在检查两个 IP 之间的网络情况的时候,常用的工具有两个:ping 可以检查两个 IP 之间通不通,以及延迟有多少;traceroute 可以检查从一个 IP 到另一个 IP 需要经过哪些 hop。
而 mtr 将这两者结合了起来:使用 traceroute 将两个 IP 之间需要经过的 hop 找出来,然后依次去 ping 这些 hop,就可以看到当前的 IP 到所有的这些 hop 的延迟和丢包率,这样在某些情况下就可以诊断出来丢包和延迟发生在哪一个节点上。
mtr 的安装和使用非常简单,和 ping 类似,只要执行 mtr <ip> 命令,就可以得到如下的界面:
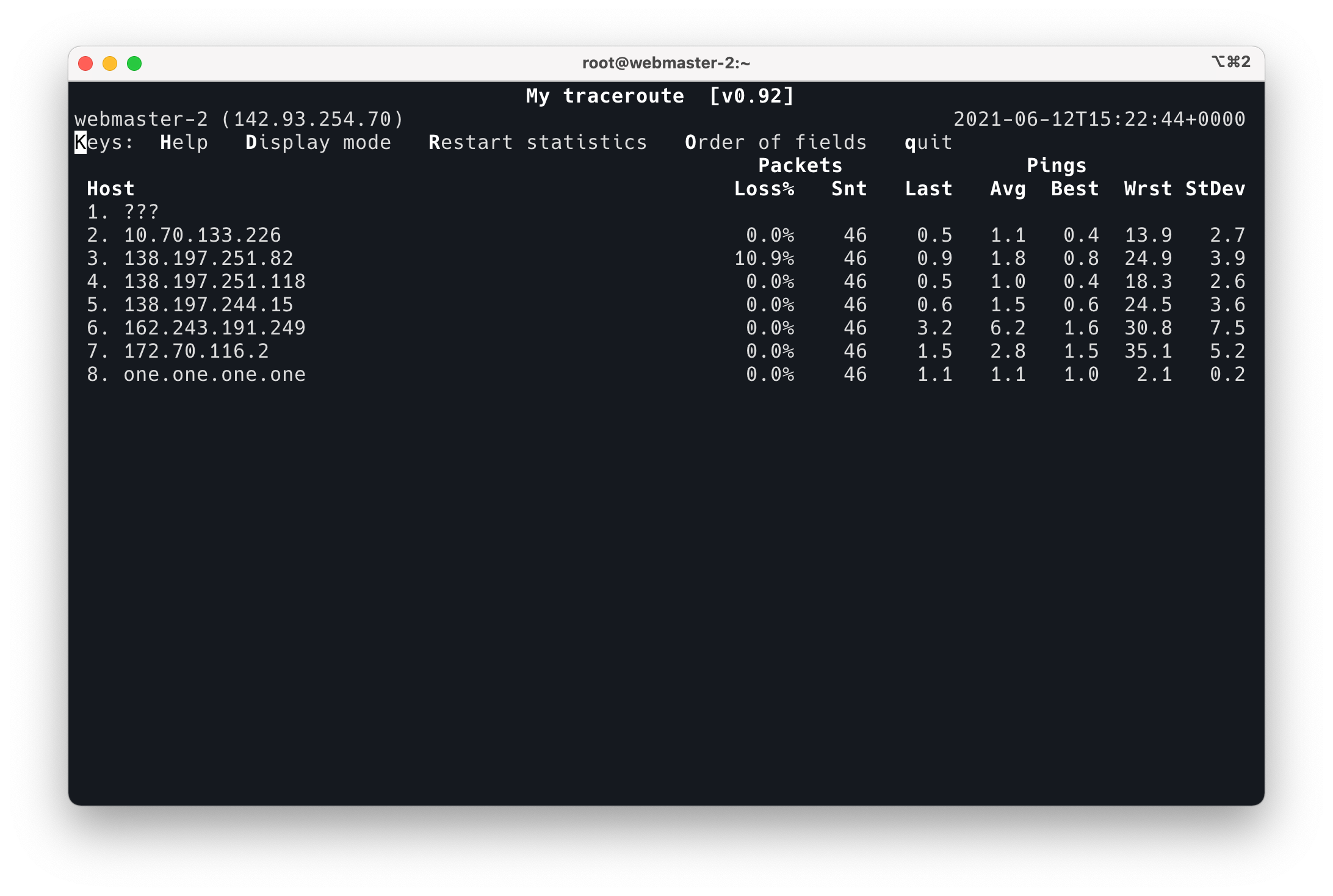
这里展示的是从一台 DigitalOcean 的机器上到 1.1.1.1 这个 IP 的每一个 hop 信息。这个界面非常简单易懂,列出了从当前 IP 到目标 IP 之间要经过的 hop,中间的丢包率和 ping 出来的延迟。这个界面和 htop 一样,可以调整 Display Mode, fields 的显示顺序等,按照界面提示操作即可。
mtr 在使用的时候有一些需要注意的地方。
中间节点探测结果不一致问题
经常会看到中间某些节点丢包率比后面的节点还要高,这可能是中间节点对 ICMP 协议限速,导致中间节点可能看到 packet loss, 但是后面的节点没有,或者后面节点 loss 的数量比前面少。这种情况下,永远相信后面的节点。原理很简单,mtr 和 traceroute 的原理类似,都是发送 TTL=1,2,3,4,5… 的包探测出 IP 包的路由节点,然后去 ping 这些节点。所以这里的丢包率是从本地依次 ping 这些节点的丢包率。假如中间某个节点发生了丢包,那么它后面的节点一定会丢包,因为后面节点要可达必须经过中间的节点。像上面图中那种情况,第 2 个节点有 10% 的丢包率,后面的反而没有,说明节点 2 并不是真正地丢包,只是对你的 ping 丢了包,实际的包没有丢。
如果发生真正的丢包,会是这样子:
|
1 2 3 4 5 6 7 8 9 10 |
root@localhost:~# mtr --report www.google.com HOST: localhost Loss% Snt Last Avg Best Wrst StDev 1. 63.247.74.43 0.0% 10 0.3 0.6 0.3 1.2 0.3 2. 63.247.64.157 0.0% 10 0.4 1.0 0.4 6.1 1.8 3. 209.51.130.213 60.0% 10 0.8 2.7 0.8 19.0 5.7 4. aix.pr1.atl.google.com 60.0% 10 6.7 6.8 6.7 6.9 0.1 5. 72.14.233.56 50.0% 10 7.2 8.3 7.1 16.4 2.9 6. 209.85.254.247 40.0% 10 39.1 39.4 39.1 39.7 0.2 7. 64.233.174.46 40.0% 10 39.6 40.4 39.4 46.9 2.3 8. gw-in-f147.1e100.net 40.0% 10 39.6 40.5 39.5 46.7 2.2 |
从某一个节点开始,后面的节点都会发生丢包。
但是其实也可以看到,节点 3 和 4 5 比后面的节点的丢包率要高,说明真实的丢包率只是 40%. 即丢包率以后面的节点为准。
Latency 也同理,可能看到中间节点的 latency 比后面的要高。很显然,如果它 latency 真的高,那么后面节点的 latency 不能比前面节点的 latency 还小。所以 latency 不一致的情况下,以后面节点的为准。
网络设备转发包的时候,是直接在接口的 ASIC 芯片1上完成的。traceroute 的原理是发送 TTL=1 的包到各级的网络设备上,来迫使这些设备收到 TTL=1 的包之后,回复 ICMP 来暴露自己的 IP 地址,用于 debug。但是 TTL=1 的包的处理无法简单的在 ASIC 芯片上处理,ASIC 芯片能做的事情很简单,但是速度很快。TTL=1 的包通常要送到 CPU 来处理(所谓的 slow path),所以网络设备在回复 ICMP 的包时候,可能比转发正常的数据面流量速度要慢很多。
来回路径不一致的问题
发送过去的包的路由,和返回的包的路由,并不总是一致的。所以如果有条件的话,最好从两端都使用 mtr 进行诊断,或许会发现不一样的线索。
但是对于 Latency 来说,如果两边的路由一致,但实际只有在一边去向另一边的时候有延迟,那 mtr 是无法检测出来的。因为 mtr 本质上是用 ping 来检测延迟,ping 只能得到来回总共的时间,不能得到单边的时间。
中间出现 ??? 的情况
如上图,第一个节点。有时候 mtr 的报告中会出现 ??? 的标志,这是因为 traceroute 拿不到中间节点的信息,一般是因为这个节点被设置成不回应 ICMP 包,但是能够正常转发包。所以这种情况下即不能拿到 IP,也无法测试丢包率,延迟等。
使用 tcp
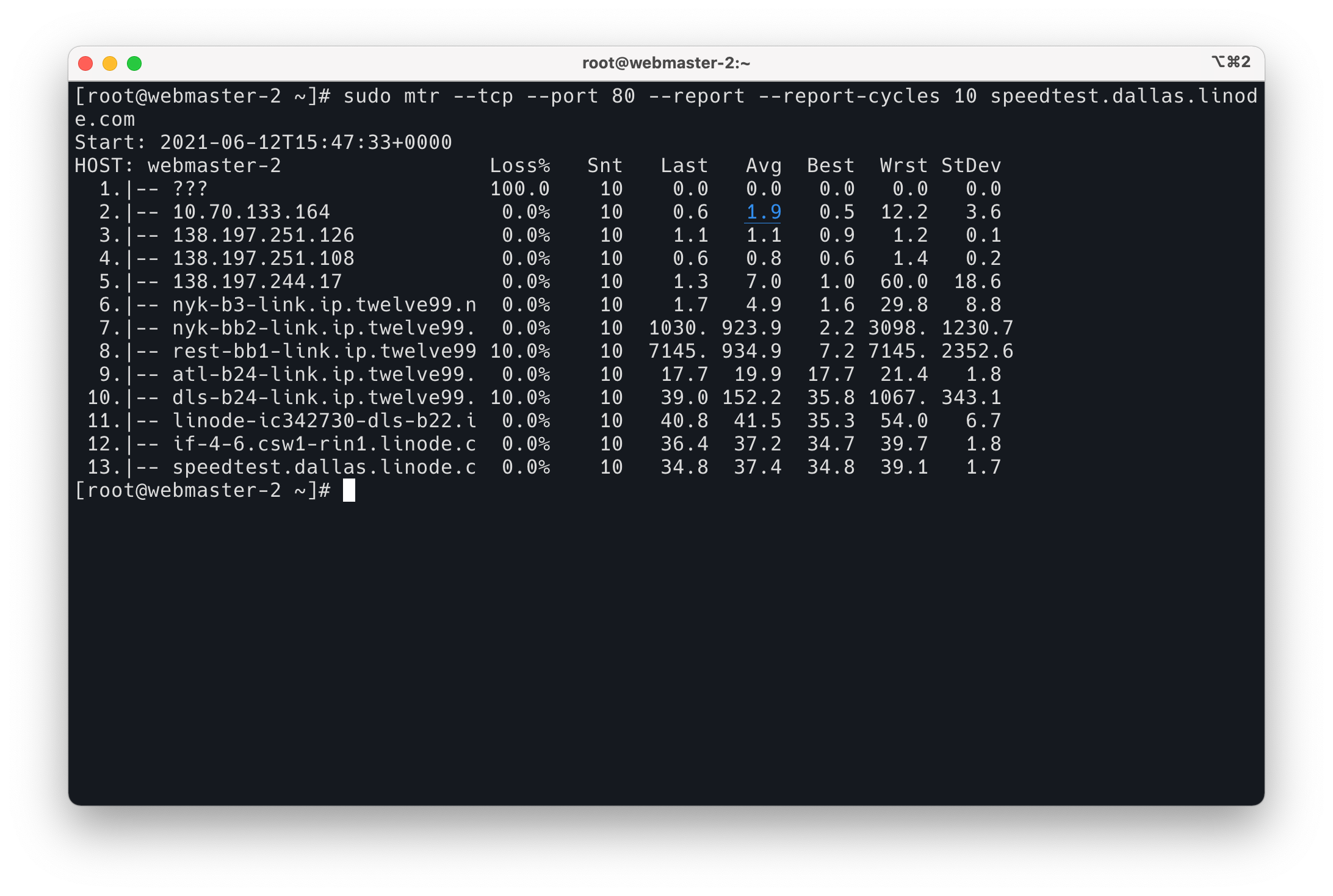
现在的 mtr 也支持通过 tcp ping 了,发送 SYN 包进行探测,原理和 ICMP 包的 TTL 是一样的。
但是使用 --tcp 的时候,会经常看到中间的链路丢包问题,TCP ping 看起来并不是很文档,不知道是什么原因造成的。可以借助上文提到的惊讶,如果只是中间链路丢包而后面的链路不丢包,可能是误报。
不要去排查每一个网络问题!
不要去试图明白每一次丢包背后的原因。网络协议本身就是设计成有很多容错和降级的。任何时候都有可能发生路有错误,网络拥塞,设备维护等问题。如果 mtr 显示丢包率有 10%,一般不会有什么大问题,因为一般的上层应用协议都会处理好这部分丢包。如果去排查每一次网络丢包问题,只会徒增人力成本。
(真希望我亲爱的开发同学们能理解这一点)
参考资料:
- Diagnosing Network Issues with MTR
- Traceroute: Finding meaning among the stars
- Understanding the Ping and Traceroute Commands
Pingback: 用 Wireshark 分析 TCP 吞吐瓶颈 | 卡瓦邦噶!
Pingback: 探测 TCP 乱序问题 | 卡瓦邦噶!
> 但是很多设备不会回应 TCP 包,所以会看到大量的 packet loss, 带来很多误导。
这一段有什么依据吗?中间设备回复的也不是 TCP 而是 ICMP,很多设备不会挑造成 Time Exceeded 的是什么包。
有道理,实际使用的时候(尤其是在公网),TCP TTL到0收到的 ICMP 会比 ping 收到的 ICMP 不稳定很多,但是可能不是网络设备的配置造成的,不知道是什么原因。我先修改一下原文吧。