之前的博客中,四层负载均衡漫谈 介绍和总结了四层负载均衡的相关技术。接下来的博客,会分析一些不同公司的四层负载均衡架构的设计。
今天这篇要介绍的是 Google 的 Maglev,主要的参考是这篇:Maglev: A Fast and Reliable Software Network Load Balancer,所以本文也算是一篇论文导读吧。
按照之前博文列的四层负载均衡技术选型,Maglev 在这里的选择如下。
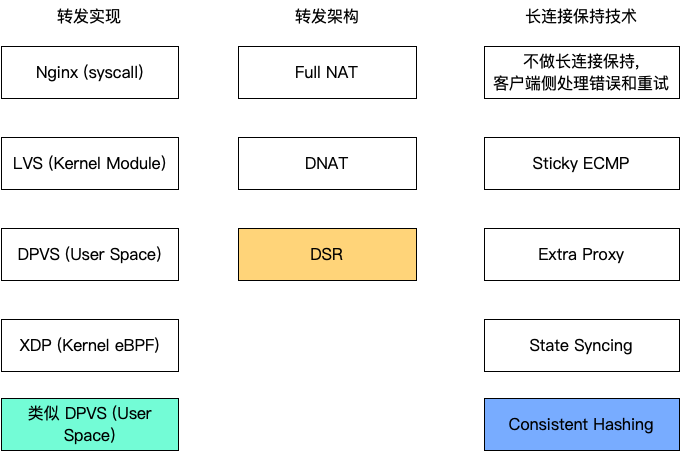
可以看到,其中有转发的实现(因为当时还没有 DPDK 吧),和长连接保持技术,都用了之前博客中没有介绍过的,很有创新!
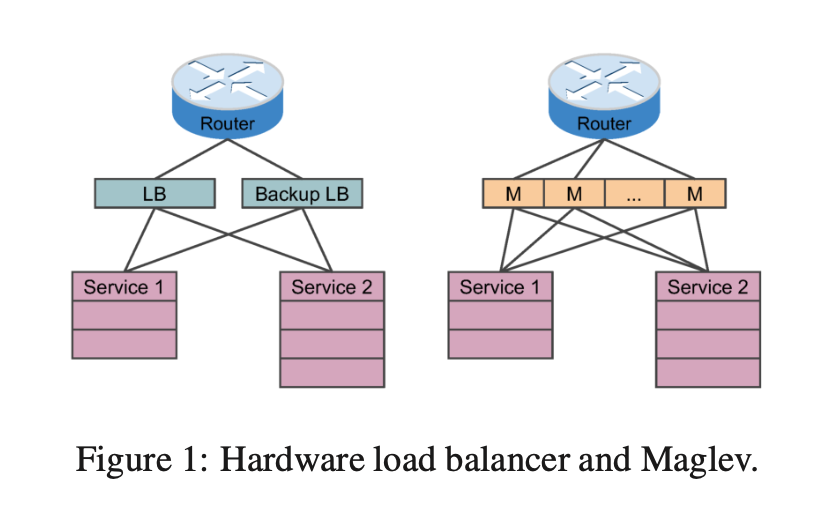
Google 刚开始用的架构是硬件负载均衡,主要的问题有:
- 扩展性问题:硬件负载均衡是专有设备,需要购买新的设备来扩展;
- 高可用:基本上只有 1+1 冷备份的方案;
- 不可以编程扩展功能;
- 升级的成本高,意味着要购买新的硬件,测试和部署;
显然,用软件来替代硬件负载均衡能够解决以上的问题,只不过要复杂一些。软件意味着可以随意部署随时扩展(机房里面的服务器多的是),可以设计高可用,想要什么功能就可以实现什么功能,升级成本很低,部署新的软件就可以了。
但是软件的挑战在于:性能要高,性能如果不高,就没有意义,性能的瓶颈在哪里呢?就是网卡的速度,如果是 10G 的网卡,软件负载均衡能够用满这 10G,那就到顶了。就是在博客 四层负载均衡漫谈 中介绍过的线速(line rate)。Maglev 就能够用小包达到线速(论文中的机器规格是 10G 网卡,为什么用“小包”来做评测,因为对于负载均衡来说,评价指标是 pps, packet per second,包越小,达到线速需要的包越多,软件要处理的 pps 就越高,性能要求越高。用大包的话,达到线速比较轻松,说明不了性能有多好)。
在本文的语境中,所有的「包」指的都是 3 层 IP 协议包。
第二个挑战是,要保持连接的状态,即,保证一个连接总是到达相同的 RS(Real Server, 真实服务器)。
转发架构设计
Maglev 使用了可以跨二层的 DSR 转发。
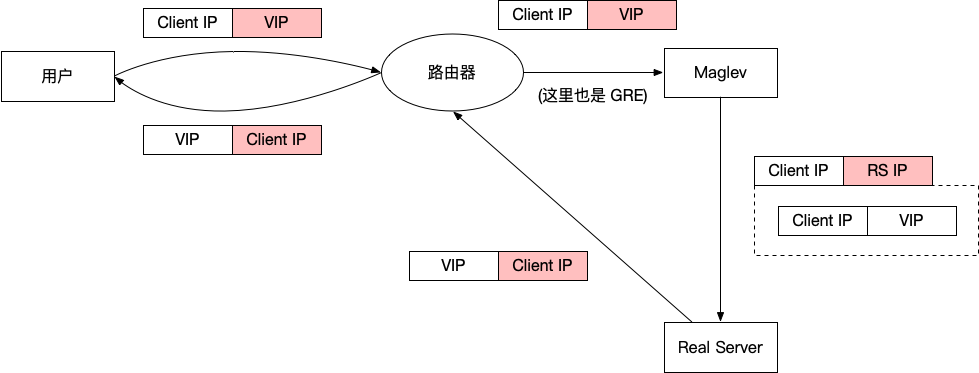
Google 的每一个服务都有一个 VIP,这个 VIP 就是对外暴露的 IP,Maglev 把这个 VIP 通过 BGP 宣告给路由器,路由器将这个 VIP 宣告给 Google 骨干网,最终会出现在公网上。
用户在访问服务的时候,通过 DNS 查询域名对应的 IP,得到的就是这个 VIP。所以用户侧发出的包,dst ip 是这个 VIP。
路由器会将这个包路由到 Maglev,此时 dst IP 依然是 VIP。
Maglev 会查找这个 VIP 对应的服务(每一个 VIP 都对应了一个服务),然后将这个包转发给此服务(就是 Real server)。因为要跨二层,所以这时候不能直接用二层路由的方式转发给服务了,Maglev 会将这个包封装在 GRE 中(就是将原来的整个二层包放到一个 IP 包里面),此时外面的 IP 包继续走正常路由,dst IP 改成真实服务器的 IP。
GRE 封装不是增加了额外的 header 字段吗?如果超过 1500 bytes 怎么办?这里我自己尝试了一下和 Google.com 建立 TCP 连接,Google 发回来的 SYN+ACK 包中,MSS 是 1412 bytes,看来是给 GRE 预留了 header 的空间。
包路由到达了真实服务器,会解开 GRE 的封装,这时候包的 dst IP 又变回了 VIP,src IP 就是客户的 IP。此时,对于真实服务器来说,这个包就好像是由客户端直接到了自己这里一样。然后它会开始处理这个请求,返回响应的时候,直接将 3 层的 src IP 设置成 VIP,dst IP 设置成客户端 IP。
响应(这里指的是反方向的 IP 包路由,包括 TCP 中发给客户端的 ACK 等等)路由给客户端,就是完全正常的 3 层路由了,从真实服务器路由给客户端,不需要任何封装了。
由于整个 DSR 过程都发生在 Google 机房内部,所以客户端对此一无所知,对客户端来说,包到了 VIP,又从 VIP 返回了响应,一切都很简单。
这里有一个小细节,我们在介绍 ECMP 的时候提到过,ECMP 是发生在一跳之间的,所有同一个路由器后面的机器都是均等路由的。Google 不想把所有的实例都放在同一个二层下面,解决方案是,Ingress 路由器发给 Maglev 这一段,也是经过 GRE 封装的,可以跨二层路由。
配置管理
Maglev 分成控制面和数据面。在网络实现方面,这是经典的做法。比如路由器中,控制面负责交换路由,计算最终的路由表,数据面负责根据路由表的高速转发。
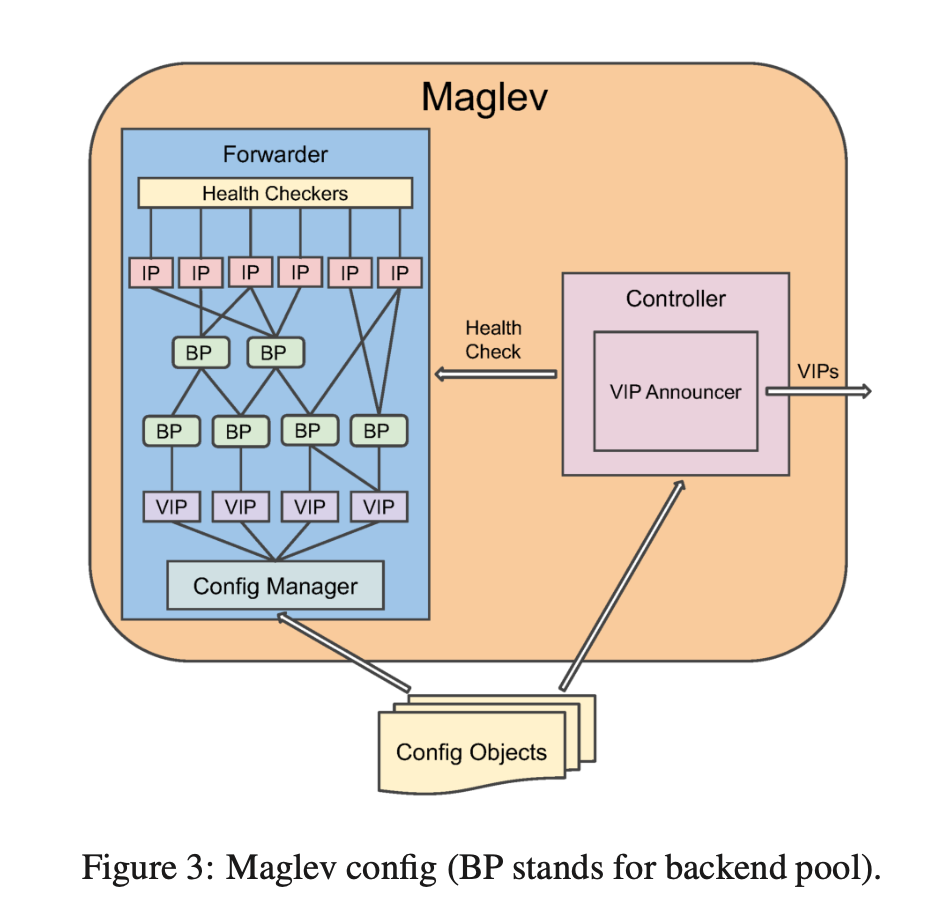
从公网进 Maglev:
- Controller 负责检查 Forwarder 的状态,如果健康,就将 VIP 宣告进 BGP 中;
从 Maglev 到真实服务:
- 每一个 VIP 都对应一个 Backend Pools,这样 forwarder 根据 VIP 就知道应该向哪里转发。BP 也可以包含 BP,这样如果有 BP 被多个地方引用,就可以只在一处更新;
- Config Manager 负责获取新的 config,验证正确性,然后执行配置变更;
- 每一个 BP 都配置了一个或多个 health checker,heath check 会拿到 IP,去重之后再执行,减少因为 BP 重复造成的重复检查;
同一个服务有多个 VIP,部署到多个 Maglev 集群,用于做隔离,测试等。
Maglev 转发的设计和实现
这部分介绍了一个数据包进入了 Maglev 机器的网卡,处理完成,最后发出的过程。即软件实现上的架构。
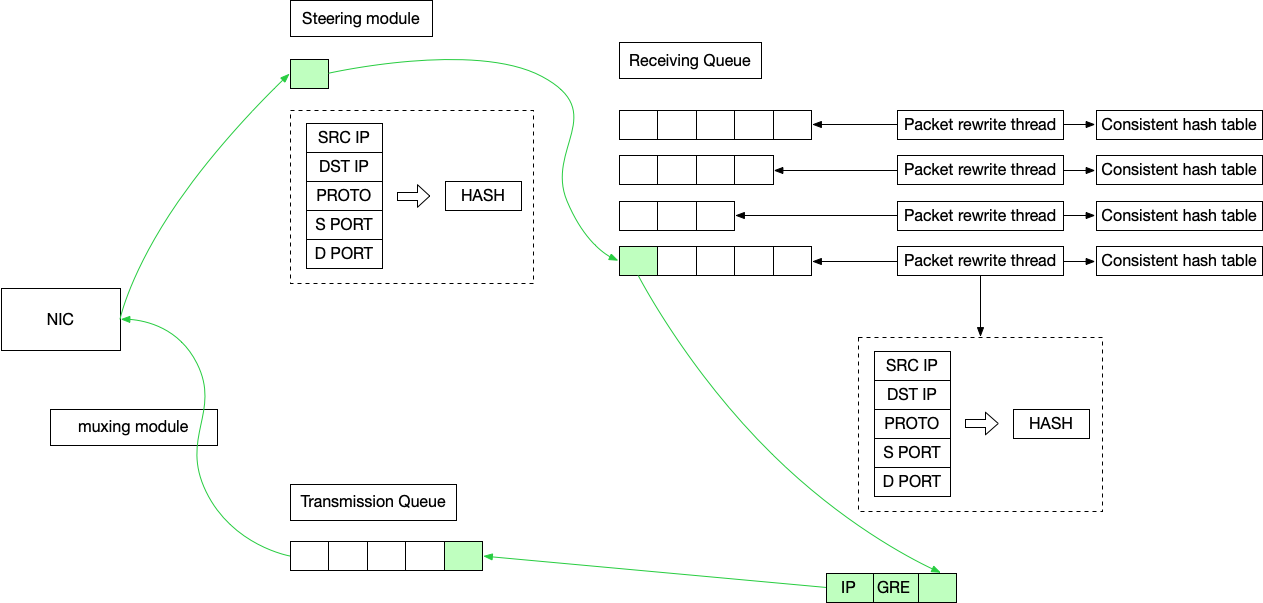
上图中绿色的是包经过的路径,依照此,转发链路总览如下:
- 首先包到达网卡;
- steering module 最先处理这个包,它的下一站有多个 Receiving Queue,steering module 的任务是计算出这个包的五元组 hash,决定这个包应该去哪一个 Queue。然后这个包来到了 Receiving Queue 等待处理;
- 每一个 Receiving Queue 都有一个 Packet Rewrite Thread,在这里,它的主要任务是找到这个包应该去的 Real Server IP,步骤如下:
- 查看是否有对应的 VIP,如果没有,直接丢弃;
- 计算五元组,拿到一个 hash,查看 connection track table,找到对应的 Real Server IP;
- 如果找不到的话,就使用 Consist Hash 算法,选择一个 Real Server IP,然后记录进入 connection track table;
- 找到 Real Server IP 之后,封装 GRE/IP Header,放入Transmission Queue 中;
- muxing module 会将包从 Tranmission Queue 移动到 NIC 中;
- NIC 最终将包发出去;
这里有几个有意思的细节:
steering module 已经计算了五元组 hash,为什么在 Packet Rewrite Thread 中又要计算一遍呢?计算着两遍的值应该是一样的。这是为了减少在不同 thread 中需要的同步操作,如果计算两遍,就可以你干你的,我干我的,互不影响。真正的多线程是在 RQ 里面的 threads 开始的,所以 steering 在分配的 queue 的时候必须足够快才行。
这也是为什么每一个 thread 都有一个自己的 connection track table,而不是共用一个的原因,也是消除跨线程同步。
那么为了让 steering module 足够快,为什么不用 round robin 来分配 queue 呢?1)如果不同的 threads 都在处理同一个连接的话,很容易造成 TCP 乱序;2)因为每一个 thread 都维护了一个 connection track table,保证同一个五元组只去同一个 queue,可以减少 connection table 的大小,也可以提高效——在 connection table 直接能找到 backend,而不需要计算 hash 来选择。不过,在一个 queue 要满了的时候,steering module 就会 fallback 到 round-robin,这在相同五元组有大流量的时候很有效。
Kernel Bypass
和其他的四层负载均衡实现一样,对于 Maglev 来说,也是不需要 Kernel 协议栈的功能的,所以 bypass kernel 会带来巨大的性能提升。
Maglev 是一个运行在 userspace 的程序,使用 NIC 提供的功能,让 NIC 和程序直接共享一块内存。它在用户态实现了类似 Ring buffer 的机制。steering module 负责 Receive Queue 的指针移动,muxing module 负责 Transmission Queue 的指针移动。中间没有数据包的拷贝。
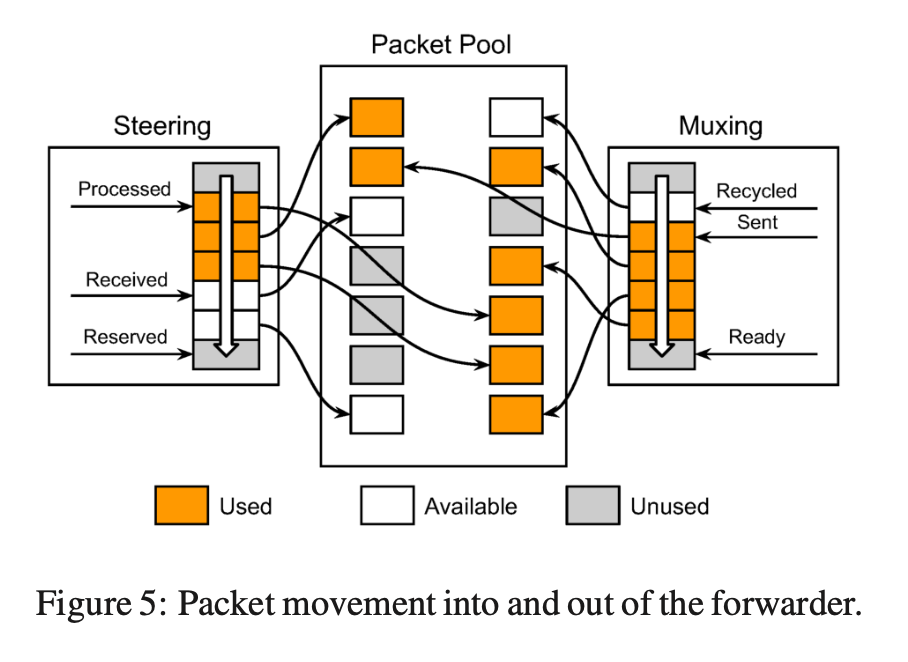
这部分还有一些细节的优化:
- Batch 处理,等待 buffer 中有足够的 packet 再开始一起处理,效率更高;
- Pin packet thread 到固定的 CPU,减少 context switch;
连接保持的实现
要想保持住一个 TCP 连接,本质上,就要保持五元组相同包一定要到固定的 RS 上。这里有两段需要考虑。
第一段是 Maglev 和 RS 之间的部分。这段上文已经描述过了:Maglev 在选择 RS 的时候,如果能从 connection table 找到五元组 hash 对应的 RS,就直接使用这个 RS;如果 connection table 没有五元组对应的 RS,就基于 consistent hash 选择一个并记录到 connection table 中。这样就保证 Maglev 总是能把此五元组转发给相同的 RS。
第二段是 Router 和 Maglev 之间的部分。ECMP 不会保证总是将相同五元组的包发给相同的机器,比如 Maglev 滚动升级,或者扩容,缩容等。但是这也没什么问题,以上技术方案已经覆盖这些场景了。假如一个 TCP 连接的包之前发给 Maglev A,现在转发给了 Maglev B,Maglev B 机器上不存在这个 connection table,但是经过 consistent hash,也会 hash 到同一个 RS 上。Maglev 到 RS 的包是通过 GRE 封装转发的,GRE 底层的协议是 IP 协议,无连接,所以转发到 RS 上面会被正确处理,不会被 RS 丢弃。RS 解开 GRE 封装,拿到的包的 src IP 是客户端 IP,dst IP 是 VIP,它并不知道(也不关心)是哪一个 Maglev 发过来的。所以可以说,所有的 Maglev 都能处理所有 connection 的包。
唯二可能出问题的地方是:Maglev 机器有变化,导致包去了和原先不一样的 Maglev 机器,这个机器在计算 consistent hash 选择 RS 的时候,碰巧 RS 也有变化,比如正在滚动升级,造成 consistent hash 的选择结果和之前的 Maglev 机器选择结果不一样,这时候才会出问题。
另一个可能出问题的地方是,前面提到过,connection table 是 by thread 的,如果某一个 table 遇到的 load 过高,或者遭遇了 TCP SYN flood 攻击,开始 fallback 到 round robin,那么这时候 Maglev 有变更的话,新 Maglev 机器使用 consistent hash 计算得到的 RS 就会和之前的包去的 RS 不一致。
机器的硬件配置比较高,出现这两种情况的几率其实都不高。这个方案看起来比较完美。主要归功于 consistent hash。
Consistent Hashing
Consistent Hash 在这里解决的问题是:Maglev 使用这个方法选择 RS 的时候,每次计算,只要是连接的五元组一样,就需要选择出一样的 RS。
并且,它还要保证两点:
- 选择 RS 要是均匀的,这样才能保证 RS 之间的负载均衡;
- 当 RS 发生升级和替换的时候,要尽可能减少 rehash 带来的选路变化;
举个例子,现在有 1000 个五元组(src ip, dst ip, portocol, src port, dst port),有 100 个 RS,hash 算法要保证,对于每一个五元组都选择一个 RS,并且相同的五元组选择的 RS 也相同,所有的 RS 被选择的次数几乎是一样的(负载均衡)。当其中有一个 RS 出现问题被删除的时候,1000 个五元组 hash 的结果中,只有 10 个需要改变(hash 到出现问题的 RS 的这 10 个),其余的都不需要改变,以减少 RS 变化带来的连接迁移变动。
论文的原文里有介绍具体的 hash 算法实现,但是本文就不展开介绍了,先介绍到这个算法的作用。
运维经验分享
论文中有这么一小节,看似收尾实则非常精彩。
架构演进
主要有两点:一开始是 Active-backup 的模式部署的,这样有点浪费资源。现在改成用健康检查 + BGP 宣告 VIP 的方式,这样坏了随时立即下线,平时都跑着;另外就是一开始用的 Kernel 的协议栈,用 socket 编程实现的。后来换成了 bypass kernel,这部分难点就是要找一个 GRE 封装实现,去在用户态做 GRE 的事情。Kernel bypass 之后得到了 5 倍的性能提升。
我原本以为 consistent hashing 选择后段的 RS 也是后来加上的,没想到自设计之初就有了,这个 feature 简直太厉害了,解决了许多问题。
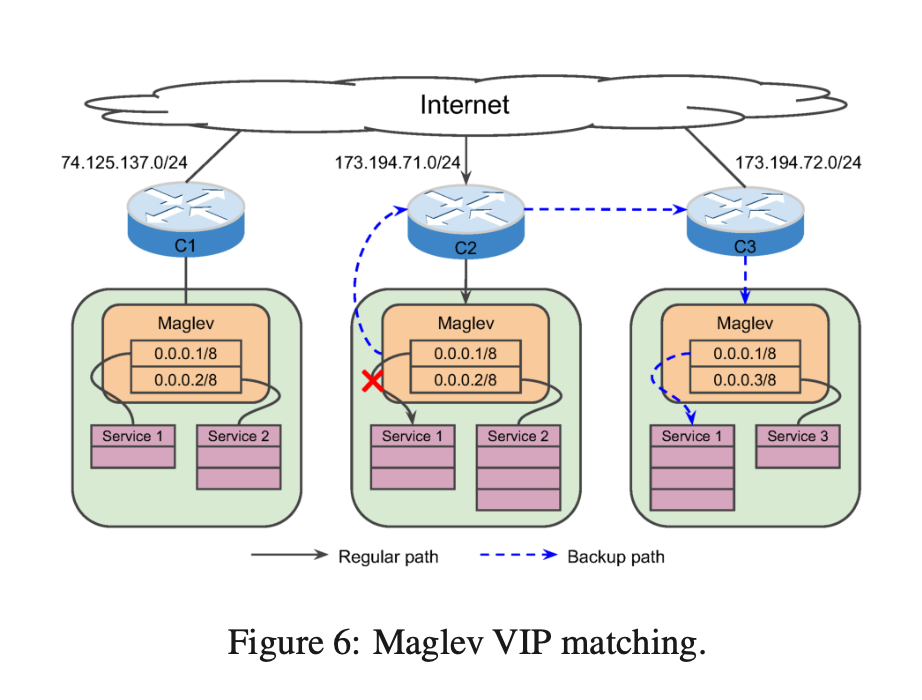
VIP Matching
这个设计太有意思了。
在某些紧急的时候,一个 cluster 的 Maglev 需要将流量全部转发到另一个 cluster。比如 cluster-A 的 Maglev发现,本 cluster 的服务 X 的实例都不健康了,需要将 cluster-A 收到的流量全部发送到 cluster-B 来处理。cluster-B 有服务 X,Y,Z,怎么能让服务 X 的流量从 cluster-A 全部转发到 cluster-B 的服务 X 呢?
这里有两种方法:一种是在不同的 cluster 之间同步服务发现数据,即 cluster-A 知道 cluster-B 的服务 X 有哪些 VIP;另一种是让 cluster-B 的所有 VIP 都能处理 X,Y,Z 的流量,这样只要收到流量就能处理。
但是这两种方法在规模很大的时候都会有问题,复杂度也比较高。Google 用很简单的一种设计解决了这个问题:同一个服务在不同的地区的 VIP 后缀(即 IP 的最后几个 bit)是一样的。因为像 Google 这样的公司申请 IP 都是按段分配,所以可以做到这一点。比如在一个地区拿到的公网 IP 是 3.3.3.0/24, 另一个地区拿到的公网 IP 是 4.4.4.0/24,那么一个服务的 VIP 就分别用 3.3.3.1 和 4.4.4.1。当 3.3.3.1 出现问题的时候,全部将流量转发到 4.4.4.1。再比如当 3.3.3.2 服务出现问题的时候,将流量全部转发到 4.4.4.2。
这样,既不需要在不同的集群之间同步状态,也能在不同的集群之间准确路由不同服务的数据。
举个例子,我们可以用 DNS Checker 这个网站来查看 accounts.google.com 在世界各地的解析结果。
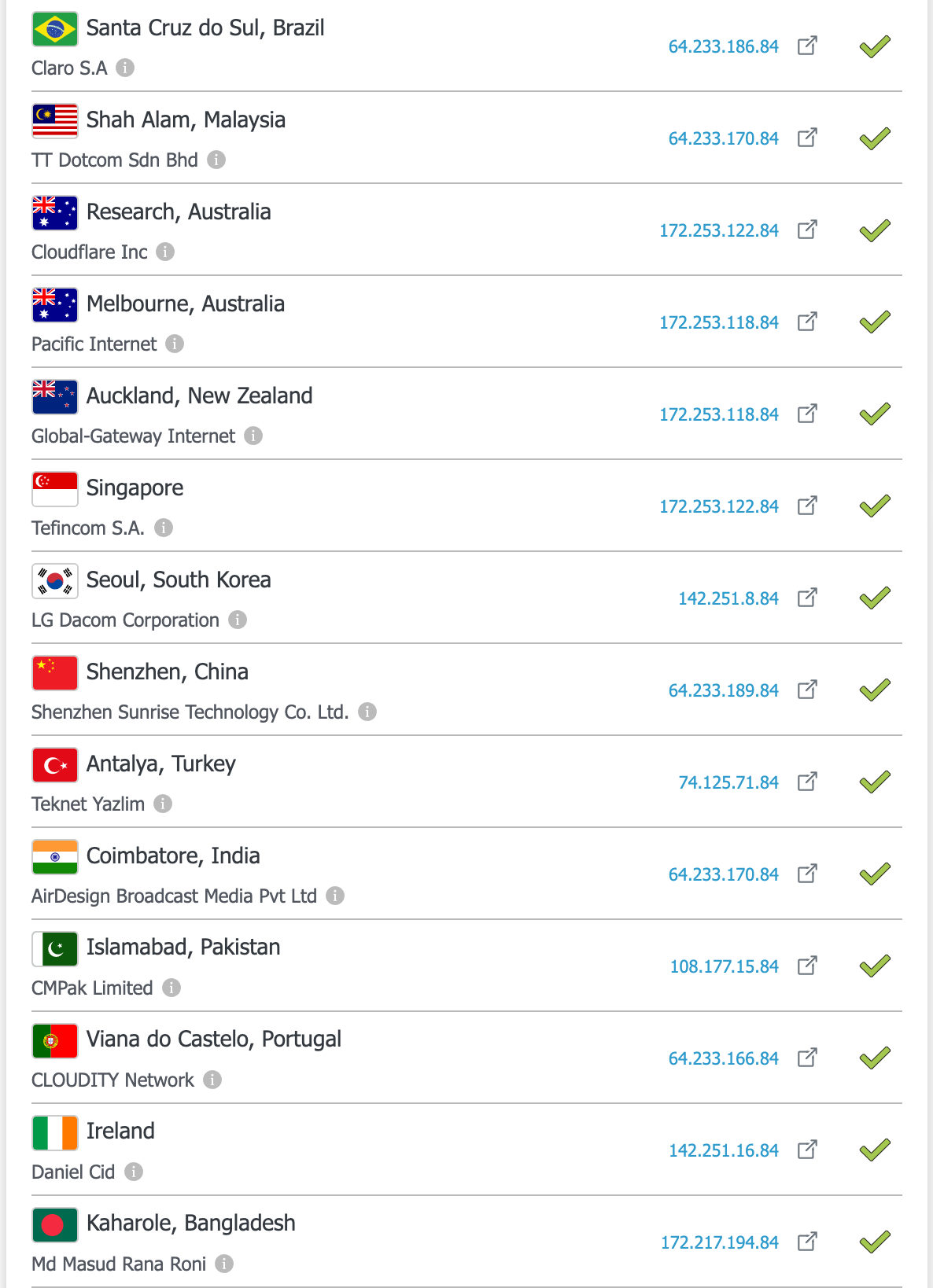
accounts.google.com 在世界各地的解析结果可以看到,虽然这个域名在世界各地解析出来的 IP 前缀不同,但是最后都是以 .84 结尾的。(也有一些域名不是这种形式,这篇论文是很久之前发布的,可能不是所有的站点都用了论文中描述的技术。)
Fragmentation
如果客户端发来的 IP 有 Fragmentation 怎么办?这里的难点是,如果发生 Fragmentation,是在 3 层做的,也就是一个 TCP segment 拆到了多个 IP 包里面发送,只有第一个 IP 包会存在 TCP header,剩余的分片不会带有 TCP header。
我们之前提到的 consistent hashing 是基于五元组的,少了 TCP port,Maglev 怎么知道应该发送给谁呢?
方法是这样的:现在只有三元组了,那就按照三元组来,根据三元组得到一个 Hash,然后用这个 Hash 不是选择一个 RS,而是在当前集群中选择一个 Maglev,把这个 IP Fragment 发到选中的 Maglev 上面。这样,无论是哪一个 Maglev 收到这种 IP 分片,它们总是会到达同一个 Maglev 实例上。
这台身负重任 Maglev 要负责始终转发到同一个 RS 上。方法是,IP 分片的第一个,按照老样子挑选一个 RS 转发,并在一个特殊的 fragment table 中记录对应的 RS,后续进来的 IP 分片都朝这个 RS 转发。那么如果发生了乱序,分片2 比分片1 先到了,怎么办?这种情况下 Maglev 会等待一段时间,等分片1到了,那么先发分片1,再发分片2。如果等了一段时间还没等到,就放弃了,直接丢弃。
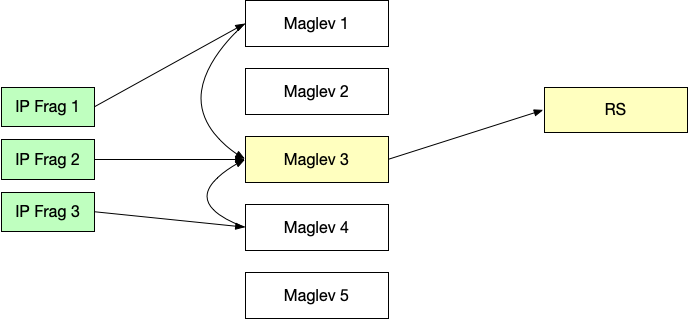
这样能保证正确性,但是还有两个问题。(其实这些问题在博文 有关 MTU 和 MSS 的一切 中我们详细讨论过。
一个问题是,因为多一个 hop,可能造成乱序,比如分片 3 直接命中,一跳就成功,分片 2 要 2 跳才到正确的 RS。这种情况要依赖对端来处理了。比如 TCP 本身就保证顺序,如果是 UDP,那么应用要自己处理乱序。
另一个问题是,这个实现引入 buffer,可能有安全问题。现实是分片不应该很多,Google 只对部分 VIP 开启允许 Fragmentation 功能,其他禁用,所以内存也就足够了。
监控和 Debug
这部分值得一说的是 Google 实现了一个 Debug 工具:packet-tracer。核心原理是,这个工具作为客户端发给 VIP 请求,其中 L3/L4 中加入了特殊的 header,Maglev 认识这些 header,Maglev 会正常处理这些请求,但是会从 header 中读出来一个 debug 信息上报用的 IP,然后把自己的名字,选择的 RS 上报到这个 IP。我目前的工作是 service meshing 领域,所以深知这个能够追踪整个链路的工具的价值。
论文的最后一节是性能评测部分,结论就是很牛就对了,能小包到线速。这部分的详情笔者想省略了。以上就是论文的技术实现部分的详细分享,欢迎留言交流。
附录:
- Manjusaka 写的 简单聊聊 Maglev ,来自 Google 的软负载均衡实践。
四层负载均衡系列文章
版权说明:本文中的图片,如果带有 Figture n: 字样,说明截图自论文,版权属于论文。其余文字和图片内容为原创,发布即进入公有领域,任何人可以随意使用。
发现了几个 typo
返回影响的时候:影响 -> 响应
兀连接:兀 -> 无
显示是分片不应该很多:显示 -> 现实
能小包到限速:限速 -> 线速
谢谢!均已改正
Maglev 的 ringbuf 的设计非常精妙
甚至 Google 还吹了一波
Typo: paket-tracer -> packet-tracer
我觉得设计最精彩的四层负载均衡还得是 AWS 的 Hyperplane,有空可以交流下。
谢谢,已修改。我去学习一下 Hyperplane
Pingback: 四层负载均衡分析:Cloudflare Unimog | 卡瓦邦噶!
Pingback: 四层负载均衡分析:美团 MGW | 卡瓦邦噶!
捉虫:
性能的平静瓶颈 —> 猜测应该是多打了“平静”?
感谢,已经改正。
Pingback: 四层负载均衡分析:GitHub GLB | 卡瓦邦噶!