第一次接触 docker 的人可能都会对它感到神奇,一行 docker run,就能创建出来一个类似虚拟机的隔离环境,里面的依赖都是 reproduceable 的!然而这里面并没有什么魔法,有人说 Docker 并没有发明什么新的技术。确实是,它只不过是将一些 Linux 已经有的功能集合在一起,提供了一个简单的 UI 来创建“容器”。
这篇文章用来介绍容器的原理。
什么是一个容器?我们从容器的标准开始说起。
一、OCI Specification
OCI 现在是容器的事实标准,它规定了两部分的标准:
- Image spec:容器如何打包
- Runtime spec:容器如何运行
Image Spec
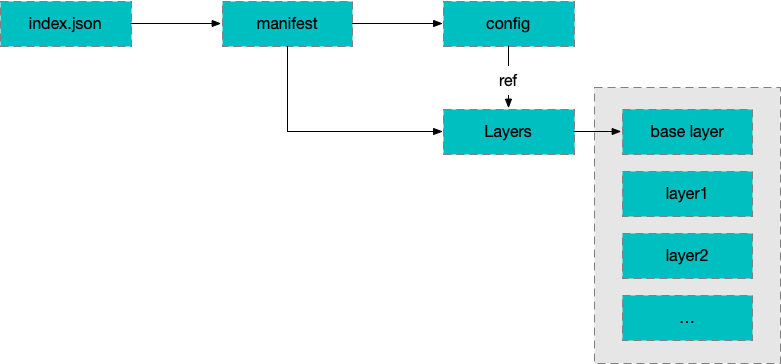
容器的运行时是通过 Image 创建的,Image Spec 规定了这个 Image 里面要放什么文件。本质上,一个 Image 就是一个 tar 包。里面一般包含这些内容:
├── blobs
│ └── sha256
│ ├── 4297f01aae8e36da1ec85e36a3cc5a4b11aa34bcaa1d88cc9ca09469826cb2bf (image.manifest)
│ └── 7ea0496f252ea46535ea6932dc460cb7d82bfc86875d9d2586b6afa1e8807ad0 (image.config)
├── index.json
└── oci-layout
manifest 里面包含 config 和 layers,其中 config 包含以下内容的配置:
- 创建运行时(container)的时候需要的配置;
- layers的配置
- image 的 metadata
layers 就是组成 rootfs 的一些文件。base 层的 layer 有所有的文件,之后的 layer 只保存基于 base 层的 changes。在创建容器的时候需要打开这个 Image,先找到 base layer,然后将之后的 layer 一个一个地 apply changes,得到最后的 rootfs。
我们可以下载一个 Nginx 的 Docker Image 来看下里面都有什么。
首先 pull 下来 docker 的 image,然后将它保存为一个 tar 文件。
$ docker pull nginx
Using default tag: latest
latest: Pulling from library/nginx
75646c2fb410: Pull complete
6128033c842f: Pull complete
71a81b5270eb: Pull complete
b5fc821c48a1: Pull complete
da3f514a6428: Pull complete
3be359fed358: Pull complete
Digest: sha256:bae781e7f518e0fb02245140c97e6ddc9f5fcf6aecc043dd9d17e33aec81c832
Status: Downloaded newer image for nginx:latest
docker.io/library/nginx:latest
# docker save nginx -o nginx_image.tar
然后再把它解压开:
$ tar xvf nginx_image.tar -C nginx
x 241e50a7915c1c9d7e9ddaa9118295fa448168f9aa9cc80b186b58f56122a072/
x 241e50a7915c1c9d7e9ddaa9118295fa448168f9aa9cc80b186b58f56122a072/VERSION
x 241e50a7915c1c9d7e9ddaa9118295fa448168f9aa9cc80b186b58f56122a072/json
x 241e50a7915c1c9d7e9ddaa9118295fa448168f9aa9cc80b186b58f56122a072/layer.tar
x 6c7f27111a8796008108962a65a7ab1e1490de70c34ac31fbafc74930d7d2ad2/
x 6c7f27111a8796008108962a65a7ab1e1490de70c34ac31fbafc74930d7d2ad2/VERSION
x 6c7f27111a8796008108962a65a7ab1e1490de70c34ac31fbafc74930d7d2ad2/json
x 6c7f27111a8796008108962a65a7ab1e1490de70c34ac31fbafc74930d7d2ad2/layer.tar
x 73c6c533cd7fa1fa40ee3868779f1a7cc0832f901af9d8ffd4e6215266460745/
x 73c6c533cd7fa1fa40ee3868779f1a7cc0832f901af9d8ffd4e6215266460745/VERSION
x 73c6c533cd7fa1fa40ee3868779f1a7cc0832f901af9d8ffd4e6215266460745/json
x 73c6c533cd7fa1fa40ee3868779f1a7cc0832f901af9d8ffd4e6215266460745/layer.tar
x 7ce4f91ef623b9672ec12302c4a710629cd542617c1ebc616a48d06e2a84656a.json
x 8d962a933e208a6b2a55a8b69a6335f7a9815fd3ff7478077aef0c2578bb2cbc/
x 8d962a933e208a6b2a55a8b69a6335f7a9815fd3ff7478077aef0c2578bb2cbc/VERSION
x 8d962a933e208a6b2a55a8b69a6335f7a9815fd3ff7478077aef0c2578bb2cbc/json
x 8d962a933e208a6b2a55a8b69a6335f7a9815fd3ff7478077aef0c2578bb2cbc/layer.tar
x 933cc7830332e0910e8d3db6038896713a27a5af0125b7b5aa311477e6fcd869/
x 933cc7830332e0910e8d3db6038896713a27a5af0125b7b5aa311477e6fcd869/VERSION
x 933cc7830332e0910e8d3db6038896713a27a5af0125b7b5aa311477e6fcd869/json
x 933cc7830332e0910e8d3db6038896713a27a5af0125b7b5aa311477e6fcd869/layer.tar
x fa03658ad40153748b0abbe573db2aaf943049a0749d192a4cfa56f107a80270/
x fa03658ad40153748b0abbe573db2aaf943049a0749d192a4cfa56f107a80270/VERSION
x fa03658ad40153748b0abbe573db2aaf943049a0749d192a4cfa56f107a80270/json
x fa03658ad40153748b0abbe573db2aaf943049a0749d192a4cfa56f107a80270/layer.tar
x manifest.json
x repositories
然后使用 tree 命令看下里面的结构:
$ tree
.
├── 241e50a7915c1c9d7e9ddaa9118295fa448168f9aa9cc80b186b58f56122a072
│ ├── VERSION
│ ├── json
│ └── layer.tar
├── 6c7f27111a8796008108962a65a7ab1e1490de70c34ac31fbafc74930d7d2ad2
│ ├── VERSION
│ ├── json
│ └── layer.tar
├── 73c6c533cd7fa1fa40ee3868779f1a7cc0832f901af9d8ffd4e6215266460745
│ ├── VERSION
│ ├── json
│ └── layer.tar
├── 7ce4f91ef623b9672ec12302c4a710629cd542617c1ebc616a48d06e2a84656a.json
├── 8d962a933e208a6b2a55a8b69a6335f7a9815fd3ff7478077aef0c2578bb2cbc
│ ├── VERSION
│ ├── json
│ └── layer.tar
├── 933cc7830332e0910e8d3db6038896713a27a5af0125b7b5aa311477e6fcd869
│ ├── VERSION
│ ├── json
│ └── layer.tar
├── fa03658ad40153748b0abbe573db2aaf943049a0749d192a4cfa56f107a80270
│ ├── VERSION
│ ├── json
│ └── layer.tar
├── manifest.json
└── repositories
打开 manifest.json 就会发现里面标注了 config 文件,以及 layers 的信息,config 里面有每一层 layer 的信息。
如果解压 layer.tar,就可以看到里面用于构建 rootfs 的一些文件了。
$ tar xvf 8d962a933e208a6b2a55a8b69a6335f7a9815fd3ff7478077aef0c2578bb2cbc/layer.tar
x docker-entrypoint.d/
x docker-entrypoint.d/.wh..wh..opq
x etc/
x etc/.pwd.lock
x etc/apt/
x etc/apt/sources.list.d/
x etc/apt/trusted.gpg
x etc/ca-certificates/
x etc/ca-certificates/.wh..wh..opq
x etc/ca-certificates/update.d/
x etc/ca-certificates.conf
...
容器运行的时候,就依赖这些文件,而不依赖 host 系统上的依赖。这样就做到和 host 上面的依赖隔离。
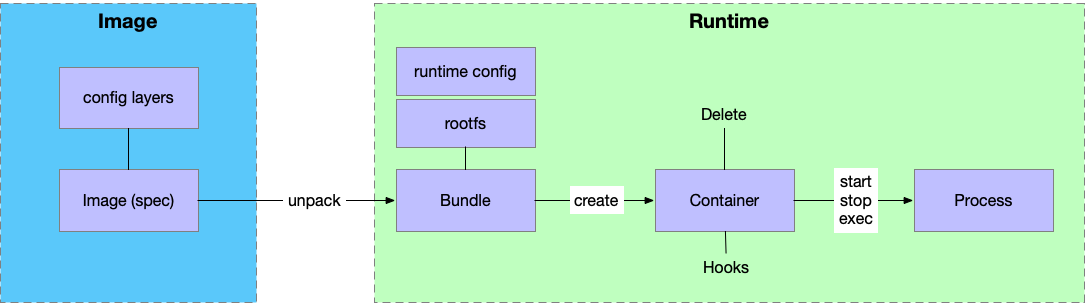
Runtime Spec
从 Image 解包之后,我们就可以创建 container 了,大体的过程就是创建一个 container 然后在 container 中运行进程。因为有了 Image 里面的依赖,容器里面就可以不依赖系统的任何依赖。
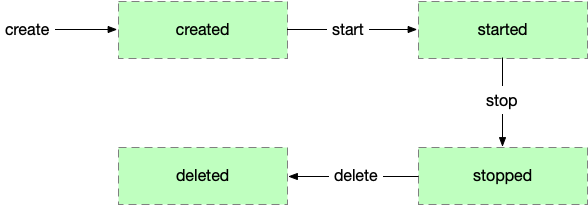
容器的生命周期如下:
Image, Container 和 Process
- Containers 从 Image 创建,一个 Image 可以创建多个 contaners
- 但是在 Container 作出修改之后,也可以直接将里面的内容保存为新的 Image
- 进程运行在 Container 里面
实现和生态
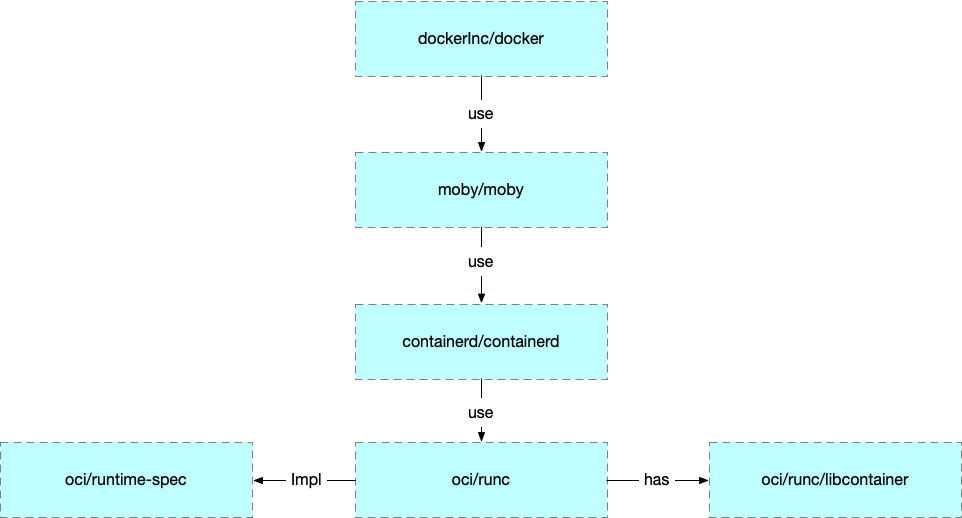
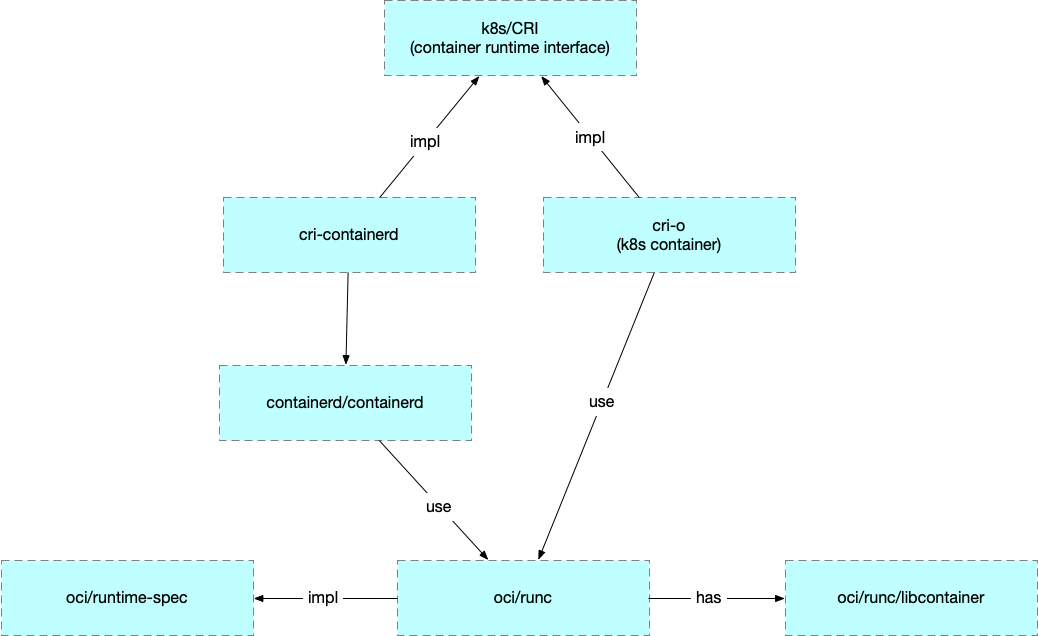
runc 是 OCI 的标准实现。Docker 是在之上包装了 daemon 和 cli。
Kubernetes 为了实现可替换的容器运行时实现,定义了 CRI (Container Runtime Interface),现在的实现有 cri-containerd 和 cri-o 等,但是都是基于 oci/runc 的。
所以后文中使用 runc 来解释容器用到的一些技术。
2. 进程之间的隔离
如果没有 namepsace 的话,就不会有 docker 了。在容器里面,一个进程只能看到同一个容器下面的其他进程(pid),就是用 namespace 实现的。
namespace 有很多种,比如 pid namespace, mount namespace。先来通过例子说 pid namespace。
运行 runc
要运行一个 runc 的容器,首先需要一个符合 OCI Spec 的 bundle。我们可以直接通过 docker 创建这样的一个 bundle。
首先我们创建一个目录来运行我们的 runc,在里面需要创建一个 rootfs 目录。然后用 docker 下载一个 busybox 的 image 输出到 rootfs 中。
# create the top most bundle directory
$ mkdir /mycontainer
$ cd /mycontainer
# create the rootfs directory
$ mkdir rootfs
# export busybox via Docker into the rootfs directory
$ docker export $(docker create busybox) | tar -C rootfs -xvf -
然后运行 runc spec ,这个命令会创建一个 config.json 作为默认的配置文件。
进入到 containers 文件夹,就可以运行 runc 了(需要 root 权限)。
# run as root
cd /mycontainer
runc run mycontainerid
查看 namespace
容器只是在 host 机器上的一个普通进程而已。我们可以通过 perf-tools 里面的 execsnoop 来查看容器进程在 host 上面的 pid。execsnoop 顾名思义,可以 snoop Linux 的 exec 调用。
我们退出刚才的 runc 容器,先打开 execsnoop,然后在另一个窗口中在开启容器。会发现 host 上有了新的进程。
92518 90576 runc run xyxy
92524 92521 runc init
92528 92527 sh
新的进程的 pid 是 92528.
可以使用 ps 程序查看这个 pid 的 pid namespace.
$ ps -p 92528 -o pid,pidns
PID PIDNS
92528 4026534092
可以看到在宿主机这个进程的 pidns 是 4026534092。
这个命令只显示了 pid namespace, 我们可以通过 /proc 文件系统查看这个进程其他的 pidns.
$ ls -l /proc/92528/ns
total 0
lrwxrwxrwx 1 root root 0 Apr 4 23:41 [[cgroup]] -> [[cgroup]]:[4026531835]
lrwxrwxrwx 1 root root 0 Apr 4 23:28 ipc -> ipc:[4026534091]
lrwxrwxrwx 1 root root 0 Apr 4 23:28 mnt -> mnt:[4026534089]
lrwxrwxrwx 1 root root 0 Apr 4 23:27 net -> net:[4026534094]
lrwxrwxrwx 1 root root 0 Apr 4 23:28 pid -> pid:[4026534092]
lrwxrwxrwx 1 root root 0 Apr 4 23:41 pid_for_children -> pid:[4026534092]
lrwxrwxrwx 1 root root 0 Apr 4 23:28 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Apr 4 23:28 uts -> uts:[4026534090]
使用 cinf 工具,可以查看这个 namespace 更详细的内容。
$ cinf -namespace 4026534092
PID PPID NAME CMD NTHREADS [[cgroup]]S STATE
92528 92518 sh sh 1 12:perf_event:/xyxy S (sleeping)
11:memory:/user.slice/user-0.slice/session-c7.scope/xyxy
10:hugetlb:/xyxy 9:rdma:/
8:devices:/user.slice/user-0.slice/session-c7.scope/xyxy
7:freezer:/xyxy
6:cpu,cpuacct:/user.slice/user-0.slice/session-c7.scope/xyxy
5:blkio:/user.slice/user-0.slice/session-c7.scope/xyxy
4:cpuset:/xyxy
3:pids:/user.slice/user-0.slice/session-c7.scope/xyxy
2:net_cls,net_prio:/xyxy
1:name=systemd:/user.slice/user-0.slice/session-c7.scope/xyxy
0::/
可以看到这个 ns 下面只有一个进程。
到这里可以得出结论,当我们启动一个新的容器的时候,一系列的 namespace 会自动创建,init 进程会被放到这个 namespace 下面:
- 一个进程只能看到同一个 namespace 下面的其他进程
- 在容器里面 pid=1 的进程,在 host 上只是一个普通进程
docker/runc exec
那么当我们执行 exec 的时候发生了什么呢?
运行 runc exec xyxy /bin/top -b ,从 execsnoop 中可以看到 pid:
107185 107046 runc exec xyxy /bin/top -b
107192 107191 runc init
107195 107194 /bin/top -b
直接使用 runc 的 ps 命令也可以看到 pid,但是 pid 会和 execsnoop 显示的命令不一样:
$ runc ps xyxy
UID PID PPID C STIME TTY TIME CMD
root 92528 92518 0 Apr04 pts/0 00:00:00 sh
root 107625 107616 0 00:03 pts/1 00:00:00 /bin/top -b
在运行原来的 cinf 命令查看这个 namespace:
$ cinf -namespace 4026534092
PID PPID NAME CMD NTHREADS [[cgroup]]S STATE
107625 107616 top /bin/top -b 1 12:perf_event:/xyxy S (sleeping)
11:memory:/user.slice/user-0.slice/session-c7.scope/xyxy
10:hugetlb:/xyxy 9:rdma:/
8:devices:/user.slice/user-0.slice/session-c7.scope/xyxy
7:freezer:/xyxy
6:cpu,cpuacct:/user.slice/user-0.slice/session-c7.scope/xyxy
5:blkio:/user.slice/user-0.slice/session-c7.scope/xyxy
4:cpuset:/xyxy
3:pids:/user.slice/user-0.slice/session-c7.scope/xyxy
2:net_cls,net_prio:/xyxy
1:name=systemd:/user.slice/user-0.slice/session-c7.scope/xyxy
0::/
92528 92518 sh sh 1 12:perf_event:/xyxy S (sleeping)
11:memory:/user.slice/user-0.slice/session-c7.scope/xyxy
10:hugetlb:/xyxy 9:rdma:/
8:devices:/user.slice/user-0.slice/session-c7.scope/xyxy
7:freezer:/xyxy
6:cpu,cpuacct:/user.slice/user-0.slice/session-c7.scope/xyxy
5:blkio:/user.slice/user-0.slice/session-c7.scope/xyxy
4:cpuset:/xyxy
3:pids:/user.slice/user-0.slice/session-c7.scope/xyxy
2:net_cls,net_prio:/xyxy
1:name=systemd:/user.slice/user-0.slice/session-c7.scope/xyxy
0::/
可以看到现在这个 namespace 下面有两个进程了。
在 runc 的容器里面我们去看 top,会发现有两个进程,它们的 pid 分别是 1 和 13,这就是 namespace 的作用。
Mem: 8779872K used, 518678628K free, 3682912K shrd, 175384K buff, 6101996K cached
CPU: 0.0% usr 0.0% sys 0.0% nic 99.9% idle 0.0% io 0.0% irq 0.0% sirq
Load average: 4.32 3.79 3.78 2/1783 18
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
1 0 root S 1320 0.0 46 0.0 sh
13 0 root R 1316 0.0 30 0.0 /bin/top -b
3. cgroups
Namespaces 可以控制进程在 container 中可以看到什么(隔离),而 cgroups 可以控制进程可以使用的资源(资源)。
我们可以使用 lscgroup 查看现在系统上的 cgroup, 然后将它保存到一个文件中
$ lscgroup | tee cgroup.b
然后使用 runc run xyxy 启动一个名字叫 xyxy 的容器,再次查看 cgroup:
$ lscgroup | tee cgroup.a
$ diff cgroup.b cgroup.a
4a5
> net_cls,net_prio:/xyxy
12a14
> pids:/user.slice/user-0.slice/session-c9.scope/xyxy
121a124
> cpuset:/xyxy
129a133
> blkio:/user.slice/user-0.slice/session-c9.scope/xyxy
242a247
> cpu,cpuacct:/user.slice/user-0.slice/session-c9.scope/xyxy
352a358
> freezer:/xyxy
360a367
> devices:/user.slice/user-0.slice/session-c9.scope/xyxy
470a478
> hugetlb:/xyxy
478a487
> memory:/user.slice/user-0.slice/session-c9.scope/xyxy
588a598
> perf_event:/xyxy
可以看到容器创建之后系统上多了一些 cgroup,并且它们的 parent 目录是我们的 sh 所在的 cgroup.
cgroup 可以控制进程所能使用的内存,cpu 等资源。
在容器的 cgroup 中也可以加入更多的进程。
首先使用 runc 查看一下进程的 pid:
$ runc ps xyxy
UID PID PPID C STIME TTY TIME CMD
root 713 703 0 15:40 ? 00:00:00 sh
然后查看这个 cgroup 下面有哪些进程:
$ cat /sys/fs/cgroup/memory/user.slice/user-0.slice/session-c9.scope/xyxy/tasks
713
发现只有这一个。
下面通过容器的 exec 命令加入一个新的进程到这个 cgroup 中:
$ runc exec xyxy /bin/top -b
然后再次查看是否有新的 cgroup 生成:
$ lscgroup | tee cgroup.c
$ diff cgroup.a cgroup.c
输出为空,说明没有新的 cgroup 生成。
然后通过查看原来的 cgroup,可以确认新的进程 top 被加入到了原来的 cgroup 中。
$ cat /sys/fs/cgroup/memory/user.slice/user-0.slice/session-c9.scope/xyxy/tasks
713
5126
总结:当一个新的 container 创建的时候,容器会为每种资源创建一个 cgroup 来限制容器可以使用的资源。
$ ls /sys/fs/[[cgroup]]/*/user.slice/user-0.slice/session-c9.scope/xyxy/tasks
/sys/fs/[[cgroup]]/blkio/user.slice/user-0.slice/session-c9.scope/xyxy/tasks
/sys/fs/[[cgroup]]/cpu,cpuacct/user.slice/user-0.slice/session-c9.scope/xyxy/tasks
/sys/fs/[[cgroup]]/cpu/user.slice/user-0.slice/session-c9.scope/xyxy/tasks
/sys/fs/[[cgroup]]/cpuacct/user.slice/user-0.slice/session-c9.scope/xyxy/tasks
/sys/fs/[[cgroup]]/devices/user.slice/user-0.slice/session-c9.scope/xyxy/tasks
/sys/fs/[[cgroup]]/memory/user.slice/user-0.slice/session-c9.scope/xyxy/tasks
/sys/fs/[[cgroup]]/pids/user.slice/user-0.slice/session-c9.scope/xyxy/tasks
/sys/fs/[[cgroup]]/systemd/user.slice/user-0.slice/session-c9.scope/xyxy/tasks
那么如何通过 cgroup 来对资源限制呢?
默认情况下的容器是不限制资源的,比如说内存,默认情况下是 9223372036854771712:
$ cat /sys/fs/cgroup/memory/user.slice/user-0.slice/session-c9.scope/xyxy/memory.limit_in_bytes
9223372036854771712
要限制一个容器使用的内存大小,只需要将限制写入到这个文件里面去就可以了:
$ echo 100000000 > /sys/fs/cgroup/memory/user.slice/user-0.slice/session-c9.scope/xyxy/memory.limit_in_bytes
内存是一个非弹性的资源,不像是 CPU 和 IO,如果资源压力很大,程序不会直接退出,可能会运行慢一些,然后再资源缓解的时候恢复。对于内存来说,如果程序无法申请出来需要的内存的话,就会直接退出(或者 pause,取决于 memory.oom_control 的设置)。
上面这种修改 cgroup 限制的方法,其实就是 runc 在做的事情。但是使用 runc 我们不应该直接去改 cgroup,而是应该修改 config.json ,然后 runc 帮我们去配置 cgroup。
修改方法是在 linux.resources 下面添加:
"memory": {
"limit": 100000000,
"reservation": 200000
}
然后 runc 启动之后可以查看 cgroup 限制。
我们可以验证 runc 的资源限制是通过 cgroup 来实现的,通过修改内存限制到一个很小的值(比如10000)让容器无法启动而报错:
$ runc run xyxy
container_linux.go:475: starting container process caused "process_linux.go:434: container init caused \"process_linux.go:400: setting [[cgroup]] config for procHooks process caused \\\"failed to write 1000000 to memory.limit_in_bytes: write /sys/fs/[[cgroup]]/memory/user.slice/user-0.slice/session-c9.scope/xyxy/memory.limit_in_bytes: device or resource busy\\\"\""
从错误日志可以看到,cgroup 的限制文件无法写入。可以确认底层就是 cgroup.
4. Linux Capabilities
Capabilities 也是 Linux 提供的功能,可以在用户有 root 权限的同时,限制 root 使用某些权限。
先准备好一个容器,带有 Libcap,这里我们还是直接使用 docker 安装好然后导出。
root@vagrant:/home/vagrant# docker run -it alpine sh -c 'apk add -U libcap; capsh --print';
Unable to find image 'alpine:latest' locally
latest: Pulling from library/alpine
ca3cd42a7c95: Pull complete
Digest: sha256:ec14c7992a97fc11425907e908340c6c3d6ff602f5f13d899e6b7027c9b4133a
Status: Downloaded newer image for alpine:latest
fetch https://dl-cdn.alpinelinux.org/alpine/v3.13/main/x86_64/APKINDEX.tar.gz
fetch https://dl-cdn.alpinelinux.org/alpine/v3.13/community/x86_64/APKINDEX.tar.gz
(1/1) Installing libcap (2.46-r0)
Executing busybox-1.32.1-r5.trigger
OK: 6 MiB in 15 packages
Current: cap_chown,cap_dac_override,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_net_bind_service,cap_net_raw,cap_sys_chroot,cap_mknod,cap_audit_write,cap_setfcap=eip
Bounding set =cap_chown,cap_dac_override,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_net_bind_service,cap_net_raw,cap_sys_chroot,cap_mknod,cap_audit_write,cap_setfcap
Ambient set =
Current IAB: cap_chown,cap_dac_override,!cap_dac_read_search,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,!cap_linux_immutable,cap_net_bind_service,!cap_net_broadcast,!cap_net_admin,cap_net_raw,!cap_ipc_lock,!cap_ipc_owner,!cap_sys_module,!cap_sys_rawio,cap_sys_chroot,!cap_sys_ptrace,!cap_sys_pacct,!cap_sys_admin,!cap_sys_boot,!cap_sys_nice,!cap_sys_resource,!cap_sys_time,!cap_sys_tty_config,cap_mknod,!cap_lease,cap_audit_write,!cap_audit_control,cap_setfcap,!cap_mac_override,!cap_mac_admin,!cap_syslog,!cap_wake_alarm,!cap_block_suspend,!cap_audit_read
Securebits: 00/0x0/1'b0
secure-noroot: no (unlocked)
secure-no-suid-fixup: no (unlocked)
secure-keep-caps: no (unlocked)
secure-no-ambient-raise: no (unlocked)
uid=0(root) euid=0(root)
gid=0(root)
groups=0(root),1(bin),2(daemon),3(sys),4(adm),6(disk),10(wheel),11(floppy),20(dialout),26(tape),27(video)
Guessed mode: UNCERTAIN (0)
然后将这个 docker 容器导出到 runc 的 rootfs:
root@vagrant:/home/vagrant# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
root@vagrant:/home/vagrant# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5aad51652320 alpine "sh -c 'apk add -U l…" About a minute ago Exited (0) About a minute ago angry_lamarr
9b463bcb9712 busybox "sh" 20 hours ago Created lucid_yonath
7eced2fbadb0 hello-world "/hello" 20 hours ago Exited (0) 20 hours ago friendly_cori
root@vagrant:/home/vagrant# docker export 5aad51652320 | tar -C rootfs -xvf -
.dockerenv
bin/
bin/arch
bin/ash
bin/base64
bin/bbconfig
bin/busybox
bin/cat
...
最后生成一个 spec:
root@vagrant:/home/vagrant# mkdir test_cap
root@vagrant:/home/vagrant# mv rootfs/ test_cap/
root@vagrant:/home/vagrant# cd test_cap/
root@vagrant:/home/vagrant/test_cap# runc spec
root@vagrant:/home/vagrant/test_cap# ls
config.json rootfs
然后进入到容器里面验证,会发现在容器里面无法修改 hostname,即使已经是 root 了也不行:
root@vagrant:/home/vagrant/test_cap# runc run mycap
/ # id
uid=0(root) gid=0(root)
/ # hostname xintao.local
hostname: sethostname: Operation not permitted
这是因为,修改 hostname 需要 CAP_SYS_ADMIN 权限,即使是 root 也需要。
我们可以将 CAP_SYS_ADMIN 加入到 init 进程的 capabilities 的 bounding permitted effective list 中。
修改 capabilities 为以下内容:
"capabilities": {
"bounding": [
"CAP_AUDIT_WRITE",
"CAP_KILL",
"CAP_SYS_ADMIN",
"CAP_NET_BIND_SERVICE"
],
"effective": [
"CAP_AUDIT_WRITE",
"CAP_SYS_ADMIN",
"CAP_KILL",
"CAP_NET_BIND_SERVICE"
],
"inheritable": [
"CAP_AUDIT_WRITE",
"CAP_KILL",
"CAP_NET_BIND_SERVICE"
],
"permitted": [
"CAP_AUDIT_WRITE",
"CAP_SYS_ADMIN",
"CAP_KILL",
"CAP_NET_BIND_SERVICE"
],
"ambient": [
"CAP_AUDIT_WRITE",
"CAP_KILL",
"CAP_NET_BIND_SERVICE"
]
},
然后重新开启一个容器进去测试,发现就可以修改 hostname 了。
root@vagrant:/home/vagrant/test_cap# runc exec -t mycap sh
/ # hostname xintao.local
/ # hostname
xintao.local
查看 Capability
要使用 pscap ,首先要安装 libcap-ng-utils,然后可以查看刚刚打开的那两个容器的 capabilities:
root@vagrant:/home/vagrant# pscap | grep -E "13076|13177"
13065 13076 root sh kill, net_bind_service, audit_write
13168 13177 root sh kill, net_bind_service, sys_admin, audit_write
可以看到一个有 sys_admin ,一个没有。
除了修改 config.json 来添加 capabilities,也可以在 exec 的时候直接通过命令行参数 --cap 来要求 additional caps.
# runc exec --cap CAP_SYS_ADMIN xyxyx /bin/hostname cool
在容器中,可以通过 capsh 命令查看 capability:
/ # capsh --print
Current: cap_kill,cap_net_bind_service,cap_audit_write=eip cap_sys_admin+ep
Bounding set =cap_kill,cap_net_bind_service,cap_sys_admin,cap_audit_write
Ambient set =cap_kill,cap_net_bind_service,cap_audit_write
Current IAB: !cap_chown,!cap_dac_override,!cap_dac_read_search,!cap_fowner,!cap_fsetid,^cap_kill,!cap_setgid,!cap_setuid,!cap_setpcap,!cap_linux_immutable,^cap_net_bind_service,!cap_net_broadcast,!cap_net_admin,!cap_net_raw,!cap_ipc_lock,!cap_ipc_owner,!cap_sys_module,!cap_sys_rawio,!cap_sys_chroot,!cap_sys_ptrace,!cap_sys_pacct,!cap_sys_boot,!cap_sys_nice,!cap_sys_resource,!cap_sys_time,!cap_sys_tty_config,!cap_mknod,!cap_lease,^cap_audit_write,!cap_audit_control,!cap_setfcap,!cap_mac_override,!cap_mac_admin,!cap_syslog,!cap_wake_alarm,!cap_block_suspend,!cap_audit_read
Securebits: 00/0x0/1'b0
secure-noroot: no (unlocked)
secure-no-suid-fixup: no (unlocked)
secure-keep-caps: no (unlocked)
secure-no-ambient-raise: no (unlocked)
uid=0(root) euid=0(root)
gid=0(root)
groups=
Guessed mode: UNCERTAIN (0)
可看到 Current 和 Bounding 里面有 cap_sys_admin。+ep 的意思是它们也在 effective 和 permitted 中。
5. 文件系统的隔离
在容器中只能看到容器里面的文件,而不能看到 host 上面的文件(不map的情况下),做到了隔离。
Linux 使用 tree 的形式组织文件系统,最底层叫做 rootfs, 一般由发行版提供,mount 到 / 。然后其他的文件系统 mount 到 / 下面。比如,可以将一个外部的 USB 设备 mount 到 /data 下面。
mount(2)是用来 mount 文件的系统的 syscall。当系统启动的时候,init 进程就会做一些初始化的 mount。
所有的进程都有自己的 mount table,但是大多数情况下都指向了同一个地方,init process 的 mount table。
但是其实可以从 parent 进程继承过来之后,再做一些改变。这样只会影响到它自己。这就是 mount namespace。如果 mount namespace 下面有任何进程修改了 mount table,其他的进程也会受到影响。所以当你在shell mount 一个 usb 设备的时候,GUI 的 file explorer 也会看到这个设备。
Mount Namespace
一般来说应用在启动的时候不会修改 mount namespace. 比如现在在我的虚拟机中,就有以下的 mount namespace:
root@vagrant:/home/vagrant# cinf | grep mnt
4026531840 mnt 103 0,1,103,104,112,1000 /sbin/init
4026531860 mnt 1 0
4026532162 mnt 1 0 /lib/systemd/systemd-udevd
4026532164 mnt 1 100 /lib/systemd/systemd-networkd
4026532183 mnt 1 101 /lib/systemd/systemd-resolved
4026532248 mnt 1 0 /lib/systemd/systemd-logind
现在启动一个 container,可以看到有了新的 mount namespace:
root@vagrant:/home/vagrant# cinf | grep mnt
4026531840 mnt 102 0,1,103,104,112,1000 /sbin/init
4026531860 mnt 1 0
4026532162 mnt 1 0 /lib/systemd/systemd-udevd
4026532164 mnt 1 100 /lib/systemd/systemd-networkd
4026532183 mnt 1 101 /lib/systemd/systemd-resolved
4026532185 mnt 1 0 sh
4026532248 mnt 1 0 /lib/systemd/systemd-logind
root@vagrant:/home/vagrant# cinf -namespace 4026532185
PID PPID NAME CMD NTHREADS CGROUPS STATE
14013 14003 sh sh 1 12:blkio:/user.slice/yoyo S (sleeping)
11:pids:/user.slice/user-1000.slice/session-35.scope/yoyo
10:devices:/user.slice/yoyo 9:cpu,cpuacct:/user.slice/yoyo
8:memory:/user.slice/user-1000.slice/session-35.scope/yoyo
7:net_cls,net_prio:/yoyo 6:rdma:/ 5:cpuset:/yoyo
4:freezer:/yoyo 3:hugetlb:/yoyo 2:perf_event:/yoyo
1:name=systemd:/user.slice/user-1000.slice/session-35.scope/yoyo
0::/user.slice/user-1000.slice/session-35.scope
在 host 进程上查看 mount info:
root@vagrant:/home/vagrant# cat /proc/14013/mounts | sort | uniq
cgroup /sys/fs/cgroup/blkio cgroup ro,nosuid,nodev,noexec,relatime,blkio 0 0
cgroup /sys/fs/cgroup/cpu,cpuacct cgroup ro,nosuid,nodev,noexec,relatime,cpu,cpuacct 0 0
cgroup /sys/fs/cgroup/cpuset cgroup ro,nosuid,nodev,noexec,relatime,cpuset 0 0
cgroup /sys/fs/cgroup/devices cgroup ro,nosuid,nodev,noexec,relatime,devices 0 0
cgroup /sys/fs/cgroup/freezer cgroup ro,nosuid,nodev,noexec,relatime,freezer 0 0
cgroup /sys/fs/cgroup/hugetlb cgroup ro,nosuid,nodev,noexec,relatime,hugetlb 0 0
cgroup /sys/fs/cgroup/memory cgroup ro,nosuid,nodev,noexec,relatime,memory 0 0
cgroup /sys/fs/cgroup/net_cls,net_prio cgroup ro,nosuid,nodev,noexec,relatime,net_cls,net_prio 0 0
cgroup /sys/fs/cgroup/perf_event cgroup ro,nosuid,nodev,noexec,relatime,perf_event 0 0
cgroup /sys/fs/cgroup/pids cgroup ro,nosuid,nodev,noexec,relatime,pids 0 0
cgroup /sys/fs/cgroup/rdma cgroup ro,nosuid,nodev,noexec,relatime,rdma 0 0
cgroup /sys/fs/cgroup/systemd cgroup ro,nosuid,nodev,noexec,relatime,xattr,name=systemd 0 0
/dev/mapper/vgvagrant-root / ext4 ro,relatime,errors=remount-ro 0 0
devpts /dev/console devpts rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=666 0 0
devpts /dev/pts devpts rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=666 0 0
mqueue /dev/mqueue mqueue rw,nosuid,nodev,noexec,relatime 0 0
proc /proc/bus proc ro,relatime 0 0
proc /proc/fs proc ro,relatime 0 0
proc /proc/irq proc ro,relatime 0 0
proc /proc proc rw,relatime 0 0
proc /proc/sys proc ro,relatime 0 0
proc /proc/sysrq-trigger proc ro,relatime 0 0
shm /dev/shm tmpfs rw,nosuid,nodev,noexec,relatime,size=65536k 0 0
sysfs /sys sysfs ro,nosuid,nodev,noexec,relatime 0 0
tmpfs /dev tmpfs rw,nosuid,size=65536k,mode=755 0 0
tmpfs /proc/acpi tmpfs ro,relatime 0 0
tmpfs /proc/kcore tmpfs rw,nosuid,size=65536k,mode=755 0 0
tmpfs /proc/keys tmpfs rw,nosuid,size=65536k,mode=755 0 0
tmpfs /proc/sched_debug tmpfs rw,nosuid,size=65536k,mode=755 0 0
tmpfs /proc/scsi tmpfs ro,relatime 0 0
tmpfs /proc/timer_list tmpfs rw,nosuid,size=65536k,mode=755 0 0
tmpfs /sys/firmware tmpfs ro,relatime 0 0
tmpfs /sys/fs/cgroup tmpfs rw,nosuid,nodev,noexec,relatime,mode=755 0 0
可以看到这个进程的 / mount 到了 /dev/mapper/vagrant-root 上。
在 host 机器上,查看 mount,会发现这个设备同样 mount 在了 / 上。
root@vagrant:/home/vagrant# mount | grep /dev/mapper/vgvagrant-root
/dev/mapper/vgvagrant-root on / type ext4 (rw,relatime,errors=remount-ro)
所以这里就有了问题:为什么 container 的 rootfs 会和 host 的 rootfs 是一样的呢?这是否意味着 contianer 能读写 host 的文件了呢?contianer 的 rootfs 不应该是 runc 的 pwd 里面的 rootfs 吗?
我们可以看下 container 里面的 / 到底是什么。
在 container 里面查看 / 的 inode number:
/ # ls -di .
2883749 .
然后看下 Host 上运行 runc 所在的 pwd 下面的 rootfs:
root@vagrant:/home/vagrant/test_cap/rootfs# ls -id /home/vagrant/test_cap/rootfs
2883749 /home/vagrant/test_cap/rootfs
可以看到,容器里面的 / 确实就是 host 上的 rootfs。
但是他们是怎么做到都 mount 到 /dev/mapper/vagrant-root 的呢?
这里的 “jail” 其实是 privot_root 提供的。它可以改变 process 的运行时的 rootfs. 相关代码可以查看这里。这个 idea 其实来自于 lxc。
chroot
要做到文件系统的隔离,其实并不一定需要创建一个新的 mount namespace 和 privot_root 来进行文件系统的隔离,可以直接使用 chroot(2) 来 jail 容器进程。chroot 并没有改变任何 mount table,它只是让进程的 / 看起来就是一个指定的目录。
关于 chroot 和 privot_root 的对比可以参考这里。
简单来说,privot_root 更加彻底和安全。
如果在 runc 使用 chroot,只需要将 {“type”:”mount”} 删掉即可。
也可以删掉这部分,这是为 privot_root 准备的。
- "maskedPaths": [
- "/proc/kcore",
- "/proc/latency_stats",
- "/proc/timer_list",
- "/proc/timer_stats",
- "/proc/sched_debug",
- "/sys/firmware",
- "/proc/scsi"
- ],
- "readonlyPaths": [
- "/proc/asound",
- "/proc/bus",
- "/proc/fs",
- "/proc/irq",
- "/proc/sys",
- "/proc/sysrq-trigger"
]
然后创建一个新的容器,发现依然不能读写 rootfs 之外的东西。
Bind Mount
Linux 支持 bind mount. 就是可以将一个文件目录同时 mount 到多个地方。这样,我们就可以实现在 host 和 container 之间共享文件了。
在 config.json 中作出以下修改:
diff --git a/config.json b/config.json
index 25a3154..13ae9bf 100644
--- a/config.json
+++ b/config.json
@@ -129,6 +129,11 @@
"relatime",
"ro"
]
+ },
+ {
+ "destination": "/my_workspace",
+ "type": "bind",
+ "source": "worksapce_host",
+ "options" : ["bind"]
这样, host 上面的 /home/vagrant/test_cap/workspace_host 就会和容器中的 /my_workspace 同步了。可以在 host 上面执行:
root@vagrant:/home/vagrant/test_cap# echo hello > workspace_host/world
然后在 container 里面:
# cat /myworkspace/world
hello
Bind 不仅可以用来 mount host 的目录,还可以用来 mount host 上面的 device file。比如可以将 host 的 UBS 设备 mount 到 container 中。
Docker Volume
Volume 是 docker 中的概念,OCI 中并没有定义。
本质上它仍然是一个 mount,可以理解为是 docker 帮你管理好这个 mount,你只要通过命令行告诉 docker 要 mount 的东西就好了。
6. User and root
User 和 permission 是 Linux 上面几乎最古老的权限系统了。工作原理简要如下:
- 系统有很多 users 和 groups
- 每个文件属于一个 owner 和一个 group
- 每一个进程属于一个 user 和多个 groups
- 结合以上三点,每一个文件都有一个 mode,标志了针对三种不同类型的进程的权限控制: owner, group 和 other.
注意 kernel 只关心 uid 和 guid,user name 和 group name 只是给用户看的。
执行容器内进程的 uid
config.json 文件中的 User 字段可以指定容器的进程以什么 uid 来运行,默认是 0,即 root。这个字段不是必须的,如果删去,依然是以 uid=0 运行。
$ id
uid=0(root) gid=0(root)
在 host 上,uid 也是 0:
$ runc ps xyxy
UID PID PPID C STIME TTY TIME CMD
root 15223 15212 0 07:55 pts/0 00:00:00 sh
不推荐使用 root 来跑容器。但是好在默认我们的容器进程还受 capability 的限制。不像 host 的 root 一样有很多权限。
但是仍然推荐使用一个非 root 用户来运行容器的进程。通过修改 config.json 的 uid/guid 可以控制。
"user": {
"uid": 1000,
"gid": 1000
},
然后在容器中可以看到 uid 已经变成 1000 了。
$ id
uid=1000 gid=1000
在 host 上可以看到进程的 uid 已经不是 root 了:
$ runc ps xyxy
UID PID PPID C STIME TTY TIME CMD
vagrant 15348 15336 0 11:12 pts/0 00:00:00 sh
创建容器的时候默认不会创建 user namespace。
使用 User namespace 进行 UID/GID mapping
接下来我们创建一个单独的 user namespace.
在开始之前我们先看下 host 上现有的 user namespace:
$ cinf | grep user
4026531837 user 113 0,1,100,101,103,104,112,1000 /sbin/init
然后通过修改 config.json 来启用 user namespace. 首先在 namespaces 下面添加 user 来启用,然后添加一个 uid/guid mapping:
+ },
+ {
+ "type": "user"
+ }
+ ],
+ "uidMappings": [
+ {
+ "containerID": 0,
+ "hostID": 1000,
+ "size": 32000
+ }
+ ],
+ "gidMappings": [
+ {
+ "containerID": 0,
+ "hostID": 1000,
+ "size": 32000
}
然后重新运行容器,再次查看 user namespace:
$ cinf | grep user
4026531837 user 120 0,1,100,101,103,104,112,1000 /sbin/init
4026532185 user 1 2000 sh
在容器里面,我们看到 uid=1000:
$ id
uid=1000 gid=1000
但是在 host 上,这个进程的 pid=2000:
$ runc ps xyxy
UID PID PPID C STIME TTY TIME CMD
2000 15438 15426 0 11:19 pts/0 00:00:00 sh
这就是 uid/gid mapping 的作用,通过 /proc 文件也可以查看 mapping 的设置:
$ cat /proc/15438/uid_map
0 1000 32000
通过设置容器内的进程的 uid,我们就可以控制他们对于文件的权限。比如如果文件的 owner 是 root,我们可以通过设置 uid 来让容器内的进程不可读这个文件。
一般不推荐使用 root 运行容器的进程,如果一定要用的话,使用 user namespace 将它隔离出去。
在同一个容器内运行多个进程的场景中,也可以通过 user namespace 来单独控制容器内的进程。
7. 网络
在网络方面,OCI Runtime Spec 只做了创建和假如 network namespace, 其他的工作需要通过 hooks 完成,需要用户在容器的运行时的不同的阶段来进行自定义。
使用默认的 config.json ,就只有一个 loop device ,没有 eth0 ,所以也就不能连接到容器外面的网络。但是我们可以通过 netns 作为 hook 来提供网络。
首先,在宿主机上,下载 netns 到 /usr/local/bin 中。因为 hooks 在 host 中执行,所以这些 Binary 要放在 host 中而不是容器中,容器的 rootfs 不需要任何东西。
# Export the sha256sum for verification.
$ export NETNS_SHA256="8a3a48183ed5182a0619b18f05ef42ba5c4c3e3e499a2e2cb33787bd7fbdaa5c"
# Download and check the sha256sum.
$ curl -fSL "https://github.com/genuinetools/netns/releases/download/v0.5.3/netns-linux-amd64" -o "/usr/local/bin/netns" \
&& echo "${NETNS_SHA256} /usr/local/bin/netns" | sha256sum -c - \
&& chmod a+x "/usr/local/bin/netns"
$ echo "netns installed!"
# Run it!
$ netns -h
使用 netns 设置 bridge network
在 config.json 中作出如下修改,除了 hooks,还需要 CAP_NET_RAW capability, 这样我们才可以在容器中使用 ping。
binchen@m:~/container/runc$ git diff
diff --git a/config.json b/config.json
index 25a3154..d1c0fb2 100644
--- a/config.json
+++ b/config.json
@@ -18,12 +18,16 @@
"bounding": [
"CAP_AUDIT_WRITE",
"CAP_KILL",
- "CAP_NET_BIND_SERVICE"
+ "CAP_NET_BIND_SERVICE",
+ "CAP_NET_RAW"
],
"effective": [
"CAP_AUDIT_WRITE",
"CAP_KILL",
- "CAP_NET_BIND_SERVICE"
+ "CAP_NET_BIND_SERVICE",
+ "CAP_NET_RAW"
],
"inheritable": [
"CAP_AUDIT_WRITE",
@@ -33,7 +37,9 @@
"permitted": [
"CAP_AUDIT_WRITE",
"CAP_KILL",
- "CAP_NET_BIND_SERVICE"
+ "CAP_NET_BIND_SERVICE",
+ "CAP_NET_RAW"
],
"ambient": [
"CAP_AUDIT_WRITE",
@@ -131,6 +137,16 @@
]
}
],
+
+ "hooks":
+ {
+ "prestart": [
+ {
+ "path": "/usr/local/bin/netns"
+ }
+ ]
+ },
+
"linux": {
"resources": {
"devices": [
然后再启动一个新的容器。
root@vagrant:/home/vagrant/test_cap# runc run xyxy
/ # ifconfig
eth0 Link encap:Ethernet HWaddr EA:8B:9D:06:61:E5
inet addr:172.19.0.2 Bcast:172.19.255.255 Mask:255.255.0.0
inet6 addr: fe80::e88b:9dff:fe06:61e5/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:10 errors:0 dropped:0 overruns:0 frame:0
TX packets:7 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:880 (880.0 B) TX bytes:570 (570.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
可以看到除了 loop 之外,有了一个 eth0 device.
也可以 ping 了:
/ # ping 216.58.199.68
PING 216.58.199.68 (216.58.199.68): 56 data bytes
64 bytes from 216.58.199.68: seq=0 ttl=55 time=18.382 ms
64 bytes from 216.58.199.68: seq=1 ttl=55 time=17.936 ms
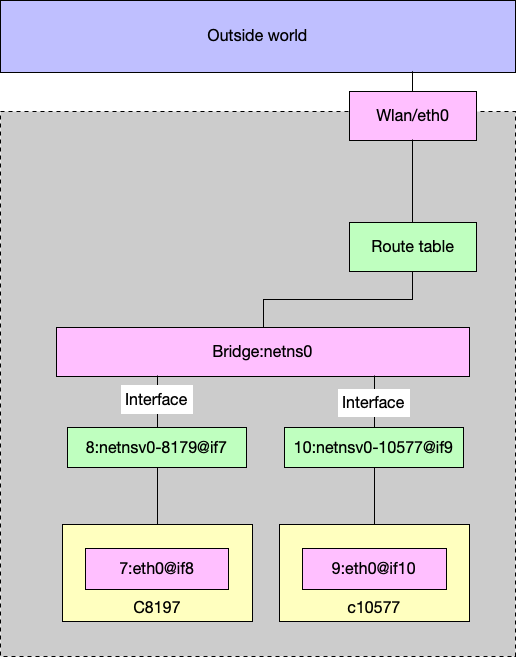
Bridge, Veth, Route and iptable/NAT
当一个 hook 创建的时候,container runtime 会将 container 的 state 传给 hook,包括 container的 pid, namespace 等。然后 hook(在这里就是 netns )就会通过这个 pid 来找到 network namespace,然后 netns 会做以下几件事:
- 创建一个 linux bridge,默认的名字是
netns0 ,并且设置 MASQUERADE rule;
- 创建一个 veth pair,一端连接
netns0 ,另一端连接 container network namespace, 名字在 container 里面是 eth0;
- 给 container 里面的
eth0 分配一个 ip,然后设置 route table.
bridge and interfaces
netns0 创建的时候有两个 interfaces,名字是 netnsv0-$(containerPid):(brctl 需要通过 apt install bridge-utils 安装)
$ brctl show netns0
bridge name bridge id STP enabled interfaces
netns0 8000.f2df1fb10980 no netnsv0-8179
netnsv0-10577
netnsv0-8179 是 veth pair 其中的一个,连接 bridge,另一个 endpoint 是 container 中的。
vthe pair
在 host 中,netnsv0-8179 的 index 是7:
$ ethtool -S netnsv0-8179
NIC statistics:
peer_ifindex: 7
然后在 container 中,eth0 的 index 也是7.
/ # ip a
1: lo: mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
7: eth0@if8: mtu 1500 qdisc noqueue qlen 1000
link/ether 8e:f3:5c:d8:ca:2b brd ff:ff:ff:ff:ff:ff
inet 172.19.0.2/16 brd 172.19.255.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::8cf3:5cff:fed8:ca2b/64 scope link
valid_lft forever preferred_lft forever
所以可以确认容器里面的 eth0 和 host 的 netnsv0-8179 是一对 pair。
同理可以确认 netnsv0-10577 是和 container 10577 中的 eth0 是一对 pair。
到这里我们知道容器是如何和 host 通过 veth pair 搭建 bridge 的。有了 network interfaces,还需要 route table 和 iptables.
Route Table
container 里面的 routing table 如下:
/ # route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 172.19.0.1 0.0.0.0 UG 0 0 0 eth0
172.19.0.0 * 255.255.0.0 U 0 0 0 eth0
可以看到所有的流量都从 eth0 到 gateway,eth0 的另一端是 netnsv0-8179,连接在 bridge netns0 上面:
/ # ip route get 216.58.199.68 from 172.19.0.2
216.58.199.68 from 172.19.0.2 via 172.19.0.1 dev eth0
在 host 上:
$ route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 192-168-1-1 0.0.0.0 UG 0 0 0 wlan0
172.19.0.0 * 255.255.0.0 U 0 0 0 netns0
192.168.1.0 * 255.255.255.0 U 9 0 0 wlan0
192.168.122.0 * 255.255.255.0 U 0 0 0 virbr0
以及:
$ ip route get 216.58.199.68 from 172.19.0.1
216.58.199.68 from 172.19.0.1 via 192.168.1.1 dev wlan0
cache
192.168.1.1 是 home route,一个真实的 bridge.
总结起来,ping 的时候,需要一出一进两条路有:
- 从 container 出去:包会从容器内,发到 virtual bridge
netns ,发送到一个真正的 route gateway,然后到外网去。
- ping 包的回复,进入到 Host 中,会走第二条路由,发送到
netns0 ,然后根据 IP 进入到容器中。
这样,我们就可以从容器中 ping 通外面的地址了。但是还有一个问题:我们是用 172.19.0.0 这个地址段去 ping 的,假设同一个局域网内有两个电脑,分别运行 docker,那都使用默认的这个地址段,不就乱套了嘛?
iptable/nat
netns 做的另一个事情是设置 MASQUERADE,这样所有从 container 发出去的包(source是 172.19.0.0/16 )都会被 NAT,这样外面只会看到这个包是从 host 来的,而不知道是否来自于一个 container,只能看到 host 的 IP。
# sudo iptables -t nat --list
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
MASQUERADE all -- 172.19.0.0/16 anywhere
至此,容器用到的一些技术基本上就讲完了。所以说容器本质上是使用 Linux 提供的一些技术来实现进程的隔离,对于 host 来说,它仍然只是一个普通的进程而已。
参考资料:
主要是一些 Linux 手册,以及最主要的,Bin Chen 的博客:Understand Container. 本文基本上是我在学习他的博客的笔记。