Prometheus 设计的 Pull 模式监控非常优雅:程序开发者只需要做一件事情,暴露出来一个 HTTP 服务,/metrics 返回当前程序的 metrics,就可以了。然后 Prometheus 会定时过来请求 metrics 数据,存储到 TSDB 中。程序只需要关注一件事:暴露 (export) metrics。
如果一开始接触的监控就是 Prometheus,可能觉得这种模式非常自然,符合直觉(就像第一次接触 SCM 就是 Git 会觉得 Git 也很符合直觉一样?)。但是 Prometheus 出现之前,很多公司的做法,是运维人员清洗日志,按照日志特定位置的关键字聚合成 metrics,然后画图,非常麻烦。最大的问题是运维人员会看不懂日志——为了节省空间,很多日志都没有 key,只有分隔符和 value。依稀记得,我的上一家公司为了解决这个问题,还启动了一个项目,叫做“监控代码化”。这和 Prometheus 的想法如出一辙:让开发者来暴露 metrics,因为开发者是最懂程序的。
但问题是,开发者却不是最懂监控的。
我们的监控系统经历过很多次 overload,一般都是伴随着应用发布。开发者不清楚修改 metrics 会对监控系统本身带来多大的压力。我发现就连 Prometheus 的文档也没有专门说明这部分内容。所以这篇博客就尝试介绍一下 metrics 采集量计算的逻辑和优化的方法。
首先,在代码中暴露 metrics 的时候,每一个新的 label value 意味着新的 metrics,比如,下面这三个是三个不同的 metrics。
requests_total{host="example.com", path="/foo/bar"} 10
requests_total{host="example.com", path="/foo/bar1"} 20
requests_total{host="example.com", path="/foo"} 30即使它们的 metric name 相同,也并不意味着什么,这只是给人类看的语法糖。它实际存储起来像下面这样:
{__name__="requests_total", host="example.com", path="/foo/bar"} 10
{__name__="requests_total", host="example.com", path="/foo/bar1"} 20
{__name__="requests_total", host="example.com", path="/foo"} 30代码中(SDK, 比如 golang SDK)一个 metric实例 可能产生多于一条 metrics,比如 Histogram 会产生 10 个 _bucket,加上一个 _sum 和 一个 _count。
添加 Label 的情况
如果添加一个新的 label,新的 label 会和原来的 metrics 做笛卡尔积。比如,新添加的 label 是 HTTP 的 status code,添加之后可能会变成下面这样:
{__name__="requests_total", host="example.com", path="/foo/bar", status_code="200"} 10
{__name__="requests_total", host="example.com", path="/foo/bar", status_code="403"} 10
{__name__="requests_total", host="example.com", path="/foo/bar", status_code="500"} 10
{__name__="requests_total", host="example.com", path="/foo/bar1", status_code="500"} 20
{__name__="requests_total", host="example.com", path="/foo", status_code="500"} 30
{__name__="requests_total", host="example.com", path="/foo", status_code="200"} 30这里要格外注意,一个新的 label 不意味着成倍的 metrics,而是笛卡尔积。或者这么想,添加的 每一个 label 都可能将原来的 metrics 拆成多个 metrics。
例子1: 假设原来有 10 条 metrics,新添加了一个 label 叫做机器的 IP,那么新的 metrics 还是 10 条,因为每一个 metrics 在采集的时候就会带有 instance label;
例子2: 假设原来有 10 条 metrics,metrics 原来有 path 和 query_params (HTTP协议的),然后新添加一个 label 叫做 full_url 含有 path 和 query_params, 那么新的 metrics 还是 10 条,因为每一个原有的 metric 和新的 metric 都是一一对应的;
例子3: 假设原来有 10 条 metrics,新添加的一个 label 叫做 client port,那么新的 metrics 可能会是 10 * 65535 条(先不考虑 reserve port). 因为 port 有 65535 个不同的的值,并且于原来的 label 都没有关系,所以每一个 label 都被拆成了 65535 个。
这就告诉我们:那些无法枚举,程序不能控制的 lebels,千万不能加入到 metrics 中。
Label 必须是可以枚举的
不可枚举的 metrics 比如,url,IP,等等。或者客户端传递过来的参数。即使参数可能是一个有限集,但是 client 如果有办法不按照这个集合来传,换句话说,你控制不了,那就不能放到 label 中去。否则,会导致 TSDB 的索引快速膨胀,让查询速度急剧下降。
TSDB 是专门存储时序数据的数据库,一条 metrics 在历史时间的数据,它能很快找出来。但是如果要找 100万条 metrics,查询就比较慢了。我们要尽量减少一次查询涉及的 metrics 数量。
优化 Metrics 输出
有了上面的背景, 我们在添加 metrics 的时候,就可以考虑怎么即能够满足监控需求,又可以添加最少量的 metrics 完成需求。
比如我们在统计延迟的时候,Histogram 一下子就是 12 条 metrics。假设我们想在像看到 cluster 维度(有10个)的延迟,也想监控 API 维度(有20个)的延迟,但是我们不需要监控每一个 API 在每一个 cluster 的延迟。
很多人会这么写:request_duration_bucket{cluster='A', API='user', le='10'},这样的话,总数就是 cluster * API * 10 (bucket) = 10 * 20 * 10 = 2000 个 metrics。
但是如果我们暴露两个 metrics:
request_duration_cluster_bucket{cluster='A', le='10'}request_duration_api_bucket{api='user', le='10'}
那么总数就是 cluster * 10 bucket + user * 10 bucket = 200 + 100 = 300 个 metrics,少了一个数量级。
另一种情况是,比如在七层网关上的 metrics,我们需要:nginx_instance, status_code, upstream_ip, path, 数据可能达到千万级别,所有的这些 label 都是需要的,用来定位问题。
我们有两个面板:
- 一个是汇总查询,只查询所有的实例上面的 status_code,用于发现问题;
- 一个是详情查询,需要查询 instance, upstream, path 等等,用于在发现问题之后定位问题;
将这些 label 全都暴露出来,就可以满足两个需求了。但是现在出来一个问题,就是在做需求 1 的时候,由于 metrics 的总量太大了,监控上将他们聚合起来的成本很高,查询速度很慢。
这时候,添加一个新的 metrics 就可以解决问题:requests_by_code_total{status_code="200"}。它只有一个 label,所以 metrics 的量很少,查询速度很快。
这样也可以节省成本,虽然有些反直觉:添加 metrics 也可以减少成本。因为成本不仅仅是存储成本,还有查询计算的成本。查询成本也很可观,因为这个 metrics 通常可能要每 10s 就查询一次,用来做 alerting,判断系统是否正常。
我觉得如果 metrics 经过精心的设计,可以解决大部分的规模问题。但是有时候程序的代码不是我们能控制的,下面还有一些方法可以对付一下。如果代码改不了,可以考虑下下面的方法。
Recording rules 和多级 Recording rules
对于 metrics 太多导致查询起来太慢,可以用 Prometheus 的 recording rules 的方案。核心思想是,既然用户查询的太慢了,那么我就让一个聚合程序每 10s 查询一次,然后将查询结果写入到 TSDB 中,这样,用户在使用这个 metrics 的时候,查询结果已经存在了,必然很快。
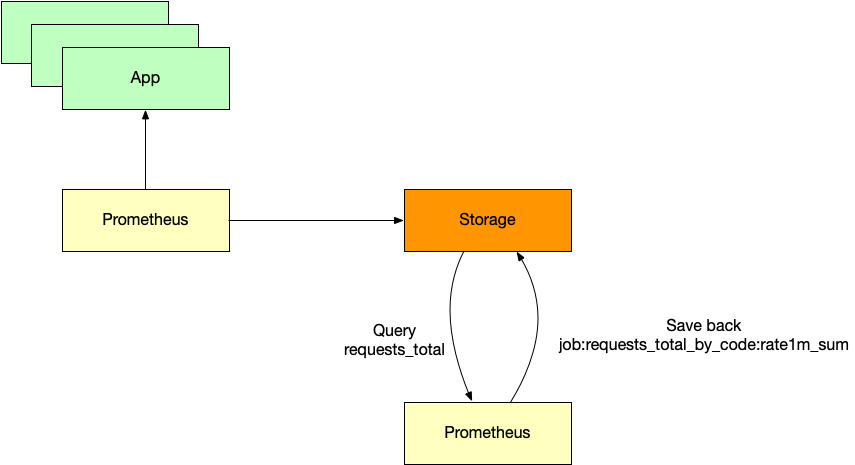
有时候 metrics 太多以至于查询根本就查不出来(recording rules 本质上也是一个查询)。还有一种方法是多级聚合。比如第一级分成 5份,每一份保存好聚合结果之后,第二级再跑一次 L2 聚合。
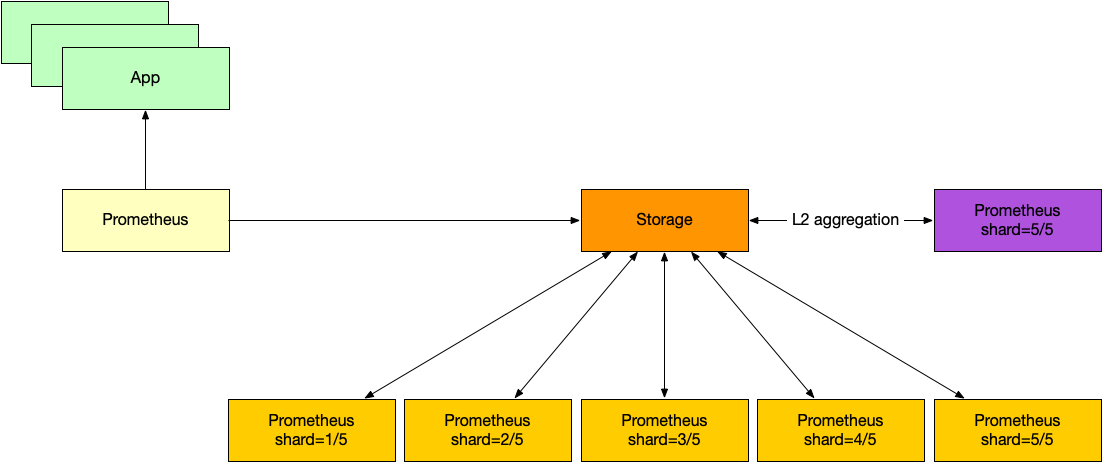
这样做的缺点,一个是时效性低,数据有延迟。另一个就是查询造成的压力不减反增——每次查询成本都很高,以前是查询慢,现在查询快了,但是每分钟即使没有人用也要跑查询。
这个方案直觉上就有一个缺点:数据的流向,是首先抓回来存到存储,然后从存储查询出来,计算,然后再写到存储。数据多了一次出来再进去。那我们能够抓到 metrics,计算聚合,然后存储吗?
Streaming Aggregation
我觉得这个想法是合理的,这样数据只进入到了存储一次。
但是 Prometheus 没有这样的功能。我发现 Uber 的 m3db 有,他在聚合 metrics 方面就是在采集的时候计算的。这样开发者暴露再垃圾的 metrics 我们都可以得到想要的聚合了。
m3db 的问题是,它的文档是在太乱了,文档组织毫无逻辑,光运行起来就废了好大的功夫。跑起来之后发现性能也很差,原来的一个 vmagent 可以抓取的 targets,用上 m3db 之后连 1/6 都处理不了。这文档也没有让人想要贡献的欲望,索性作罢。
VictoraMetrics 去年支持了 stream aggregation。支持让 vmagent (VictoriaMetrics 系统中负责采集 metrics 的组件)在采集 metrics 的时候进行聚合。我们在一些场景下用了这个功能,资源使用很少,效果不错。
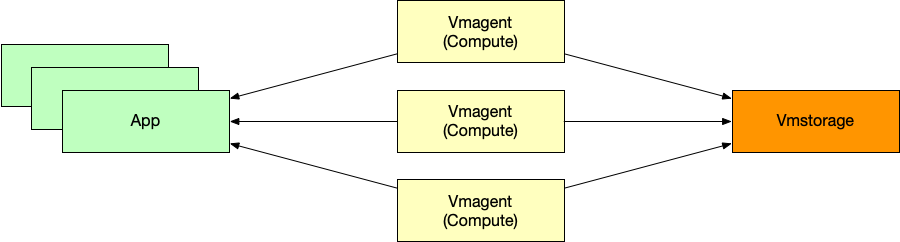
它有一些缺点:只支持有限的聚合函数,不可以叠加。比如,用了 increase 之后就不可以再用 sum 了。但是 increase 又不算是聚合,原来有多少用了 increase 就还有多少。这样的话,这个功能就很鸡肋了。我发 issue 咨询了下,意外地得知,VictoriaMetrics 里面的 sum 居然是处理了处理了 counter reset 的,所以说,可以直接用 sum 聚合,sum then rate 也是没有问题!他们提的另一个方案是部署多个 vmagent,每一个都跑一个 stream aggregation:vmagent1 -> vmagent2 -> … -> vmagentN。
另一个缺点是,每一个 vmagent 都会得到一份聚合之后的数据,但是问题不大,已经将 metrics 减少很多倍了。在配置的时候,要给每一个 vmagent 的 stream aggregation 规则都加上一个 vmagent 编号的 label,否则的话,多个 vmagent 可能得到完全相同的 metrics 名字,这样数据就不对了。
大牛,厉害
xintao现在在哪啊,最近也在找工作,想参考一下,多了解些团队。不好意思在x上问你,来你博客问了。
让我想起了这篇 blog,还有一个计算器可以大致计算内存占用量 https://www.robustperception.io/how-much-ram-does-prometheus-2-x-need-for-cardinality-and-ingestion/
赞,很有用
说到优化,Prometheus v2.40 实验性支持的 native histograms 一定程度上解决了 buckets 精度和指标数量爆炸的两难问题。不过由于还是实验性功能,整个 Prometheus 生态对它的支持还不是很好。 https://www.youtube.com/watch?v=TgINvIK9SYc
是不是跟 https://docs.victoriametrics.com/keyconcepts/#histogram 有点像。
native histograms 的精度或者说压缩率要好很多,原理上是有区别的。