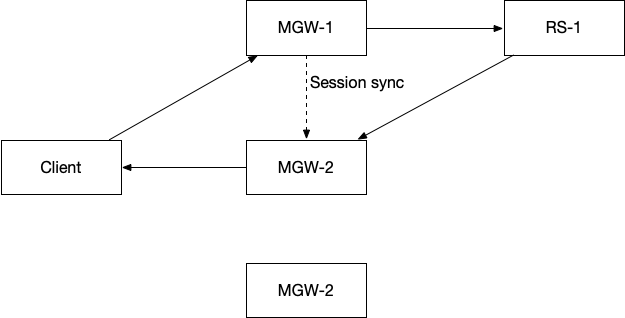
另一个问题是,假设 MGW-1 和 RS 之间的 TCP 连接五元组是 MGW-1 IP, MGW-1 Port, TCP, RS IP, RS Port,如果现在这个连接迁移到 MGW-2,会发现这个五元组变成了 MGW-2 IP, MGW-2 Port, TCP, RS IP, RS Port, 这样,即使 MGW-2 知道这个 TCP 连接的状态,也无法和 RS 正确通信,无法替代 MGW-1 和 RS 直接的连接。要想替代 MGW-1 的话,必须保持五元组不变。现在看到,变的部分有两个:
- 首先,
MGW-1 Port和MGW-2 Port要相同,这个很简单,通过 session sync 知道这个 Port 就可以了; - 其次,需要保持
MGW-1 IP和MGW-2 IP相同,那就需要让所有的 MGW 实例,用相同的 IP 去和 RS 建立连接;
「把相同的 IP 绑定到多个实例上」,这就是 VIP 呀。
是的,其实 MGW 和 RS 之间也是用 VIP 连接的,只不过这部分发生在内网中,我们叫这个 IP 为 Local IP,简称 LIP。
两个问题都解决了,这时候我们发现出现了一个新问题。所有的 MGW Local IP 都一样,那么 RS 把回包发给谁都可以,要想 MGW 能正确转发包回客户端,就必须让 MGW 之间的 session 同步速度要比 MGW 发给 RS 包的速度快。不然的话,RS 响应都回来了,收到包的 MGW 还不知道这个包应该会给哪个客户端。一种简单的方法就是让 MGW 先等等,等到有关这个 session 的信息发过来,再进行转发。另一个不是办法的办法,让 session 同步的速度快一些。
还有一个更好的办法,就是「浮动路由」。
路由器的路由表中,到达某一个网段的选择不只有一条,可能存在多条。但是在路由选择的时候,一定会选择最优的一条,来尽量保持同一个连接的 order。但是假设最优的路由挂掉了,那么次优的路由条目就变成最优的了,相当于「浮动」到上面了,路由器就会选择这条,故称之为浮动路由。
假设我们有 3 个 MGW 实例,我们就使用 3 个 LIP,每一个 MGW 都绑定这 3 个 LIP,其中:
- 如果是发给 RS 包,那么 MGW 只会使用一个来发,MGW-1 使用 LIP1,MGW-2 使用 LIP2,MGW-3 使用 LIP3;
- 如果是接收 RS 包,无论哪一个 LIP 的包都会处理;
- 在 VIP 参与路由宣告的时候,MGW-1 宣告自己的 LIP1 路由优先级是高,LIP2 是低,LIP3 是低;MGW-2 宣告自己的 LIP2 是高,LIP1和3 是低;MGW-3 宣告自己的 LIP3 是高,LIP1 和 2 是低;
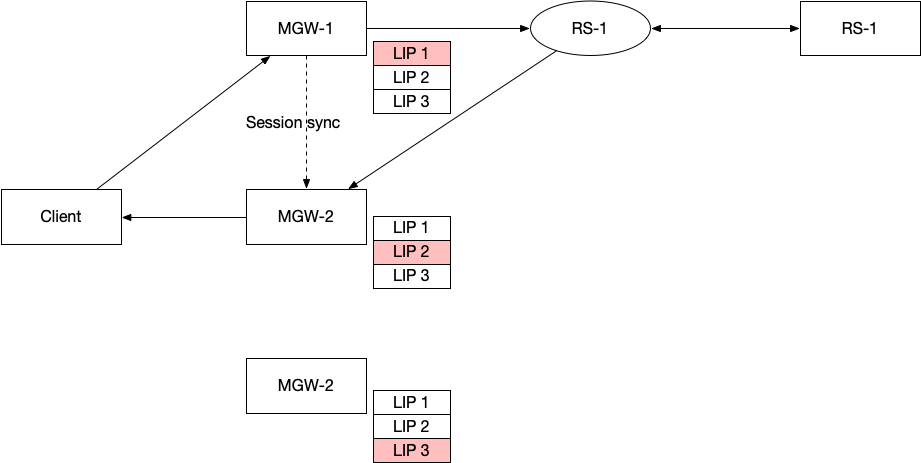
这样,在正常情况下,RS 回包给 LIP1 的时候,路由器总是会发给 MGW-1,会给 LIP2,路由器会发给 MGW-2. 不依赖 Session 同步,MGW 之间不需要同步状态。只有当其中某一个 MGW 挂了的时候,挂了的 MGW 的主 LIP 会自动迁移到其他的 MGW 上处理。
数据面的实现
MGW 是基于 DPDK 的实现,也就是在 userspace 直接和网卡交互,跳过 Kernel 协议栈的内容。
DPVS 是爱奇艺开源的四层负载均衡软件。可以简单理解为,这就是给 LVS 换成了DPDK 的接口。美团博客没有说是不是基于 DPVS 的开发,这里我们就以 DPVS 来讨论吧。
LVS 是中国的开源软件,基于 IPVS 实现了四层负载均衡,在当时是很了不起的技术。很多公司之前都是用了 LVS 作为四层负载均衡器。
但是随着互联网的发展,流量越来越大。一方面是用户越来越多,另一方面是代码越写越差。以前一个几M 的应用能做的事情,现在需要下载几百M的应用。以前手机 8G 存储就了不起了,现在 128G 都不够用。同样的带宽要求也越来越高,4G, 5G 了,还是觉得不够快。四层是面向互联网的接入层,四层负载均衡要承担的流量也就越来越大,LVS 就显得不够用了。
LVS 是基于内核 Netfilter 的程序,已经走了一部分的网络栈了,为了更高的性能,我们就会想到 bypass kernel。一种方式是如 Cloudflare 一样 XDP 在网卡上完成转发,另一种就是在用户态直接和网卡交互,跳过 Kernel。
DPDK 由英特尔的工程师 Venky Venkatesan (被称为「DPDK之父,已于 2018 年去世」)创造,是一个编程库,可以在用户态和网卡交互,从而跳过 kernel,带来更高的性能。
跳过 Kernel 带来的问题是,Kernel 的功能都不可以用了,socket API 就是其中之一。如果不用 Kernel,就意味着你要自己实现 TCP 栈,维护连接,buffer 之类。在用户态实现 TCP,有过各种各样的尝试,但是都存在各种各样的问题。因为 TCP 太复杂了,即使完全按照 RFC 来编程,都不能处理所有的细节,很多在 Kernel 的实现甚至成为了事实标准,难以兼容。
但是,对于四层负载均衡这种场景来说,用 DPDK 就看起来再合适不过了。在之前的博文也提到过,四层负载均衡其实不是一个完整的 TCP 实现,它更像一个三层的路由,按照三层 IP 包来转发。它不维护 TCP 的 buffer,不维护窗口,不负责重传,只是把收到的 IP 包发给 RS。只不过它做的三层路由会查看 TCP 的端口,flags 等,作为转发的依据。所以实现起来比完全的 TCP 栈要简单。
另外多说一句,这个系列的文章主要分析的是四层负载均衡的技术方案,软件的实现只占一部分,像 DPVS,LVS,都可以支持 DSR,NAT,FullNAT 等,一套完整的方案还要包括配置管理,连接保持方案,转发架构设计等等。这个系列着重讨论网络部分,如果读者对软件实现感兴趣,可以阅读 Linux 网络源码分析类的书籍。
除了 bypass kernel,在还有其他的优化可以提升性能。
忙轮询
Kernel 协议栈的工作模式是,如果网卡收到了包需要处理,就通过中断告诉系统,系统再来处理。因为 Linux 是一个多功能的,通用的操作系统。而 DPVS 的工作方式是,一直在轮询处理网卡的包,需要分配单独的 CPU 完全来干这个事情,即使没有包,也一直在轮询,CPU 始终是 100%。(如此可以看出,为什么 Cloudflare 不会选择这种方式了,这样就没办法把负载均衡部署到所有的机器上了。)这样可以将效率提升很多,延迟和吞吐都有提高。
Session 锁
这个不是 DPVS 带来的问题,而是 FullNAT 带来的问题。
由于网络包进来是一对五元组,转发到 RS 又是另一对五元组,所以必须得维护着两个五元组之间的关系才行。包从 VIP 进入 LB 的时候,选择一个 Local 端口,Local IP 发送出去,然后记录这个 Client- LB 连接和 LB-RS 连接的对应关系。从 Local IP 收到回应的包的时候,就不能随意选择了,要去查找一下,这个 LS-RS 连接对应哪一个 Client- LB 连接,使用对应的连接发回去才行。这个两边的连接的对应关系叫做 session table。
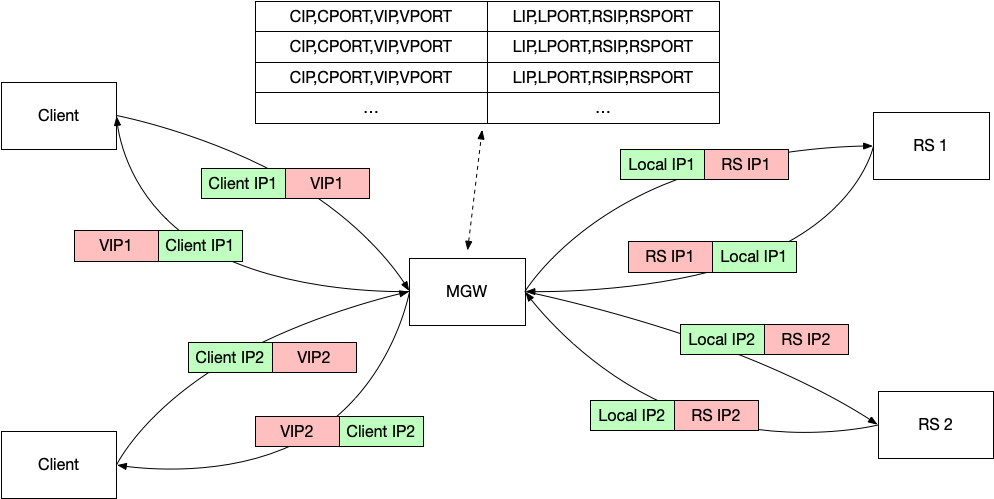
并发访问这个 session table 会带来竞争问题,需要加锁。
但是什么地方带来的竞争,我从美团的博客上没有读明白。博客介绍的原文如下:
之前介绍MGW使用FULLNAT的模式,FULLNAT会将数据包的元组信息全部改变,这样同一个连接,请求和应答方向的数据包有可能会被RSS散列到不同的网卡队列中,在不同的网卡队列也就意味着在被不同的CPU进行处理,这时候在访问session结构的时候就需要对这个结构进行加锁保护。
同一个连接的读写为什么会产生竞争问题呢?假设第一次连接进来的时候在 CPU0,流程如下:
- 选择一个 local port,然后保存 client ip, client port, vip, vip port 与 local ip, local port, RS ip, RS port 的对应关系;
- 然后转发到 RS;
回包的时候,即使到了 CPU1,那么流程如下:
3. 查表,查到之前保存的对应关系;然后根据这个关系选择 VIP port 来转发给客户端。
可以看到,3 必定发生在 1 和 2 之后,看起来不存在竞争。(读者理解这个地方的话,欢迎指点)
我猜测,可能竞争是发生在不同的 CPU 都要在 session table 新建内容,比如 CPU0 要添加,CPU1也要添加,这时候有两个写,必须锁起来一个一个操作。
解决的思路,就是将数据隔离开,不同的 CPU 之间不需要访问共享数据的部分。
美团的方法是,给每一个 CPU 绑定一个 Local IP,CPU0 使用 local ip0,CPU1使用 local ip1,这样没有数据共享,就不需要加锁了。使用网卡的提供的 flow director,可以做到将 local0 的数据包全都给 cpu0 的队列处理。(如果结合上面提到的浮动路由使用的话,那么每一个 MGW 的 CPU 都需要有一个 Local IP 并且绑定到集群的所有实例中。)
减少上下文切换
就是把跑数据面的进程绑定到固定的 CPU 核心上,然后像 bash,ssh,等其他程序都绑定到其他的核心上。这样,数据面进程永远不会处理中断之类的事情,只会跑重要的数据面进程。
运维优化
MGW 实例的健康检查。由于路由器从 ECMP 层面摘除节点,只会发生在端口 down 的情况下。假设端口没 down,但是程序已经挂了,那路由器感知不到,还是会把流量发送过来,这部分流量只能被丢弃。所以 MGW 实现了一个健康检查,假设程序异常,直接给网卡断电,能够实现快速切换到其他 MGW 实例上去。
新的 MGW 上线的时候,会先不接收流量,先从其他实例增量同步过来 session table,同步完成,才开始服务流量。
RS 的优雅下线。在 RS 下线的时候,MGW 可以保持旧连接,但是新连接不再发送过来。直到旧连接都顺利结束,RS 开始下线。
支持让相同客户端发送过来的请求,都发送到相同的 RS 上面,是基于对客户端的 IP hash 来实现的。但是为了避免 RS 变化的时候,整个重新 hash,这里借鉴了 Google Maglev Consistent Hash 的方法。(不过有个小疑问,如果大公司办公室用一个出口 IP,那不是午饭的时候点外卖全都到了同一个 RS 上面了?)
以上就是这篇分析了。总体来看,使用 FullNAT 牺牲了部分性能,但是技术的复杂程度,运维复杂度都降低了很多。
> 在 DSR 的模式下,所有的 RS 都需要配置 VIP,以便向客户端直接发送回包。美团博客将此列为一个缺点,但是我不明白为什么是缺点。
可能是指向 RS 部署网络配置的复杂度。每新增一个 LB 就需要在 RS 服务器上配置 VIP。如果没有一个标准化的组件,管理复杂度很高。例如在 Azure 上启用 Floating IP 就需要这个配置,而且 Azure 平台是不管 Guest OS 的,需要客户自己来配置。
如果 VIP 配置部署太晚或失败时,RS 已被添加到 LB,此时会直接造成故障。这种场景下 eventual consistency 的设计不能满足需求,组件必须做到添加 RS 的流程里作为强依赖项。
明白了。VIP 是需要 RS 部署一种参与路由的进程来宣告 VIP 进路由吧,这个维护起来确实是成本。
我觉得复杂度主要还是跨越运维边界了。例如 Azure 上 VM 外由平台负责,VM 内的 OS 由客户负责。想要跨边界实现可靠的全流程自动化是比较困难的。
面对这种复杂度, Azure 直接做成了 VM 内配置由客户自己处理,出问题了是客户自己没用好。但这样体验就差了,客户对标准化和自动化投入不足的话还容易出故障。
以上还只是云上 VM 的情况。如果是转发到防火墙等黑盒设备,配置复杂度和自动化难度会进一步增加。
这一点很同意!忽略了现实的「技术边界」问题。我也发现往往跨团队的时候最容易出问题了,明确好一个清晰的边界会有一个管理上的收益。
> 同一个连接的读写为什么会产生竞争问题呢?
我的理解是,session table 不止保存一个连接,如果存在跨 CPU 的 lookup,意味着这个数据结构就不是单 CPU 独享了,此时会有经典的 cache invalidation 问题。可以搜索 memory barrier 了解一下。
原来是这个层面。感谢。
发生在 CPU 层面的话,那这里代码中是没有明确使用锁的,但是执行的时候会有锁的效果。对吗?
该用锁没用的话,程序可能会异常(undefined behavior)甚至 crash。这个“代码中是没有明确使用锁的”是怎么来的信息?
看了下内存屏障,是我理解错了,忽略吧。
看了下维基百科,内存屏障是用锁来实现的,锁就是从这里来的吧?
https://zh.wikipedia.org/wiki/%E5%86%85%E5%AD%98%E5%B1%8F%E9%9A%9C
所以代码中的
lfence (asm), void _mm_lfence (void) 读操作屏障
sfence (asm), void _mm_sfence (void) 写操作屏障
mfence (asm), void _mm_mfence (void) 读写操作屏障
带来了锁?
反了,是 mutexes imply memory barriers,memory barriers 才是更底层的概念。参考 https://www.kernel.org/doc/Documentation/memory-barriers.txt 中 “IMPLICIT KERNEL MEMORY BARRIERS” 一节,以及 https://stackoverflow.com/a/50952621
简单来说这个场景下代码需要 imply memory barriers,如果没有明确使用这类函数,意味着线程安全性被破坏,并发执行会出问题的。
你是有找到这部分对应的代码吗?看美团的博客里没有放代码,MGW 应该也没有开源呀。
没有代码,这是我从 wiki 看到的解释,代码也是 wiki 里面的。
谢谢!我学习下您发的资料。
Typo: 假设程序一场 -> 假设程序异常
感谢,已修改。
国内云厂商或者传统负载厂商的负载均衡,大部分是fullnat模式,就是因为简单,后端不用任何特殊配置,后端的操作权都在用户手里,一般不用客户做任何配置。源IP透传一般使用代理协议(proxy protocol)或者toa(tcp option address)。
还有进出都过负载,厂商能做提供进出方向的监控。
是的,架构上确实简单很多。
很棒的文章,知识密度很高,外链出去后,又有新的视野,就像一个个兔子洞,哈哈~特别是文末提到的内存屏障,可能是偏向于底层硬件,感觉还是有些陌生;
回到文章上来,有一个小问题,就是关于用户态实现tcp中的各种尝试,外链中的内容是16年左右的,当时cloudflare认为“半bypass kernel”是最优解,而对netmap做了迭代没有用DPDK,那么我想了解下距今近10年的网络发展,是否DPDK已经成为用户态实现tcp的bypass kernel的实际实现标准了呢,比如18年左右听到在pop点通过DPDK进行流量过滤,现在是什么情况了呢,有没有关键词或是链接可以了解一下,非常感谢
我觉得不能说成为实际标准,XDP 和 DPDK 现在使用的都比较多。DPDK 要说最大的问题就是对部署的要求比较高,要网卡支持,要解决 ssh 等还要用 kernel 协议栈的程序。CF 应该是基于 XDP 的。
mgw 其实是阿里的人过来搞的,在阿里叫 agw,那会爱艺奇还没开源 dpvs