之前在博客介绍了 Linux From Scratch, 最近发现 LFS 已经有新的版本 10.1 了,周末打算重新编译一下。
LFS 在首页推荐了两个教程,可以学习编译软件的一些基础常识,一个是 TLDP 的 Building and Installing Software Packages for Linux,另一个是 Beginner’s Guide to Installing from Source,相当于是 TLDP 的简略版。边学习边记了一些笔记和总结。那这篇博客,就相当于是简略版的简略版吧。
软件的开发和发行
一个操作系统除了内核,还需要成千上万的软件才能真正去完成一些工作。专有系统一般会帮你管理这些软件,开源系统的软件则是由世界各地的开发者贡献的。这些软件通常不仅可以在 Linux 上使用,只要版权允许,也可以在 BSD 等系统使用,如果版权允许,有些还可以在专有系统运行。比如 Mac, Solaris 系统等。
开源软件发行中有两个常见的术语:
- 上游(Upstream): 通常指的是软件的原作者;
- 下游(Downstream): 通常指的是发行版,和用户;
大部分的开源软件都会开放一个版本控制系统管理的代码,任何人可以匿名下载代码,比如从 Github clone. 使用版本管理软件下载代码包含软件的开发历史(commit),可能会比较慢,软件在发布(release)的时候通常会将代码打包提供下载,这样下载就不包含代码提交历史,所以下载会更快一些,也能给世界节省一些带宽,减缓全球气候变暖。也有一些软件没有开放版本控制,只有定期打包开放的代码,这种就只能下载不带历史的源代码了。
发行版,Binary,和编译
Linux (以及其他的操作系统)有很多的发行版,这些发行版所帮你做的一个重要的事情就是给流行的软件打包。让你可以直接从 apt/dnf 等 package manager 下载安装软件。这些 package manager 有些是直接分发 binary 的,这意味着你在安装的时候直接下载下来放到 $PATH 下面就好了,并不需要自己编译。
Package manager 带来的好处是:
- 方便:要找什么软件直接从它们提供的 repository 下载就好了;
- 安全:package manager 在下载的时候会自动校验 md5,发行版的开发者也会时刻关注安全问题,所维护的打包软件会及时地做安全更新;
但是另一方面,发行版要维持一定的稳定性。比如你在特定版本的 Ubuntu 上,从官方的 Repository 就只能安装到特定版本的 Python,而不能安装最新的。(当然也有发行版的策略是永远提供最新版的软件。)
在这种情况下如果你想使用最新版的软件,就需要自己编译了。
另一种可能需要自己编译软件的情况是定制。一般开源软件会提供一些参数,比如删掉不必要的功能。这些定制都是要在编译阶段配置的,发行版要兼顾大部分的用户,所以一般都会尽量打开所有的 Feature,如果你需要特定的配置,就需要自己编译了。
自己编译软件的时候也要注意不要搞乱了你的 package manager, 后面可能出现意想不到的错误。最好的方法是阅读对应的 package specification 然后使用 package manager 来编译和安装软件。
源码下载和安全
一般的软件会提供 http 服务或者 ftp 服务让大家下载。大部分人应该都会从网上下载东西,在浏览器里面使用右键,另存为,就可以了。在终端上可以使用 wget 程序或者 curl 来下载。
除了从官网下载之外,一般还会有很多 mirror,其实就是散步在世界各地的备份。这样一来可以备份软件,而来可以让用户就近下载,节省原服务器的带宽,也节省整个世界的带宽。
tarball
之前介绍过文件系统。可以知道,不同的文件系统对于目录(文件夹)和文件的组织方式并不相同。所以在互联网上传输的一般是打包成一个的文件而不是文件夹。
文件打包说白了就是将所有的文件 append 到一个文件中,然后创建一个 “index”,里面包含了所有的文件信息,比如每个文件的名字,offset,length,index 等等,方便不必解包就可以知道里面都有什么,甚至可以从中提取出来某一个文件而不必完全解包。
tar 程序是最常见的打包程序(参考之前的这篇博客)。名字的意思是 “tape archive”,虽然现在文件已经都不存储在 tape 上,而是 disk 上了…… 用 tar 打包的文件通常叫做 tarball. 用 tar 打包可以保留操作系统的权限信息,以及文件的 owner id 等信息。
因为源代码都是文本,压缩比率非常高,很适合压缩之后传输。tar 仅仅是打包,一般打包之后还会进行压缩。常见的压缩有:
- gzip: 文件后缀是
.tar.gz表示是一个使用 gzip 压缩之后的 tarball - bzip2: 后缀一般是
.tar.bz2 - xz: 后缀是
.tar.xz - …
tar 现在的版本已经非常智能了,可以自动识别文件然后调用对应的解压工具进行解压,比如这么使用:
|
1 2 3 4 5 6 7 8 9 |
# Modern GNU tar options. This works for files compressed # with gzip and bzip too tar --extract --file filename # Same as above tar -xf filename # Same as above. Leading "-" is optional tar xf filename |
但是 tar 是一个非常古老的程序了,是否支持自动解压取决于版本,参数的使用也取决于版本。本着 Unix 的哲学:一个工具只做一件事情。我比较喜欢这么用,解压交给解压工具,解包交给解包工具:
|
1 2 3 4 5 6 |
# explicitly decompress gzip2-compressed file then # pass uncompressed result directly into tar gzip -cd filename.tgz | tar xf - # same as above, but for bzip2-compressed files bunzip2 -cd filename.tar.bz2 | tar xf - |
tar 在解压的时候,如果在当前目录存在重名文件,会直接覆盖掉。一般在软件打包的时候,会将所有的内容放到一个目录内,这样你解包的时候所有的内容也会都在一个新的目录内。但不排除有些软件在打包的时候没有这么做,所以盲目地解压网上下载回来的软件可能搞乱你的当前目录。有两种方法可以避免:
一个在解压之前先看看里面都有些啥:
|
1 2 3 4 5 6 7 8 9 10 11 |
# Modern GNU tar tar --list --file filename # Same as above tar -tf filename # Same as above. Leading "-" is optional tar tf filename gzip -cd filename | tar tf - bunzip -cd filename | tar tf - |
另一个方法是创建一个新的目录,在里面解压:
|
1 2 3 |
mkdir untar-dir cd untar-dir tar xf ../filename |
解压的时候最好不要盲目地使用这些参数,这些参数可以改变解压的目标目录,很可能覆盖你的系统上的文件:
|
1 2 3 |
-C or --directory -P or --absolute-names --transform or --xform |
Windows 和 DOS 上经常用的一种压缩格式是 zip. 可以理解为 zip 是 tar + gzip. zip 不会保留文件系统的权限信息。对应的解压工具是 unzip.
即使使用 tar 解压,如果要保留文件的 owner 信息的话,需要使用 root 用户解压才行。但是有这种需求的情况非常少。非常不推荐使用 root 解包文件!这样可能覆盖重要的系统文件。
需要注意的是,http 服务和 ftp 服务都可能被劫持(即使使用 https 也有被劫持的可能),mirror 上存放的软件可能被篡改。所以下载回来的软件在安装之前一定要验证!
使用 md5sum 校验文件
大部分的文件下载都会提供一个 md5 校验码,我们将文件下载回来之后,只要将文件计算一个 md5sum,然后和官方提供的 md5 对比就可以了。注意这个 md5sum 必须从官方渠道获得,不能从 mirror 获得,否则就没有意义了。
以 Python 为例,在这个下载地址( https://www.python.org/downloads/release/python-395/ ) 有提供 md5 码:

下载这个 XZ compressed source tarball 然后校验:
|
1 2 3 |
➜ curl -OsSL https://www.python.org/ftp/python/3.9.5/Python-3.9.5.tar.xz ➜ md5sum Python-3.9.5.tar.xz 71f7ada6bec9cdbf4538adc326120cfd Python-3.9.5.tar.xz |
md5 一样,就可以认为文件是和官方完全一致的。
有些软件要下载多个文件,会提供一个 checksum-file, 可以使用这个命令,会自动根据 checksum-file 里面的文件逐个检查 md5:
|
1 |
md5sum -c checksum-file |
使用 GPG key 校验文件
有些软件是使用 GPG key 签名来证明软件来源。作者用自己的 key 对文件签名,然后将文件与签名文件一同发布,用户需要下载四个东西:
- 作者的 public key
- 作者的 gpg key 指纹,证明 public 的来源真实
- 软件包
- 软件包的签名
校验的步骤是:
- 导入作者的 public key
- 检查 public key,确认指纹,然后信任此 key
- 通过软件包的签名来验证软件包
这里依然以上面的 Python 源码包为例,来通过 gpg key 进行校验。
第一步,找到作者的 public key。在 https://www.python.org/downloads/ 可以看到,Python 3.8 和 3.9 的 Release Manager 是 Łukasz,我们根据这个 key 的地址将这个 key 下载下来。
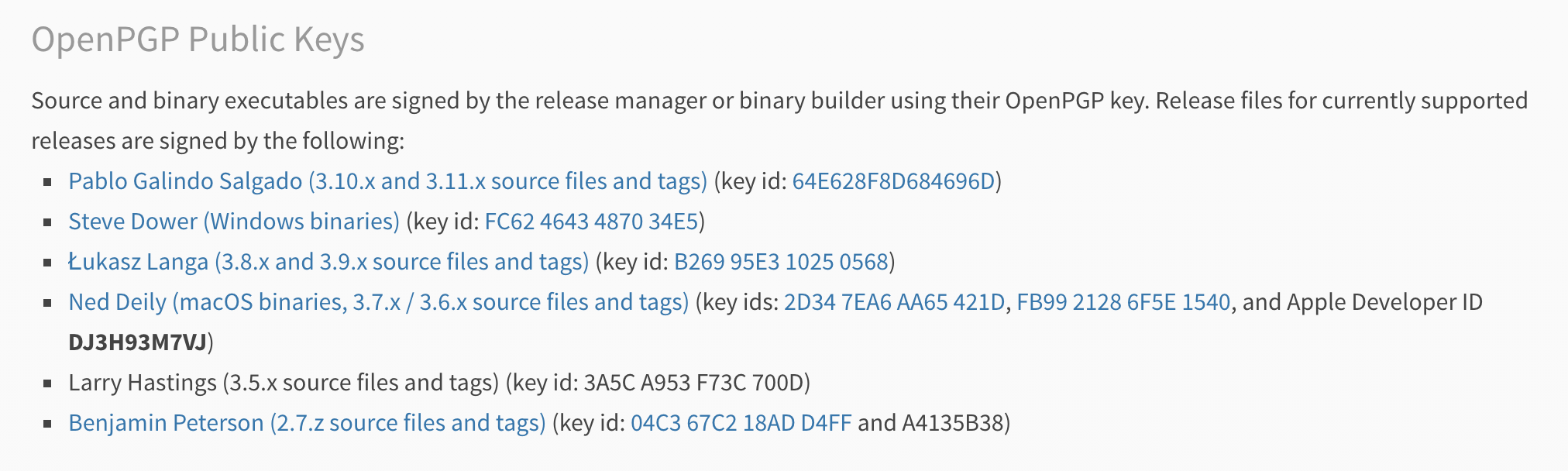
Python 官方开发者的 gpg key
|
1 2 3 4 5 6 7 8 |
➜ curl -sSL https://keybase.io/ambv/pgp_keys.asc | gpg --import gpg: key B26995E310250568: 40 signatures not checked due to missing keys gpg: Total number processed: 1 gpg: imported: 1 gpg: marginals needed: 3 completes needed: 1 trust model: pgp gpg: depth: 0 valid: 2 signed: 0 trust: 0-, 0q, 0n, 0m, 0f, 2u gpg: next trustdb check due at 2022-02-27 |
然后确认这个 key 的指纹,与作者公布的指纹做对比。发现一致,即可信任。
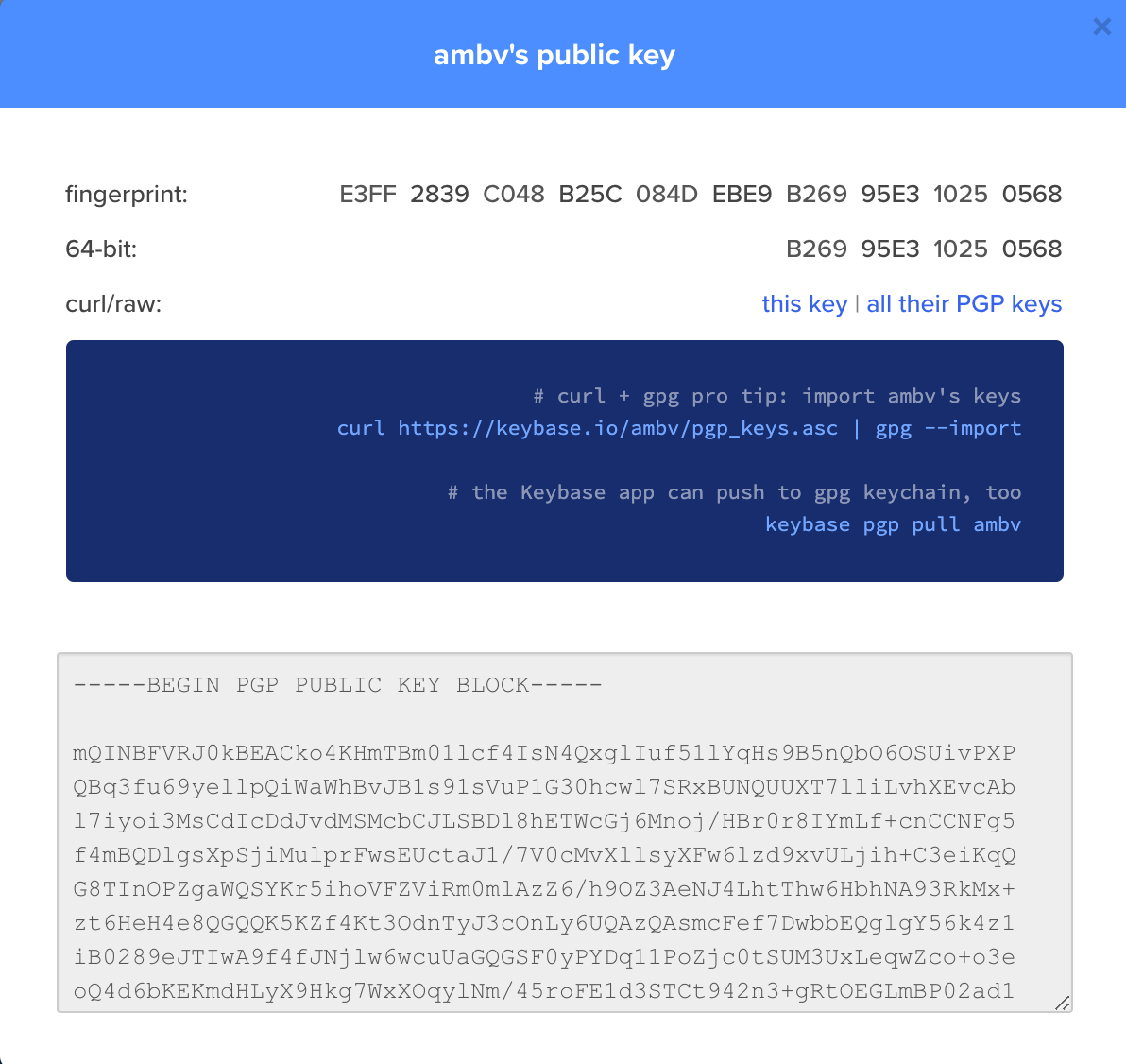
Łukasz 公布在 keybase 上的 GPG public key
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
➜ gpg --edit-key lukasz@langa.pl gpg (GnuPG) 2.2.27; Copyright (C) 2021 Free Software Foundation, Inc. This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. pub rsa4096/B26995E310250568 created: 2015-05-11 expires: 2025-05-11 usage: SC trust: unknown validity: unknown sub rsa4096/69ABE47DD03B1A3C created: 2015-05-11 expires: 2025-05-11 usage: E [ unknown] (1). Łukasz Langa (GPG langa.pl) <lukasz@langa.pl> [ unknown] (2) Łukasz Langa (Work e-mail account) <ambv@fb.com> [ unknown] (3) [jpeg image of size 24479] gpg> fpr pub rsa4096/B26995E310250568 2015-05-11 Łukasz Langa (GPG langa.pl) <lukasz@langa.pl> Primary key fingerprint: E3FF 2839 C048 B25C 084D EBE9 B269 95E3 1025 0568 gpg> sign Really sign all user IDs? (y/N) y pub rsa4096/B26995E310250568 created: 2015-05-11 expires: 2025-05-11 usage: SC trust: unknown validity: unknown Primary key fingerprint: E3FF 2839 C048 B25C 084D EBE9 B269 95E3 1025 0568 Łukasz Langa (GPG langa.pl) <lukasz@langa.pl> Łukasz Langa (Work e-mail account) <ambv@fb.com> [jpeg image of size 24479] This key is due to expire on 2025-05-11. Are you sure that you want to sign this key with your Really sign? (y/N) y gpg> Save changes? (y/N) y |
或者可以直接通过指纹 sign 这个 key,比上面的步骤要简单一些,是等效的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
➜ gpg --lsign-key "E3FF2839C048B25C084DEBE9B26995E310250568" pub rsa4096/B26995E310250568 created: 2015-05-11 expires: 2025-05-11 usage: SC trust: unknown validity: full sub rsa4096/69ABE47DD03B1A3C created: 2015-05-11 expires: 2025-05-11 usage: E [ full ] (1). Łukasz Langa (GPG langa.pl) <lukasz@langa.pl> [ full ] (2) Łukasz Langa (Work e-mail account) <ambv@fb.com> [ full ] (3) [jpeg image of size 24479] Really sign all user IDs? (y/N) y "[jpeg image of size 24479]" was already signed by key 4E7314AC219D7FE4 Nothing to sign with key 4E7314AC219D7FE4 Key not changed so no update needed. |
最后,就可以下载代码以及
.asc 后缀的签名文件了。|
1 2 3 4 5 6 7 8 |
➜ curl -sSLO https://www.python.org/ftp/python/3.9.5/Python-3.9.5.tar.xz.asc ➜ gpg --verify Python-3.9.5.tar.xz.asc gpg: assuming signed data in 'Python-3.9.5.tar.xz' gpg: Signature made Tue May 4 00:09:56 2021 +08 gpg: using RSA key E3FF2839C048B25C084DEBE9B26995E310250568 gpg: aka "[jpeg image of size 24479]" [full] |
阅读文档!
源码文件在解压之后,一般在最上层的目录下会有 README 或者 INSTALL 类似的文件,这是安装的文档说明。解压之后需要做的第一件事就是阅读这些文件。
文档中会有两个地方比较重要:
- 编译和安装这个软件需要的依赖,如果没有依赖就安装这个软件,要么编译有问题,要么会运行有问题;
- 软件编译的时候接收的一些参数;
Patching
某些软件可能在一些环境下无法正常工作,如果软件流行的话,在网上搜一下解决办法,一般可以找到一些人发布的解决办法。通过修改一些参数或者代码就可以了。叫做 Patch。
Patch 有两种:
- 修改脚本:比如 sed/awk 脚本,运行这些脚本可以修改源代码。例子
- Patch 文件:diff 的形式,人类可读。需要使用
Patch程序去“应用”这个 diff,即“让这个 diff 生效” 例子
常见的编译系统
简单点说,编译就是将下载回来的代码变成可以在操作系统执行的 binary 文件。所以分成两步:
- 编译(make)
- 将编译好的文件放到系统的
$PATH下面,这样可以在任意路径执行软件 (make install)
作者会将编译所用到的一些文件都放在 tarball 里面。同时,作者会希望有更多的人使用他的软件(谁不想呢?),所以会尽量让编译过程变简单一些。大部分的软件会使用 make 软件作为编译的工具。
这里不展开讲 make 了,简单点说,你提供给 make 一个 makefile,里面按照 make 的格式告诉 make:“如果目标文件不是基于最新的源码,就执行这个动作”,其中,目标文件可以是最终的软件,也可以是中间的产物。make 会自动帮你解决好先后顺序问题。
然而,make 的描述能力有限。但是想要处理起来所有的配置项,也捉襟见肘。所以这里又出现了另外一个工具:configure. 通常,软件包不会直接包含一个 makefile,而是会包含一个 configure 脚本以及一个 makefile.in 模板文件。执行 ./configure 就可以生成一个 makefile 文件,然后再执行 make.
所以,一般的编译流程如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# unpack and read documentation tar xf filename cd {directory created by above step} less README less INSTALL # generate customised makefile ./configure {some options ...} # compile everything in the local directory make # update global directories sudo make install |
另外,configure 也不是手写的,是由另一叫做 autotools 的 GNU 软件生成的。但是这个不需要用户使用,而是由软件作者来生成好。
最后一步 make install 的作用是将编译好的 binary 复制到系统的 $PATH 下。除了这一步以外,其他的步骤最好都使用普通用户来执行。
总体的流程如下:
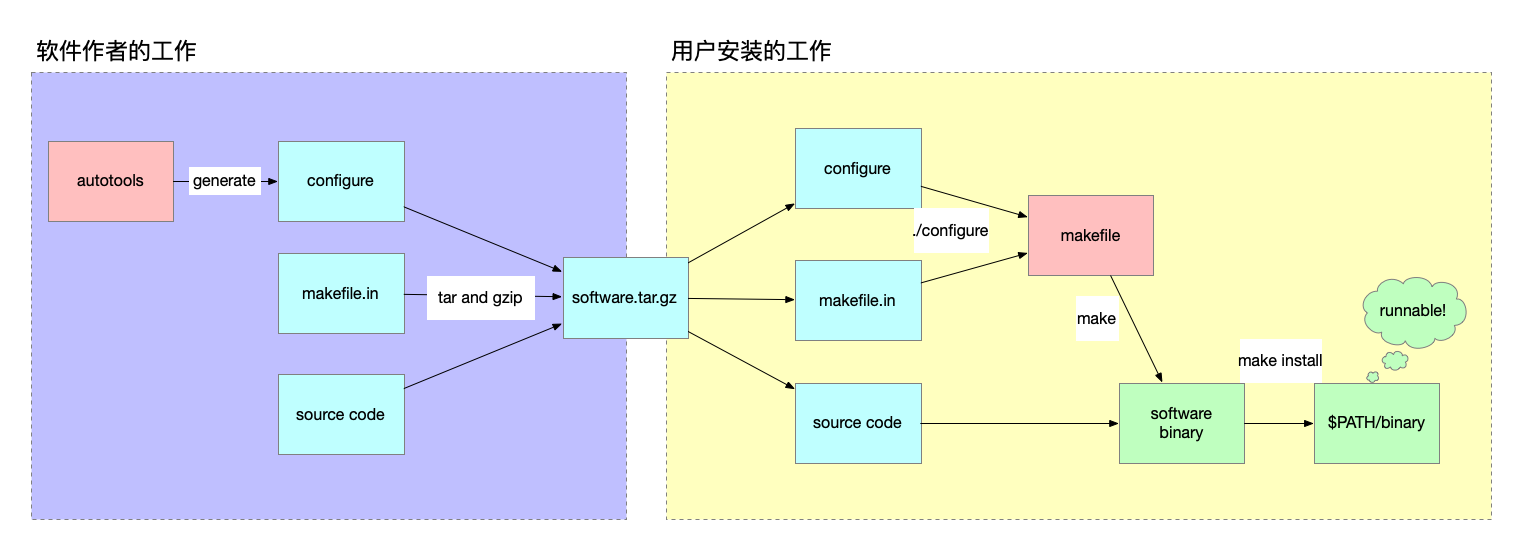
有些软件没有使用 configure 脚本。因为它们足够简单,将 configure 的逻辑直接写到 makefile 里面了。比如 Redis,就没有。安装的时候只要 make 就可以了。
|
1 2 3 4 |
$ wget https://download.redis.io/releases/redis-6.2.4.tar.gz $ tar xzf redis-6.2.4.tar.gz $ cd redis-6.2.4 $ make |
configure 和 make 生成的产物可能会和源代码文件混合在一起,弄得比较混乱,可以使用 make clean 清理编译产物。
但是对于每次编译,都在一个临时文件夹里面进行,或许是一个更好的办法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# unpack into a directory {packagename} tar xf filename # create separate build directory mkdir {packagename}-build # compile everything in the separate build directory cd {packagename}-build ../{packagename}/configure {some options} make # update global directories sudo make install |
其他的一些编译方式
cmake 现在也比较流行了,cmake 和 configure 类似,会基于传入的参数生成一个 makefile。除了使用下面这个命令替换 ./configure 之外,其他的步骤基本一样。
|
1 |
cmake . -DCMAKE_BUILD_TYPE=Release {some options ...} |
再次提醒一下,编译软件之前先看文档是一个好习惯。
有一些软件使用基于 Python/Perl 的编译工具,这些具体就参考文档好了。
还有一些工具直接是脚本语言编写的,这样的软件不需要编译,只要将软件拷贝到解释器读取的目录即可。不过一般这些语言都会自带一些包管理工具。
环境变量
configure 接受的配置项可以通过两种方式指定。
一种是环境变量。
|
1 |
NAME=tom ENABLE_FOO=no ./configure |
或者直接 export 到当前的 shell 中然后执行。
|
1 2 3 |
export NAME=tom export ENABLE_FOO=no ./configure |
另一种是通过执行 configure 时候的命令行参数。具体支持的参数,可以通过 ./configure --help 来查看。
编译安装文档
软件附带的文档没有统一的形式,常见的一些有:
- 提供在线的 HTML 形式的文档;
- 提供标准的 archive file, 可以直接下载;
- 单独提供文档下载,可以通过
man/info等查看; make installdoc安装- ……
总之还是参考文档来安装文档吧!
错误排查
编译是会很容易出错的一个过程。发生错误的时候一般根据编译错误一步一步排查就好了。要点是不要乱猜,要根据事实去推测。
举个最近遇到的问题。在一台机器上编译 Python3 失败了。./configure 的错误提示如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
./configure checking build system type... x86_64-pc-linux-gnu checking host system type... x86_64-pc-linux-gnu checking for python3.7... no checking for python3... python3 checking for --enable-universalsdk... no checking for --with-universal-archs... no checking MACHDEP... checking for --without-gcc... no checking for --with-icc... no checking for gcc... gcc checking whether the C compiler works... no configure: error: in `/opt/python37/Python-3.7.9': configure: error: C compiler cannot create executables See `config.log' for more details |
根据提示去查看 config.log 日志文件,在文件中发现这么一段:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
configure:3896: $? = 1 configure:3916: checking whether the C compiler works configure:3938: gcc conftest.c >&5 /usr/local/bin/ld: invalid option -- 'p' Try `ld --help' or `ld --usage' for more information. collect2: error: ld returned 64 exit status configure:3942: $? = 1 configure:3980: result: no configure: failed program was: | /* confdefs.h */ | #define _GNU_SOURCE 1 | #define _NETBSD_SOURCE 1 | #define __BSD_VISIBLE 1 | #define _DARWIN_C_SOURCE 1 | #define _PYTHONFRAMEWORK "" | #define _XOPEN_SOURCE 700 | #define _XOPEN_SOURCE_EXTENDED 1 | #define _POSIX_C_SOURCE 200809L | /* end confdefs.h. */ | | int | main () | { | | ; | return 0; | } configure:3985: error: in `/opt/python37/Python-3.7.9': configure:3987: error: C compiler cannot create executables See `config.log' for more details |
可以知道是 gcc 尝试测试编译一段简单的程序失败了。失败原因是 ld 不支持 -p 参数。
然后查看机器上的 ld 为什么不支持。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
$ ld --version ld (elfutils) 0.165 Copyright (C) 2012 Red Hat, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. Written by Ulrich Drepper. $ whereis ld ld: /usr/bin/ld /usr/bin/ld.gold /usr/bin/ld.bfd /usr/local/bin/ld /usr/share/man/man1/ld.1.gz $ which ld /usr/local/bin/ld $ /usr/bin/ld --version GNU ld (GNU Binutils for Ubuntu) 2.26.1 Copyright (C) 2015 Free Software Foundation, Inc. This program is free software; you may redistribute it under the terms of the GNU General Public License version 3 or (at your option) a later version. This program has absolutely no warranty. |
通过这几个命令可以看到这个机器上有很多个 ld ,而使用的 ld 是 elfutils 里面的 ld,并不是 GNU 的 ld。编译的时候将 /usr/bin 这个路径提前就好了。
大部分错误的情况是缺失了一些依赖,喜欢走弯路的话可以去网上搜索缺失的文件的名字,运气好找到缺失的依赖安装了就好了,不喜欢走弯路的话可以参考安装文档。也有时候缺失的依赖是可选的,可以通过 ./configure 的参数忽略掉。
编译器一般有一些高级的参数可以优化性能,但是如果不是很了解自己在做啥的话,最好还是不要碰。(既然你还在读这篇文章,还是不要碰了吧。)
编译出来的文件一般会带有一些 debug 参考的信息,一般用户用不着,可以通过 strip 命令来剪掉。
这是在 Mac 系统上编译出来的 Python3.9,strip 之后少了0.8M.
|
1 2 3 4 5 |
➜ ll -h python.exe -rwxr-xr-x 1 xintao.lai SGP\Domain Users 3.7M Jul 3 00:38 python.exe* ➜ strip python.exe ➜ ll -h python.exe -rwxr-xr-x 1 xintao.lai SGP\Domain Users 2.9M Jul 3 00:40 python.exe* |
不过今天的硬盘已经这么不值钱了,也没什么必要其实。
最后有些软件可能在安装之后需要一些特定的配置才能运行。还是那句话,读文档。
练习
看到这里,编译下来 LFS 基本就没什么问题了,可以按照 LFS 从头开始编译一些 Linux 的工具试试,这里列出了一个能工作的 Linux 需要的基本软件。
搞一个这样的dockerfile,就能很直观了吧~构建docker的每层就是每一个步骤
啊,发错位置了,补充,是针对那篇LFS说的
嗯,应该是可以。但其实 LFS 是本书,意义就是体验手动编译的过程,学习 Linux. 要是自动化编译的话就没有什么意义了……可以直接选择其他的发行版。如果 Dockerfile 只是为了一次性的编译,那成本有些大……
其实可以考虑gentoo
Gentoo也是和lfs一样可以tweak flags和features,但是它的portage帮你standardlize了这些,装软件就和正常apt一样简单
我现在就天天用gentoo
同意。LFS 主要的意义是完全从头开始编译一个 Linux,包括编译的工具链也是需要从新编译来自举的。所以学习的功能更多一些。要是自己使用的话,我不会选择 LFS 的。