平常使用计算机,我们的直觉是计算机里面分成了文件夹和文件两种东西。但是实际上在操作系统的文件系统中,文件夹也可以被认为是存储了特殊内容的文件,“所有的东西都是文件”。而且文件系统并不用文件名来区分文件,而是使用一串不重复的数字。本文就来介绍一些文件系统的一些概念和原理。
Linux 的文件系统将磁盘分成了两部分。一部分存储的是 inode,一部分存储的是 block。文件的内容存储在 block 中。文件的元信息,比如 owner,group,atime 等,都存储在 inode 中,包括 block 的位置。如下图:
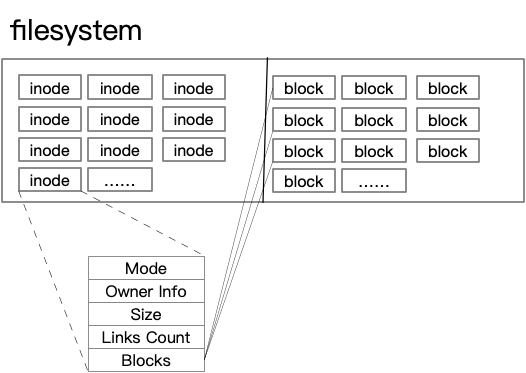
从图中我们可以看到,这里面没有文件名字的信息。而我们日常对文件的操作都是通过文件名来的。那文件名字在哪里呢?上面说过,文件夹也是文件,其实文件的名字,就在文件夹的内容里面(即 blcok)。文件夹也是上面的形式,由 inode 记录了它的元信息,然后 inode 指向了 block,block 里面存储了文件夹的内容,即文件名字到 inode 的映射。
虽然文件夹也是文件,但是操作系统并不提供 syscall 对文件夹的内容进行直接操作。比如,你不能 cp /dev/null directory 来覆盖文件夹的内容,也不能查看 block 存储的真正内容。而只能通过系统提供的 syscall 对文件夹进行有限的操作。这么做第一是因为对文件夹的操作就这么多,通过 syscall 就够了;第二是因为文件夹存储的映射如果被搞乱了,不光这个文件夹不可用了,相关的 inode 都拿不到了(因为我们针对文件的操作都是通过文件名,inode 被文件系统屏蔽掉了)。
所以,当文件系统拿到一个路径,是怎么找到对应的内容的呢?比如 /home/root/a.txt 。
首先文件系统会从 #2 inode 开始(注意这里说的经典的文件系统,不同的文件系统开始的 inode 可能不同,但为啥是2呢?),也就是 / ,找到 #2 inode 指向的 block 读到 / 下面的文件列表。然后找到 home 对应的 inode。然后通过 inode 指向的 block,打开 /home 下的文件列表,找到 root 对应的 inode,找到 inode 指向的 block,读到 a.txt 对应的 block,最后读到 block 存储的内容,就是 a.txt 的内容啦。
我们可以通过 ls 的 -i 参数查看一个文件夹下的名字对应的 inode(跟上面说的从 #2 开始不一样,因为我这个环境是 xfs):
[vagrant@trial /]$ ls -i
66973 bin 8388737 etc 163 lib64 25274562 opt 12408 run 1 sys 25165953 var
2 boot 161 home 8496943 media 1 proc 164 sbin 18789 tmp
1025 dev 66978 lib 16854324 mnt 16797825 root 162 srv 8388747 usr
文件系统一旦创建,inode 的数量或 block 的数量就确定了,不能修改。如果 inode 用完了,文件系统就再也不能创建新的文件了(不太可能发生,除非创建的小文件非常多)。df -i 可以查看系统的 inode 使用情况。
[vagrant@trial ~]$ df -i Filesystem Inodes IUsed IFree IUse% Mounted on devtmpfs 251872 402 251470 1% /dev tmpfs 254824 1 254823 1% /dev/shm tmpfs 254824 462 254362 1% /run tmpfs 254824 17 254807 1% /sys/fs/cgroup /dev/sda3 7864320 74351 7789969 1% / tmpfs 254824 11 254813 1% /tmp /dev/sda1 65536 308 65228 1% /boot tmpfs 254824 5 254819 1% /run/user/1000
inode 到 block 的寻址
你用过U盘吗?可否遇到过U盘不能存储超过4G的文件的问题(FAT32文件系统)?即使U盘是32G的。这其实是文件系统寻址的限制。接下来我们以 EXT4 文件系统为例,看下有了 inode,文件系统具体是怎么找到 block 的,顺便计算一下 EXT4 单文件最大可能是多少。
在前面的那种图中,可以看到 inode 包含了文件拥有者,访问时间修改时间等信息。最重要的,是 block 的位置,毕竟这是真正存储了文件内容的地方。
如果给你一个 inode,你怎么把 block 的位置存到 inode 里面呢?文件的大小是未知的,可大可小。基于这个特点,首先想到的可能是用一个 LinkedList 来存储 block 的位置,block 留出一个位置存储下一个 block。但是要知道,机械硬盘顺序读很快,随机读的话磁头移动是非常慢的。所以 block 肯定是尽最大的可能连续使用,用 LinkedList 来做寻址就太慢了,比较合适的是 Array 这种相邻的形式。
那么在 inode 中我们应该为 block 的地址留出多少位置呢?太少的话,单文件的上限就太小了。太大的话,如果系统中都是一些小文件,就太浪费空间了。
Ext2/3 文件系统是这么做的(也是大多数文件系统的一个做法):留出15个位置来负责存储 block 的地址。一个文件只能有 15 个block 吗?当然不是。这15个地址里面分成了直接指向(Direct Block Pointers),间接指向(Indirect Block Pointers),双重间接指向(Double indirect Block Pointers),三重间接指向(Triple Indirect Block Pointers)。
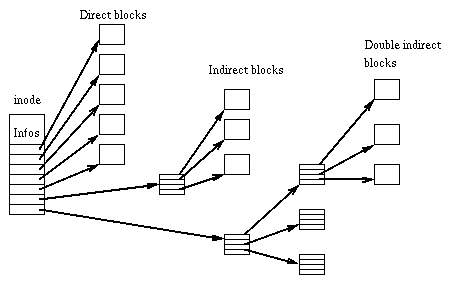
其中表示直接指向 block 的地址占了12个,这里我们假设一个 block 的大小是 4K,那么如果文件如果小于 4*12=48K 的话,直接使用 inode 中的直接 block 指针就可以存的下。综上,Direct Block Pointers 一共有12个,每一个表示一个 4K 的block。一共可以存储 48K。
第13个指针表示的是 Indirect Block Pointers。这个指针指向的地址也是一个 block,但是这个 block 里面存储的并不是文件的内容,而是一些指向 block 的指针——整整一个 block,存储的都是像 Direct Block Pointers 那样的指针哦!满满 4K 的指针。Block 指针是 32bit 的,一个 block 可以存储 4K/32bit = 1024个 Block 指针。综上,Indirect Block Pointers 就一个,里面使用一个 block 存储了 1024 个 block pointers,可以存储 1024 * 4K = 4M 数据。
第14个指针是 Double indirect Block Pointers,比较好理解了,这个位置存储的地址依然指向了一个 block,但是这个 block 里存储的还是 block 指针,这些 block 指针指向的 block 里面存储的还是指针!这些指针再指向的block存储的才是文件的内容。见上图的最后那一个位置。我们知道 Indirect Block Pointers 可以存储 4M 的数据,那么这里的双重 Block 指针其实就是存储了 4M 的指针,4M 可以存储多少个 Block Pointers 呢?4M /32bit = 1048576个,每个block 4K,那就可以存储 4G 数据。
第15个指针,很好理解了吧,让我绕个圈子,这里存储的是指向 Block 的指针,指针指向的 Block 存储的还是 Block 指针,指针指向的 Block 存储的还是Block指针,这里存储的 Block 指针指向的还是 Block 指针(数数这里面有几次 Indirect吧)。这些指针指向的Block存储的是文件内容啦。这里最多可以有多少个 Block 呢?Double indirect Block Pointers 可以有 4G,那么这 4G 数据都是指针的话就是 4G / 32bit * 4K = 4G * 1024 = 4T.
综上,文件最大是 48K + 4M + 4G + 4T。是不是很巧妙的设计?
因为这种方式指向无法动态给二重或者三重指针分配大小,未免有些浪费。在 Ext4 中,ext4_extent_header 的多重指针是动态分配的,简单来说,eh_depth 字段标识了目前的 block 是第几重指针,如果是0,说明指向的 block 直接存储的是文件内容,如果不是0,那么 block 存储的就是 Indirect Block Pointers, 并且 eh_depth 标识了会有几重指针。在 Ext4 中,但文件最大大小不再受层级限制,而受 logical block number 的限制,即 block number 最大是 2^32,在 4K block 下,就是 16T。eh_depth 最大是 5,仅仅是因为 5 就可以存储下 2^32 个 block number 了,再大也没有意义。(ext4_extent_header 长度是 12bytes,4*(((blocksize - 12)/12)^n) >= 2^32 中 n 最小是5)
最后需要强调一点是,不同的文件系统 inode 数据结构有所不同,比如 ext4 文件系统就支持将很小的文件直接存储在 inode 中,不使用 block。
Hard Link 和 Symbolic Link
上面我们说过,文件夹的内容其实是文件名字到 inode 的映射。
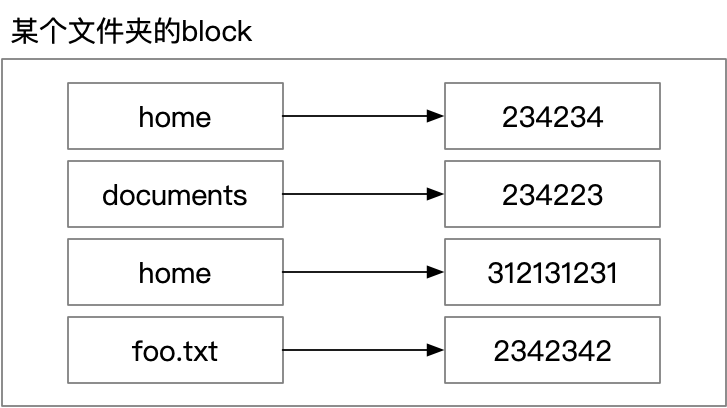
那么是否可以有两个 name 映射到同一个 inode 呢?
答案是可以的,这就是所谓的 Hark Link.
通过 ln source-filename target-filename 可以创建一个 Hard Link,即创建一个 target-filename 映射到和 source-filename 一样的 inode number。
举个例子,我们现在有 hello 这个文件:
➜ foo ls -il total 0 12945694378 -rw-r--r-- 1 laixintao wheel 0 Jun 25 20:46 hello
可以看到它的 inode number 是 12945694378, 然后我们再创建一个 Hark Link:
➜ foo ln hello world ➜ foo ls -il total 0 12945694378 -rw-r--r-- 2 laixintao wheel 0 Jun 25 20:46 hello 12945694378 -rw-r--r-- 2 laixintao wheel 0 Jun 25 20:46 world
我们可以观察到两个有趣的现象:
1)hello 和 world 有相同的 inode number,这意味着这两个文件名字对应的 inode 是一样的,即它们的 owner、atime,以及指向的 block 一模一样,文件内容也当然一模一样。如果我们改变了一个文件的权限,那么去看另一个文件名字,也会跟着改变。
➜ foo chmod 777 world ➜ foo ll -il total 0 12945694378 -rwxrwxrwx 2 laixintao wheel 0 Jun 25 20:46 hello* 12945694378 -rwxrwxrwx 2 laixintao wheel 0 Jun 25 20:46 world*
2)有一个数字从 1 变成 2 了。这数字叫做 Link Counts,就是在 inode 中有一个字段记录的是有多少 filename -> inode number 的 mapping,当没有 filename 指向这个 inode 的时候,说明这个 inode 可以被回收了。
从上面我们可以看到,创建一个 Hard Link 之后,实际上就有两个 filename 指向了同一个 inode。即新创建的 Hard Link 和原来的在本质上没有什么区别,也分不出来谁是 Hard Link 谁是原来的文件。删除文件这个操作其实是 unlink,就是删除了一个 filename -> inode 的 mapping 而已,当一个 inode 的 Link Counts 为0,inode 才会被删除。
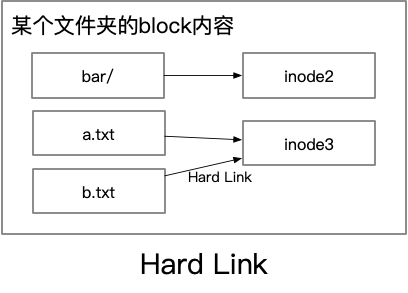
有没有感觉像 GC 中的引用计数?那么新的问题就来了:怎么解决循环引用的问题呢?比如像下面这个情况,子文件夹里面建立了一个指向父文件夹的 Hard Link.
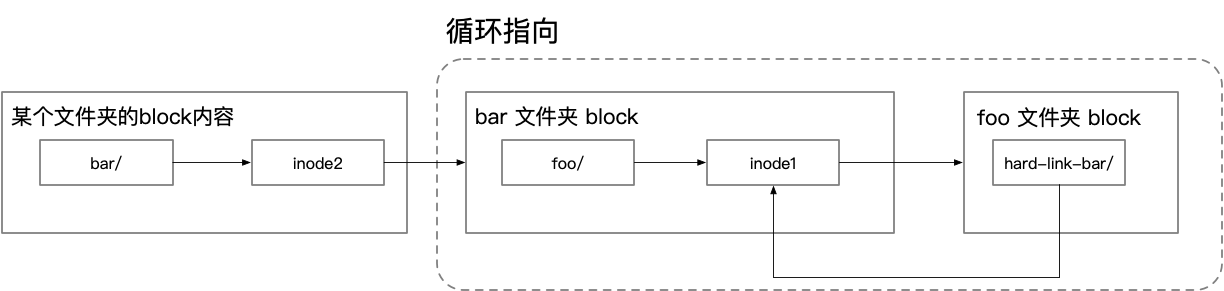
这样在整个父文件夹删除的时候,这些 Hard Link 指向的 inode 的 Link Counts 依然不会下降,导致释放就有问题。文件系统是怎么解决的呢?禁止对文件夹建立 Hard Link,只允许对文件建立 Hard Link.
另外,你有没有想过为什么我们可以使用 cd .. 跳转到父文件夹呢?其实就是在文件夹创建的时候,会自动创建一个叫做 .. 的 mapping,指向父文件夹的 inode。即一个新文件夹创建之后,它的 Link Count 就是2了,一个是 .,一个是 .. 。
相对而言,Symbolic Link 更常用一些,因为 Hard Link 的管理成本太高了。你删文件的时候,得把所有的 Hard Link 都删掉才行。
Symbolic Link 可以理解成一个特殊的文件,文件的内容指向的是真正的文件。这样一来,如果删除了源文件,Symblic Link 还是存在的(用过 Windows 的朋友可以理解成 Windows 的快捷方式)。
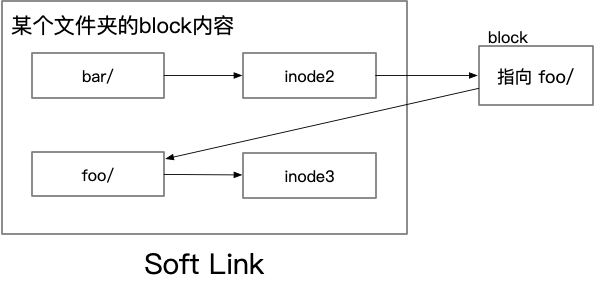
早期符号链接的实现,采用直接分配磁盘空间来存储符号链接的信息,这种机制与普通文件一致。这种符号链接文件里包含有一个指向目标文件的文本形式的引用,以及一个指示自己为符号链接的标志。
这样的存储方式被证明有些缓慢,并且早一些小型系统上会浪费磁盘空间。一种名为快速符号链接的新型存储方式能够将文本形式的链接存储在用于存放文件信息的磁盘上的标准数据结构之中(inode)。为了表示区别,原先的符号链接存储方式也被称作慢速符号链接。
Fun with inodes
- 移动文件、重新名等操作,实际上只是修改了 parent directory 的 block 中存储的 filename -> inode 映射,所以跟文件多大是没有关系的,都是 O(1) 复杂度;而且这也不影响 inode 的号码。
- 理论上,当文件创建,inode 分配,就不会再变了。移动、重命名、写入文件、截断文件都只是修改 inode 的元信息或者修改 parent directory 的内容,inode 总是不变。所以像日志收集程序,使用 inode 来区分日志文件,是非常可靠的。日志被 rotate 了也可以做到不重不漏。
- 如果你知道一个 inode ,怎么找出这个文件呢?
$ find . -inum 23423 -print - 但是直接操作 inode 是不允许的,Kernel 提供的 syscall 只能通过 filename 来操作文件。理由同上,文件系统 corrupt 了是很危险的。
- 文件系统里面有一个文件带着古怪的名字,怎么删除?可以通过 inode 删啊。
$ find . -inum 234234 -delete.
最后再强调一下,本文介绍的是大多数 filesystem 的表现,具体到一个特定的 filesystem 可能会有所不同。如果本文有疏漏,欢迎指出。
参考资料(以下列举了一些参考资料,和文件系统的实现):
- How To Manipulate the Inode Structure?
- Lecture 10: Disks & File Systems
- Operating Systems
- UFS 是一个比较简单的文件系统:UFS 的 dinode.h
- Ext4 Disk Layout
- tldp Linux Data Structures
- Symbolic link
- Hard link
2024年9月12日更新:原文介绍的 inode layout 其实是 Ext2/3 文件系统,不是 Ext4 文件系统,进行了纠正以及补充 Ext4. Debian 中文群 dududu 和 Yancey Chiew 指出。
写一篇这样的文章好辛苦吧?
嗯,是写了挺久的。现在看感觉不是很满意,但是懒的再读几遍做优化了…
Pingback: 博客迁移到 Cloudflare | 卡瓦邦噶!
Pingback: 开源软件源码编译指南 | 卡瓦邦噶!
> 如果你知道一个 inode ,怎么找出这个文件呢?$ find . -inum 23423 -print
在 ext4 文件系统上,debugfs 命令似乎会比 find 快一些。 https://unix.stackexchange.com/a/35310
Cool,谢谢
Pingback: 硬盘分区介绍 | 卡瓦邦噶!