在关于软件的复杂度上, David J. Wheeler 说:
“We can solve any problem by introducing an extra level of indirection.”
在使用了一段时间的 React Hook 之后,对于分层有一些感触。可能在维护和管理规模较大的软件上,添加更多的抽象和分层是必不可少的。但是分层不一定会带来更多的复杂度,巧妙的设计可以让软件依然容易维护。
我发现设计好、接受度高的软件,代码倾向于让用户按照业务逻辑来组织,而不是按照框架的实现来组织。
比如 React Hooks,在没有它之前,在一个组件中,你要将所有的所有组件的 ComponentDidMount 放在一起,将 ComponentDidUpdate 放在一起。如果一个页面有 5 个组件构成,那么每一个组件都要分别写到两组里面去,如果涉及更多的状态管理,涉及同一个组件的状态管理将分散在更多的地方。
但是 Hooks,让你可以把通一个组件的状态、控制逻辑、渲染逻辑都放在通一个地方。
import React, { useState, useEffect } from 'react';
function Example() {
const [count, setCount] = useState(0);
// Similar to componentDidMount and componentDidUpdate:
useEffect(() => {
// Update the document title using the browser API
document.title = `You clicked ${count} times`;
});
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}
这就使得代码的阅读性和可维护性变得很好。
另外一个例子是 Django 框架组织代码的形式。Django 使用 app 来组织用户的代码,在每一个 app 里面都有 view model 等,控制这个 app 的内容。这样的好处有:这个 app 只管理这一部分的逻辑,与其他 app 的耦合性很低,“高内聚,低耦合”。
user ├── __init__.py ├── admin.py ├── apps.py ├── authentication.py ├── middlewares.py ├── migrations │ ├── 0001_initial.py │ ├── 0002_auto_20210311_1035.py ├── models.py ├── serializers.py ├── tests.py └── views.py
一开始接触这样的框架的时候比较不适应, 比如怎么划分 app,是一个经验问题。新手很容易将所有的内容都写到同一个 app 中,或者直接按照团队的分工来划分 app。但如果正确掌握了这种组织代码的形式的话,代码就的可维护性就会提高很多。
一个反例是蚂蚁的 SOFA 框架。以前的同事跟我说,“来蚂蚁就要学习 SOFA 的分层,学会了这个就掌握了精华了。” 使用这个框架写了一年多的代码,我还是无法理解其中的智慧。撇开启动速度长达三分钟、配置混乱并且难以理解这些问题不说。就说你要把代码写在哪一层这个问题,就会难倒很多新手。下面是一个新项目默认的分层结构,实际上随着项目的开发,层数会增加很多:
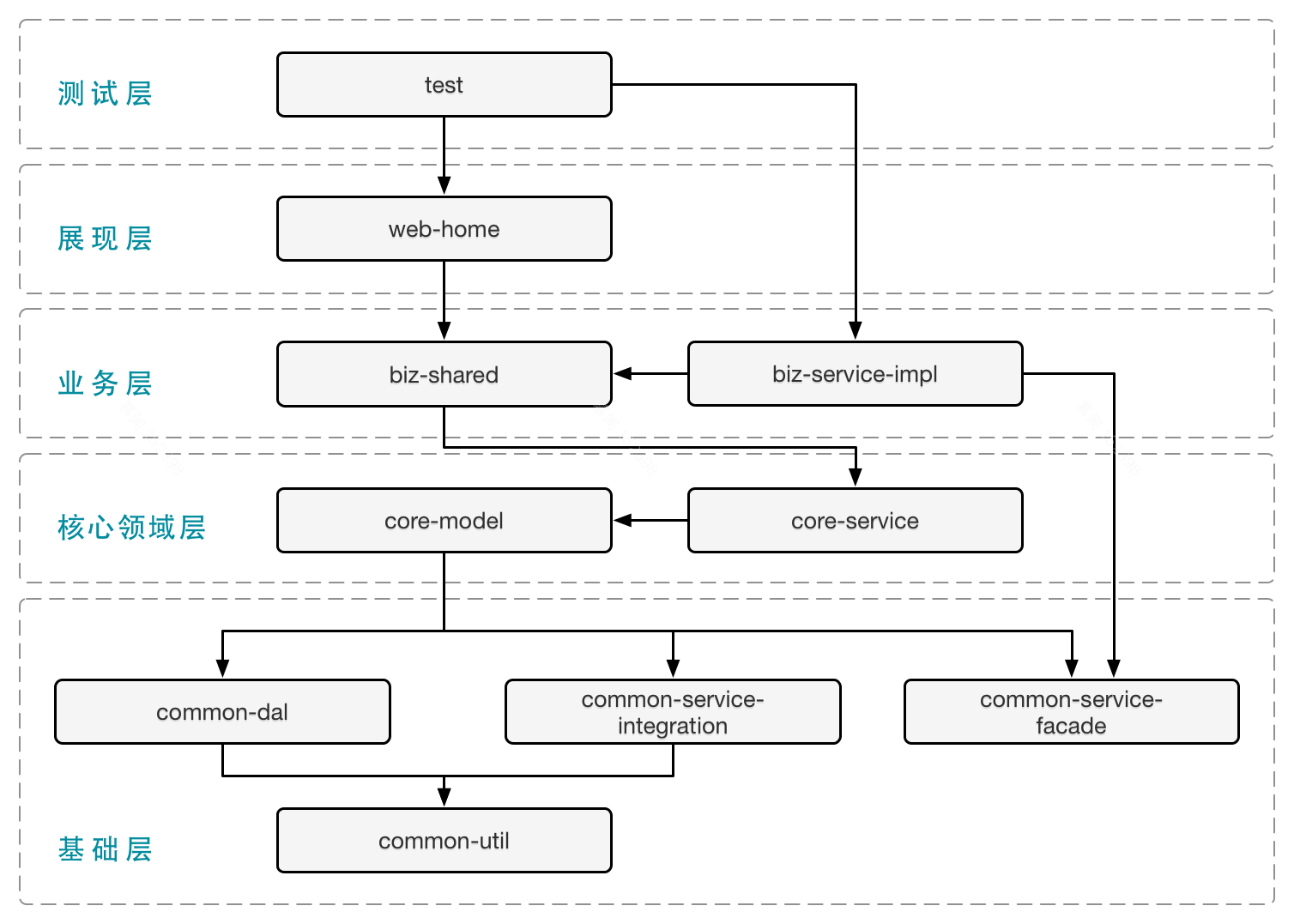
这样的设计默认了用户必须理解框架对每一层的设定。将项目变得难以管理,并且增加了很多工作量。比如对某一个 model 添加一个评论功能, 在 Django 中几乎是一小时就可以完成并上线的工作量, 在 SOFA 中可能需要几天的时间,在不同的层上添加逻辑。实际上大多数时候这些“层”什么都没有干,只不过是直接去调用下一层。
好的设计应该是 “make the easy things easy, and the hard things possible.” 显然,这种设计是让所有的事情都变得一样复杂。即使写一个 Hello World 出来,你用这个框架也需要创建出来一个庞然大物。

实话说,我在蚂蚁的这段工作经历,从开发体验上说,是非常痛苦的。包括框架启动慢、复杂并且混乱的配置,对 Java 语言的强绑定,缺少文档,代码难以测试(因为即使是本地开发也连接了很多其他服务)等等。
那么为什么会造成这种情况呢?我认为和组织形式有关。康威定律说“设计系统的架构受制于产生这些设计的组织的沟通结构。” 我认为可以再扩展一下,不光受制于沟通结构,和整个组织的政策都有很大关系。做一个事情的方案有很多种,可以使用一层抽象,也可以使用三层抽象,甚至可能有某种优雅的方法不添加额外的实体概念去实现。这不是一件简单地事情,需要极具经验的工程师才能做得很完美。然而假如 KPI 的压力太大,以及 KPI 只看结果贯彻地太好,那么怎么做就不会变的不重要,毕竟都可以达到一样的效果(但从某一个量化指标上来说),虽然可能会带来更大的理解成本,以及潜在的维护成本、沟通成本,甚至带来的稳定性隐患等。但是这不重要,KPI 怎么完成无所谓,只要完成了都一样。
另一个表现是晋升,一些公司像是封建社会一样有着森严的等级,某一等级的工程师只能做那一等级的事情,大家都想着向上晋升。但是很多晋升过去的人已经不写代码了,很多高等级的 SRE 工程师甚至都已经很久不使用终端了。这就导致在晋升的时候,这些高等级的工程师组成的评委团不会太过于注重技术方案。本来评审一个候选人的时候应该问 “为什么选择使用 A 而不使用方案 B?” “你这样做会有某某问题是如何解决的” “XX是怎么处理的”,由于无法理解技术所以只能问出这种问题:
你发这个的底层逻辑是什么?顶层设计在哪里?最终交付价值是什么?过程的抓手在哪里?如何保证结果的闭环?能否赋能产品生态?你比别人发的亮点在哪?优势在哪?我没有看到你的沉淀和思考,你有形成自己的方法论吗?你得让别人清楚,凭什么发这个的人是你,换别人来发不一样吗?
或许觉得这是网友的调侃,但是在当你确确实实要在晋升的时候去想破头思考这些问题该怎么回答的时候,就不那么好笑了。
在这种环境下,像是压测、限流、熔断、容灾等等方案,只要去做肯定是可以完成的,但是你可以因为这件事带来非常大的改造成本,造成严重的开发效率问题,搞出来很多让开发人员难以理解的概念,和蹩脚的设计,也可以做的很漂亮。虽然对于将来评价你的评委来说,这并没有很大的不同。甚至你因为设计的拙劣带来了很大的改造成本,却又给你带来了更多的工作量,加班卖力的完成,于是又成了一个可以被人称道的点,可以凸显你的推动能力、领导能力,这是评委们非常喜欢的能力。虽然本质上只是给大家带来了一堆麻烦而已。
另外,这种晋升机制又会让大家去强行给自己加活。通常的套路表现为:找出开源软件中的一两个毛病,然后以此为借口声称这无法满足我们公司的需要,所以需要“自研”一套,然后“自研”的软件解决了自己当初找到的那几个毛病,成功获得晋升。而实际上,自研的东西可能又带来了成百个其他的问题,但除了给使用者造成了痛苦之外,倒没有什么问题,因为还有其他人虎视眈眈地想再重新研发一次,替换掉你这个项目呢。
如此对技术的不够重视,加上繁杂的会议积压开发时间,工期紧,导致大部分的工程师不会有时间去思考设计、分层的问题了。虽然有时候停下来思考可能带来更多的收益,但是弥漫在焦虑中很难停得下来。我在这种环境中也写出了不少垃圾。在这种情况下,人们就越倾向于使用自己非常熟悉的技术,不愿意学习新的东西,因为这会减少自己工作中的麻烦。懒惰地使用分层和抽象解决问题,导致软件越来越复杂。声称 Java 才是适合“企业级”应用的最佳解决方案,实际上只是懒得思考和设计。毕竟,现在的事情已经够多了,我们应该把更多的时间放在“顶层设计”,思考“业务价值”上,技术方面,只要实现了就好,怎么实现的,没有人关心。我觉得这也就是为什么蚂蚁的很多人将很多东西做成了自己熟悉的系统的样子,比如很多中间件经过内部的修改变得只支持 Java,如果你在蚂蚁使用除了 Java 之外的语言几乎是难上加难(2020年);比如很多写过交易系统人去写一个逻辑非常简单的东西都会分成7层来写,甚至类的名字会使用交易系统的概念来明令,XXOrder,XXTransaction;比如听说 Python 实现东西很快,但是会把 Python 去写成 Java 的样子。
说了这么多,需要提醒一下读者的是,这并不能代表蚂蚁所有的技术,甚至有人会觉得 SOFA 非常成功,给无数小微企业带去了收益。总之,只是我自己的想法而已,如果我很喜欢蚂蚁的研发环境,我也不会离开蚂蚁。也可能是我天生愚钝,无法理解里面的大智慧吧。
复杂是很简单的,简单是很困难的。好的软件需要很多年的持续耕耘才行,一边做一遍思考,从自己现在做的事情开始,一点一滴,随着时间慢慢积累才行。
最后给读者推荐我比较喜欢的一个视频吧,John 讲的 A Philosophy of Software Design | John Ousterhout | Talks at Google 。以及他的书:A Philosophy of Software Design .
2021年06月15日更新:
一点想法。有关 web 框架,好的框架都是从简单的开始,随着项目的发展,逐渐变得越来越复杂,比如说 Flask,项目开始的时候可能就是一个文件,用户可以根据需要,引入依赖,拆分模块。虽然有些框架采用了不一样的哲学,比如 Django, React, 但是一开始脚手架生成的框架总是简单的。不好的框架,一开始就会给你生成大量的代码,即使你要完成一个很简单的功能,也要给你分个七八层,引入几十个依赖。记得以前有一次公司让领导亲手用我们自己的框架写一个 Hello World 类似的东西,领导们写了一整天,搞的满头大汗。