这篇文章是火焰图阅读的简明教程。
火焰图是我们用来分析性能的可视化工具。很多 profile 工具输出的信息都非常多,是一个巨大的文本,在这个文本中,找到性能瓶颈,会比较困难。但是如果画出来一张图,可以一下就看到问题所在。
火焰图是 Brendan Gregg 发明的。使用官方的工具 FlameGraph,可以将文本渲染成 svg。如下。
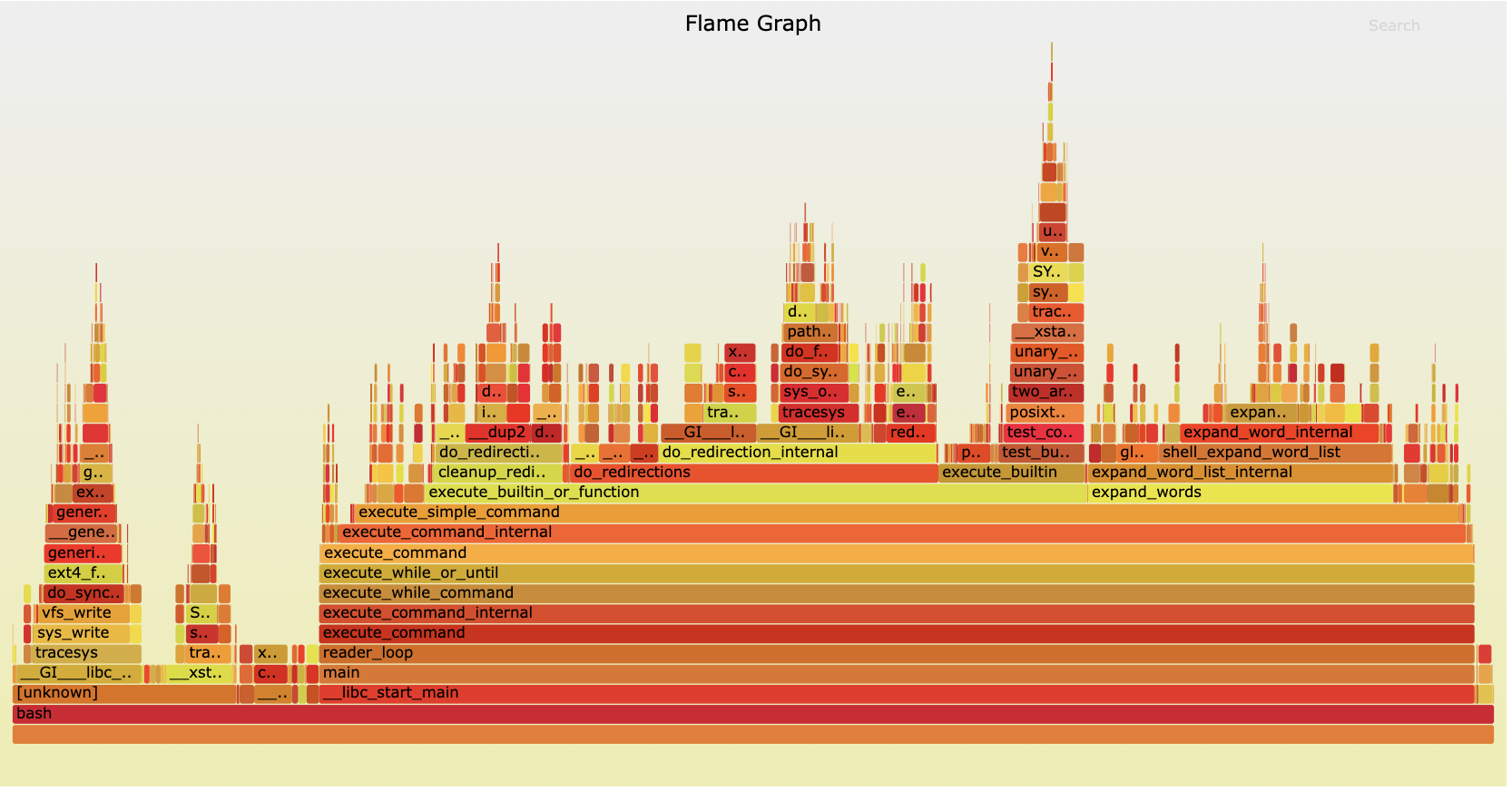
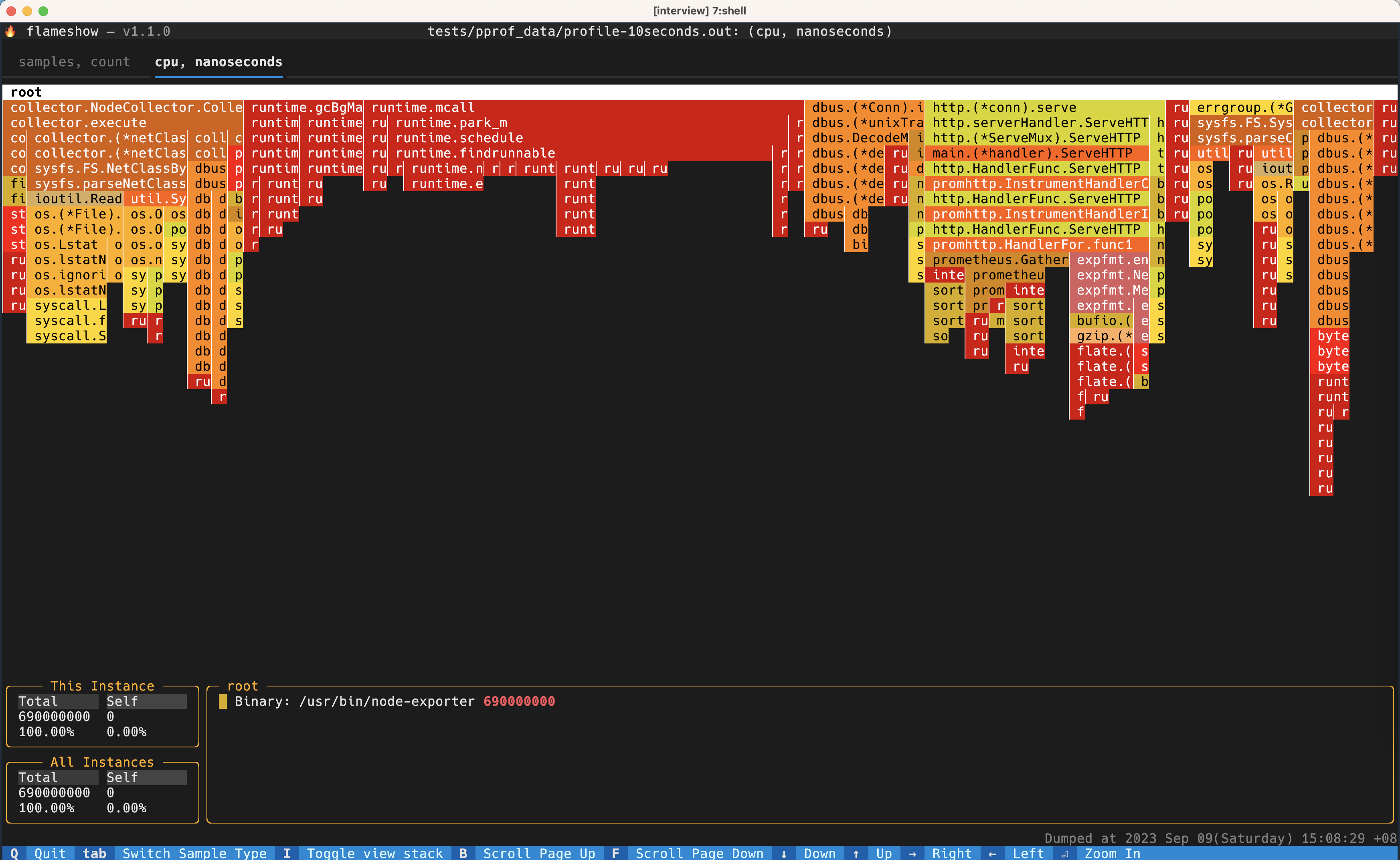
现在也会有其他的工具能渲染出来类似的图了,比如 golang 的 pprof 现在内置了一个新版的火焰图预览工具,在线的 speedscope 也可以渲染。我最喜欢的是 Flameshow,一个终端工具,可以直接在终端用字符渲染出来火焰图,设计的非常精妙。(其实就是我自己写的)。由于是我自己写的,那么下文我就以 Flameshow 来做展示的例子了。
阅读方法
火焰图作为一个可视化的工具,着重表达的信息是:父子之间的关系,每一个块的占比。
火焰图有从下向上的和从上向下的,本质是相同的,只是方块之间的关系方向不同。从上向下:下面的方块是上面的子块;从下向上:上面的方块是下面的子块。
主要信息有(以从上到下为例子):
- 每一个方块,都是一个函数,方块的宽度,就表示函数消耗的时间占比。(如果是内存火焰图,那就表示的这个函数申请的内存占比。)所以我们看火焰图,主要去找最宽的一个方块。
- 上下堆叠在一起的是表示函数调用。Y 轴表示调用的深度。
火焰图一般是支持交互式的,svg 和 flameshow 都支持点击其中一个 function,来放大。如下例子:

标记的是,最开始调用的函数是 collector.NodeCollector.Collect.func1,然后这个函数的所有时间都在调用 collector.execute,以此类推。到下下面的 os.(*File).readdir,其中有一大部分是在调用函数 os.Lstat,然后其余的时间花在了 os.direntReclen。
很多人对火焰图容易有一些误解,这里着重说明一下:
- Y 轴的深度一般不是问题。我们用火焰图主要是排查性能问题,是要找消耗时间长的地方。调用深度很深,但是没花多久时间,一般不要紧;
- 颜色(几乎)没有意义。不是说颜色越深时间越久。颜色只是为了区分出来不同的块而已。一般会将相同名字的函数都使用同一个颜色,这样,即使它们分散在不同的 stack 中,也能清晰看出总时间比较高。从 FlameGraph 的源代码也可以看出,颜色是根据 function 名字随机生成的。但是有一种优化:比如对于 Java 的 JVM 来说,可以用不同的红色表示 Java 代码消耗的时间,可以用黄色表示 Kernel 消耗的时间,用蓝色表示 JIT 时间。但是不同的红色,红色深浅,还是没有什么意义的。
- 方块之间的顺序没有意义。因为火焰图的生成方式(后文介绍),和渲染方式(一般会将同名字的方块 merge 在一起,方便阅读),导致火焰图方块之间的顺序是没有意义的。不代表函数调用的顺序。
火焰图的本质是旭日图(Sunburst Graph)
你有没有发现,主要表示占比,又能表示占比之间的关系,是不是跟某一种图很像?
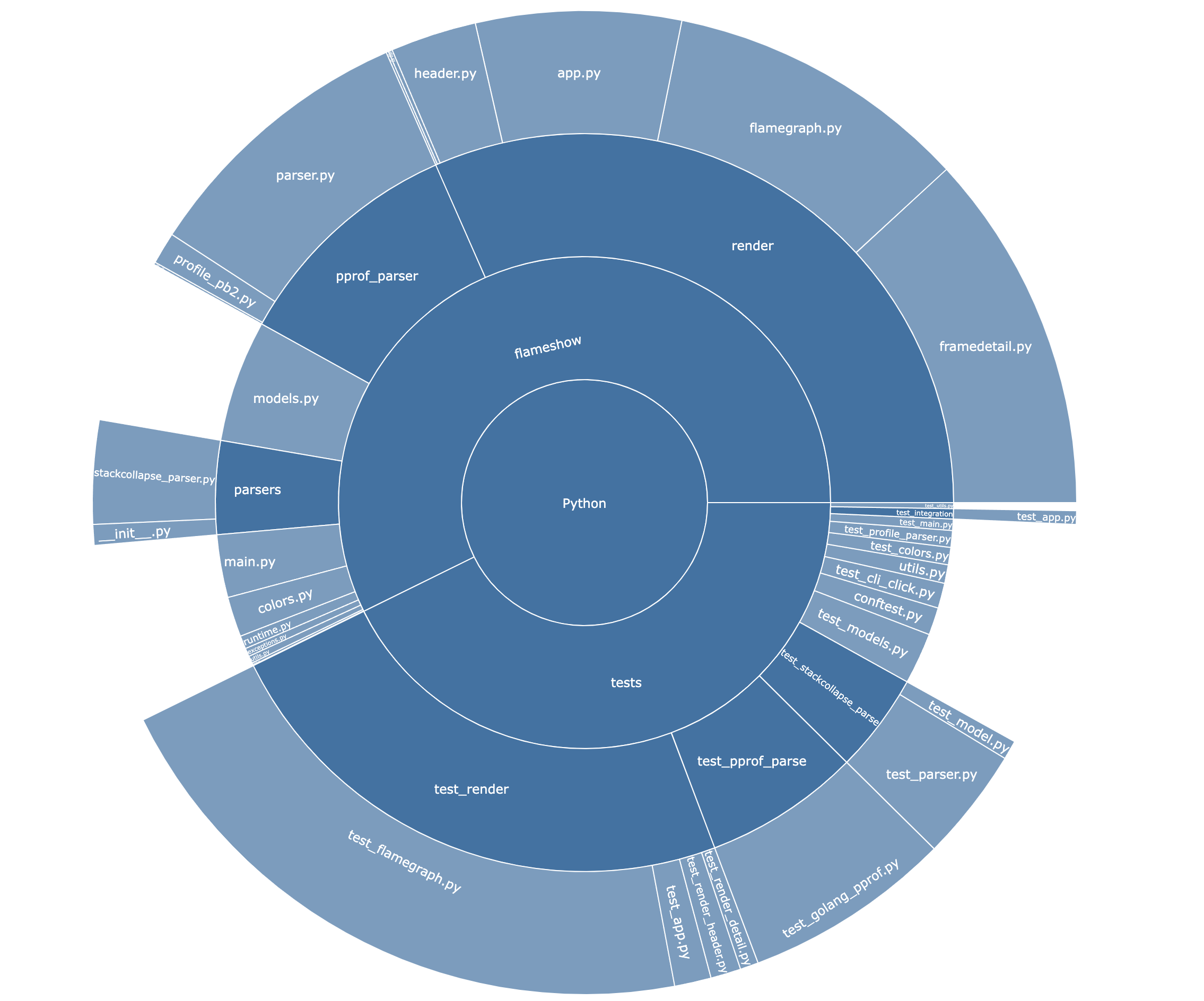
是的,其实火焰图的本质就是拉平了的旭日图。上图是我用 tokei-pie 渲染出来的代码仓库中不同文件夹、文件的行数占比。打开一个新的项目的时候可以轻松找到核心代码。
火焰图的生成和格式
火焰图的生成主要依赖 profile 工具,目前很多工具都支持了,比如 py-spy, golang 的 pprof.
生成的原理大致是去扫描程序的内存,主要是内存的 stack 部分,对 stack 做一个快照。如果扫描了 10 次,其中 function1 出现了 3 次,function2 出现了 6 次。那么它们的宽度占比就是 1:2. 很多 profile 工具就是如此工作的,不是 100% 精确的,但足以让我们分析性能问题了。
生成的格式一般是 stackcollapse 格式,这是官方的一种定义。比如如下的文本:
|
1 2 3 4 5 |
a;b;c 1 a;b;c 1 a;b;d 4 a;b;c 3 a;b 5 |
每一行就代表一个 stack,数字代表整个 stack 的占比。我们要把所有的 stack 相同层级相同名字的 merge 起来,最后就变成下面这样:

另一种常见的格式是 pprof 的格式。虽然是 golang 最先开始用的,但是设计的(我个人认为)比较好,也是开源的,protobuf 定义,所以很多工具也支持输出这种格式了。
Continuous Profiling
持续 Profiling 也是我比较感兴趣的一个领域,很多 APM 工具都已经支持了。比如 Datadog 和 Grafana。简单来说,就是不断地对线上部分实例进行 Profile,然后对结果不是简单的展示,而是收集起来。将它们的 stack 都合并起来,做成一个由多个实例的 stack 组成的 Flame Graph,就可以找到集群层面的性能热点了。
另外一个用处是,在发布新版本的时候,可以在灰度的时候,检查新版本的 Flame Graph 和之前的,看有没有引入新的性能热点。
相关链接
- https://www.brendangregg.com/flamegraphs.html
- https://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html
- https://queue.acm.org/detail.cfm?id=2927301
- https://youtu.be/6uKZXIwd6M0
- https://youtu.be/6uKZXIwd6M0
- https://www.webperf.tips/tip/understanding-flamegraphs/
- https://github.com/jlfwong/speedscope/wiki
- https://www.speedscope.app/
很棒的分享,特别是关于火焰图关注宽度而不是颜色上,这点非常言简意赅,我尝试按照上述描述分析了实际项目,发现还有些出入,如果能够补充一个实际案例那将是极好的;
比如我在尝试分析自己业务中的heap指标,顶部显示120M内存,但实际从docker stats上看到是700M相差还是比较大,尽管我已添加了gc参数
PS:该业务实例刚启动时的确只有几十M内存,但会随着时间推移启动更多goroutine,内存会逐渐增加,anyway 对于上面火焰图的内存和实际containers的显示如果能够分享下就更好了~
期待回复
Hi,内存管理 docker 看到的内存和 pprof 报告的为什么不一样?因为一个(pprof)是在 runtime 里面进行统计,一个是在系统层面统计,可能会有差别吧。找到一篇文章:https://povilasv.me/go-memory-management/ 。
火焰图只是一个展示工具。container 中的进程和普通的进程也没有什么区别。
pprof 能够报告给你一段时间内申请内存的地方,以及 in use 内存的比例,这些信息可以当作提示来找到内存泄漏的地方。
很开心能够这么快速的收到回复,再次感谢;
通读了分享链接中的内容,感觉是非常有深度的关于go 内存管理的讲解文章,按照描述我对照了自身业务,docker stats展示的更接近于RSS内存值(约650M),个人关注这个值的原因是在用mesos部署业务时有一个内存分配阈值,超过后会被OOM掉,所以感觉这里的判定标准应该是RSS值,而不是VSZ之类的。
最后,其实这里并没有内存泄漏,之前排查过是因为使用sarama驱动producer访问Kafka时,因为不合理的partition设置导致,需要启动与之匹配的goroutine,而这个过程是一个惰性加载,会随着向Kafka发送数据的叠加态,逐渐的增加,最后个数与partition个数match后停止增长(历史遗留原因)
不客气,欢迎交流。
一般只关注百分比,总数因为统计的角度不同是可能有差别的。