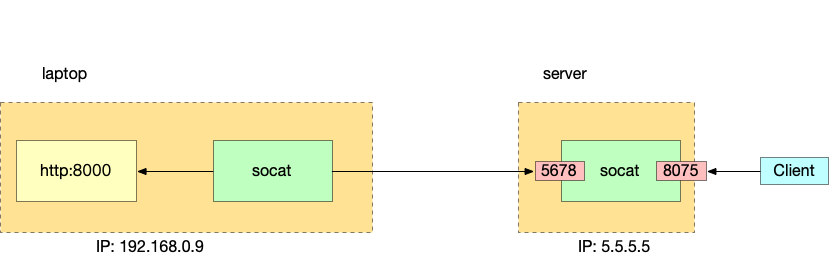
我在公司维护一个 service mesh 的平台,主要是代理用户的请求,用户的服务想调用另一个服务的时候,将请求发给我们的进程,然后我们转发到对应的服务。
今天收到一个用户工单,是说在一个 50ms 延迟的环境中,实际他们调用其他服务的延迟远大于 50ms,有 200ms 左右的延迟。我一看,这个问题和《TCP 拥塞控制对数据延迟的影响》这里的问题一样嘛,应该是个送分题。于是就去验证,如果发生在 TCP 建立连接的时候,有高延迟的话,那就没跑了。结果发现这个用户的 QPS 并没有那么低,我们的 TCP connection keepalive 有 60s,用户几乎每 5s 左右就会有一个请求。
这就麻烦了。这种问题最讨厌,因为运行的环境比较复杂,这种延迟问题可能是用户的问题,可能是我们平台的问题,可能是 SDN(我们用的一种 overlay 网络架构)的问题,也可能是我们的 kernel 的问题,排查起来极为困难。
好在最后定位到了原因,最后的结论让我大跌眼镜,我以为自己对 TCP 比较了解,没有想到竟然是一个我从没有听说过的 TCP 行为导致的!如果你听说过这个参数,1 分钟就可以解决问题。这里先卖个关子,不说是什么参数了,让我从这个问题最初的排查说起。
用户提交的工单里面只说 P99 延迟升高,metrics 监控系统里单个请求就可能波动 P99,所以首先要定位到有慢请求的具体的日志。根据用户的描述(中间经过了来回拉扯),我从日志 grep 到确实有 latency 高的离谱的请求。最终排除了用户那边的问题。
然后我找我们这个平台的开发去分析一下,为什么我们平台内部会额外花费这么多时间?得到的答复是“网络问题”。哎,不知道我在抱什么期望,几乎每次这种问题都是得到“网络问题”的结论(不过这一次可真的是,笑)。如果去找网络团队,说“你们网络有问题,请排查下”,人家能干嘛呢?至少得定位到网络哪里有问题,并且有证据才行。看来还得自己动手。考虑到我 tail -f 的日志也是可以看到类似的慢请求,感觉分析起来并不困难。
前面说过由于用户的请求大于每分钟一个,所以应该不是 TCP 建立连接的 overhead 了。这里,我找到一个 client-server IP 对进行抓包,等从日志观察到出现慢请求的时候,停止抓包,然后通过日志的关键字定位到抓包里面具体的 segment。因为是自己实现的 TCP 协议,所以 Wireshark 并不认识这个协议,我只好用 tcp.payload contains "request header" 来直接从 payload 里面过滤请求。
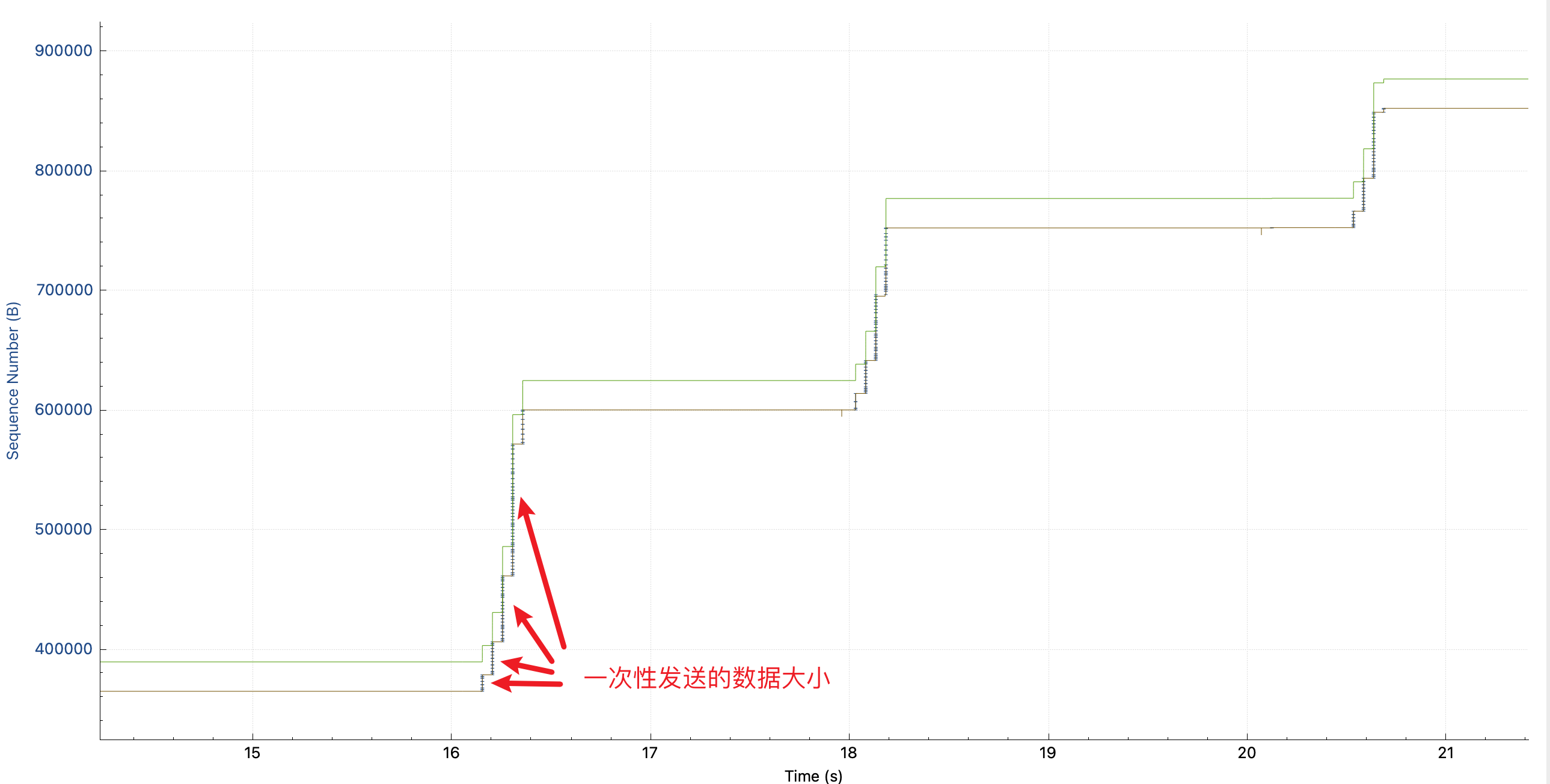
找到这个慢请求之后,发现这个 response 比较大,于是分析 tcptrace,看到的图如下(如果你看不懂这个图片的话,可以看用 Wireshark 分析 TCP 吞吐瓶颈):
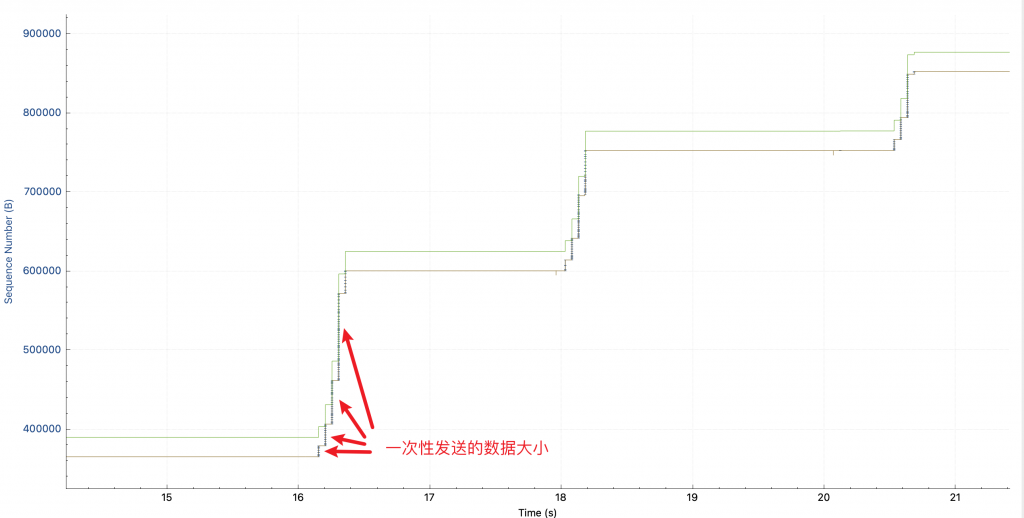
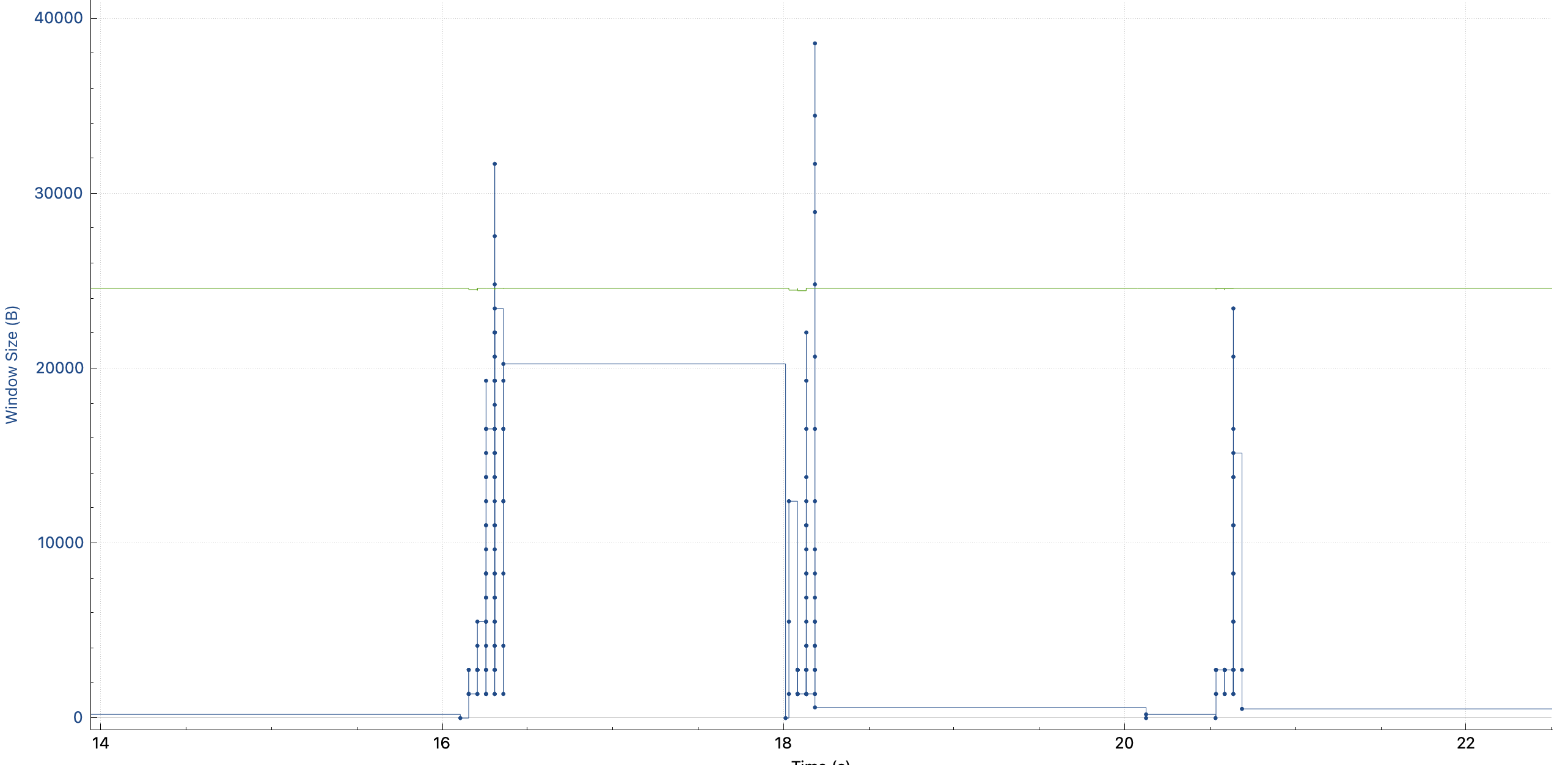
途中,每根竖线的高度可以理解为一次性发送的数据多少:第一个请求中(图中第一次升高),一开始慢慢发,越发越快,这是因为 TCP 要避免出现拥塞,所以在链接刚建立的时候会 slow start,慢慢发送,如果网络能接受,就逐渐加大发送的速度,如果发生拥塞控制了(不通的拥塞控制算法不通,cubic 使用丢包来作为拥塞控制事件)就降低发送的速度。所以开始的时候 cwnd 拥塞控制窗口在慢慢打开。其中,绿线 rwnd 并不是瓶颈,它看起来比较低,是因为我抓包的时候 TCP 连接已经存在了,没有抓到 SYN 包,所以 wireshark 并不知道 window scaling factor 是多少。
但是!!为什么 2 秒之后,在发送第二个请求的时候,这个竖线的高度又从很小开始了呢?这可是同一个 TCP 连接呀,没有重建。并且也没有丢包和重传。
我以前理解的拥塞控制算法 cubic,只会在发生拥塞事件的时候缩小 cwnd。所以我以为我看错了,但是切换到 window scaling 视图,发现 cwnd 确实每个请求都会 reset。
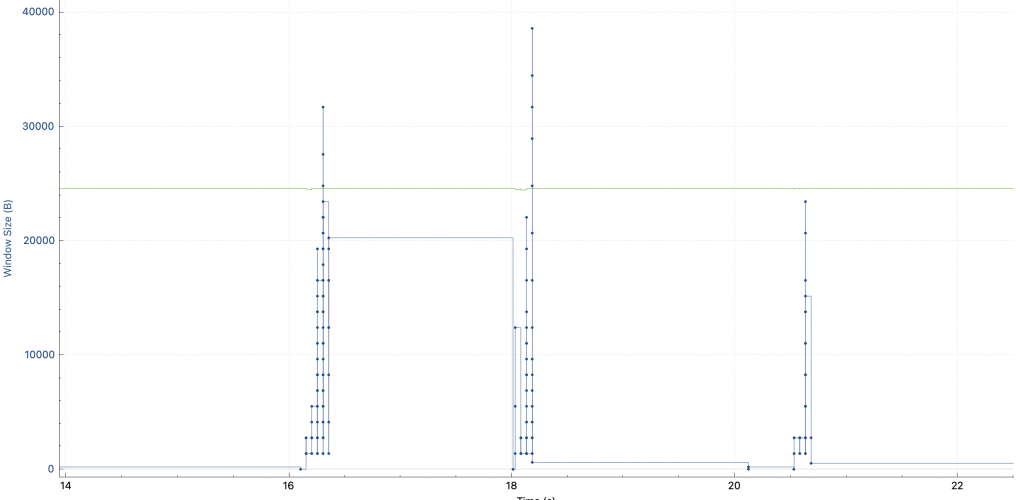
这跟我所理解的拥塞控制算法不一样!于是我搜索“why my cwnd reduced without retrans“,却几乎没有看到有用的信息。
甚至从这个回答里确认:cubic 在 idle 的时候不会 reset cwnd。这个回答倒提到了可能是应用的问题。
于是,下一步我想排出是不是我们平台的代码的 tcp 使用问题。
我写了一段简单的代码来模拟这个行为,它作为客户端,每 10s 发送 1M 的数据,然后空闲 10s,重复发送。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import socket import sys import time ip = sys.argv[1] port = int(sys.argv[2]) print("send data to %s:%d" % (ip, port)) s = socket.socket() s.connect((ip, port)) char = "a".encode() size = 1 * 1024 * 1024 data = char * size def send(): print("start sending data = %s bytes" % size) s.send(data) print("sending done") while 1: send() for count in range(10, 0, -1): print("sending next in %ds..." % count) time.sleep(1) |
在服务端用 nc 打开一个端口即可:nc -l 10121,然后在客户端运行代码:python tcpsend.py 172.16.1.1 10121,可以看到开始发送数据了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
start sending data = 1048576 bytes sending done sending next in 10s... sending next in 9s... sending next in 8s... sending next in 7s... sending next in 6s... sending next in 5s... sending next in 4s... sending next in 3s... sending next in 2s... sending next in 1s... start sending data = 1048576 bytes sending done sending next in 10s... sending next in 9s... sending next in 8s... sending next in 7s... |
我写了一个循环,使用 ss 一直打印出来这个连接的 cwnd 值:
while true; do ss -i | grep 172.16.1.1 -A 1; sleep 0.1; done
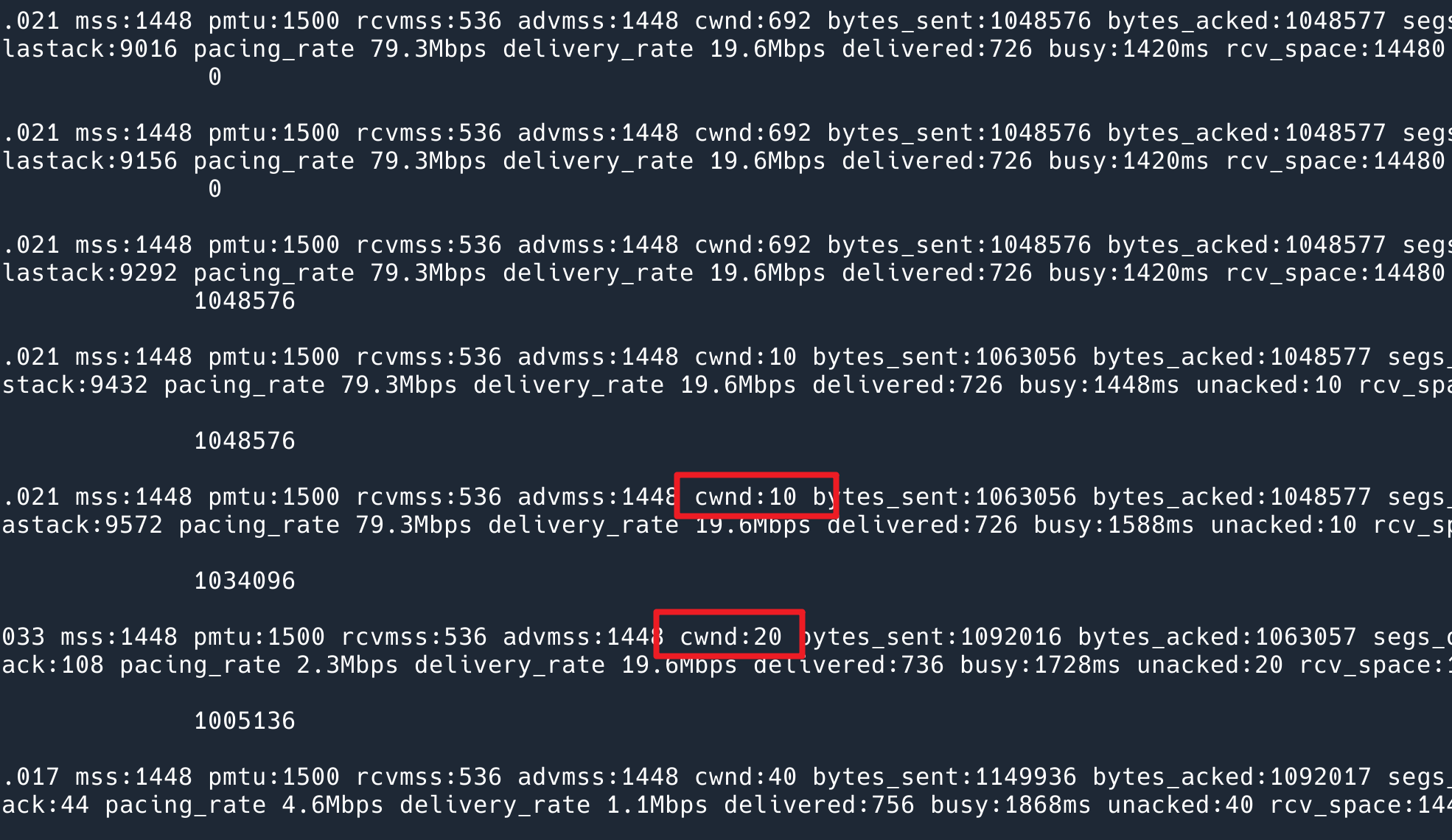
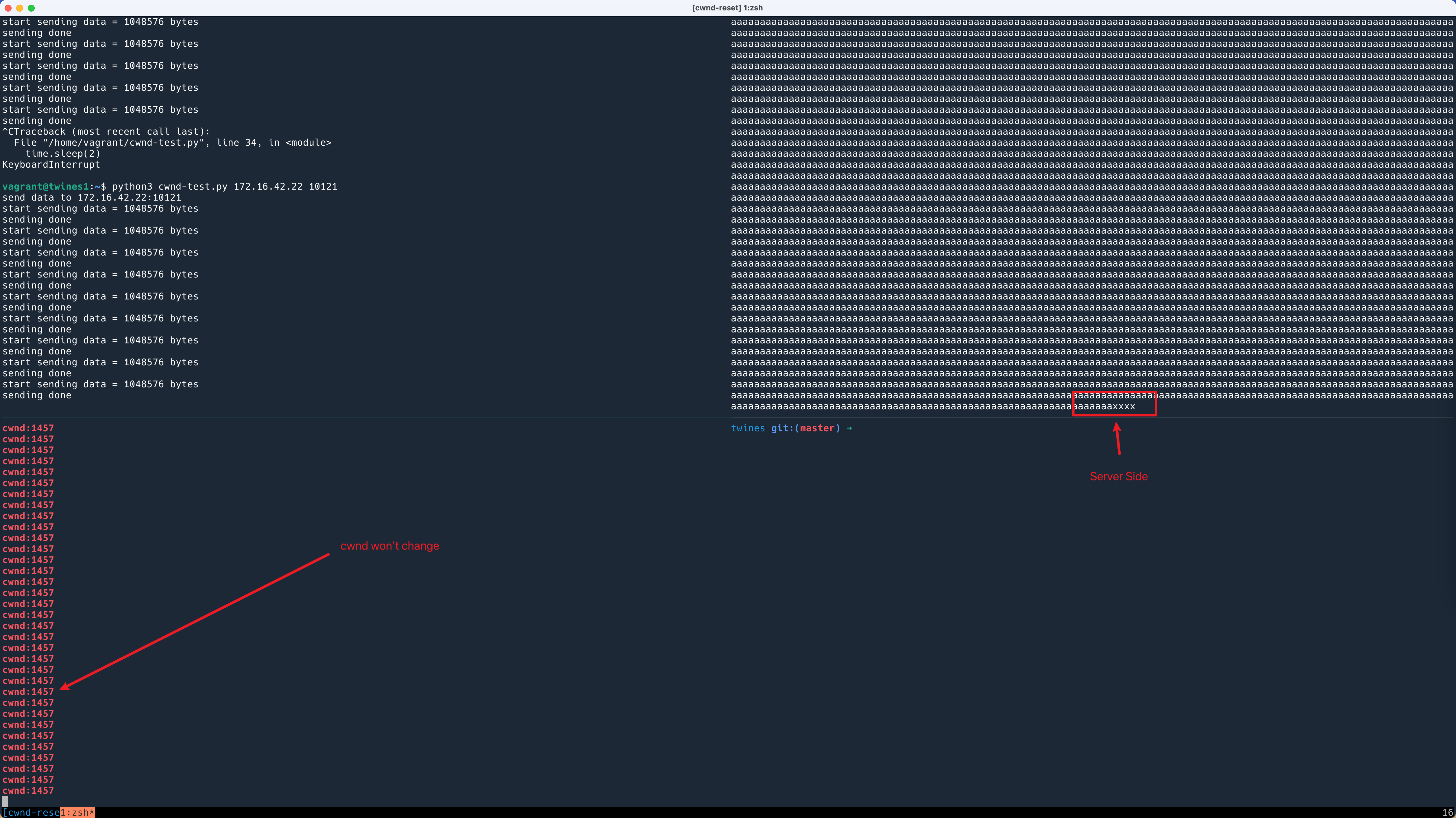
从这个命令的输出中,成功地复现了问题!排出了我们平台代码的问题:
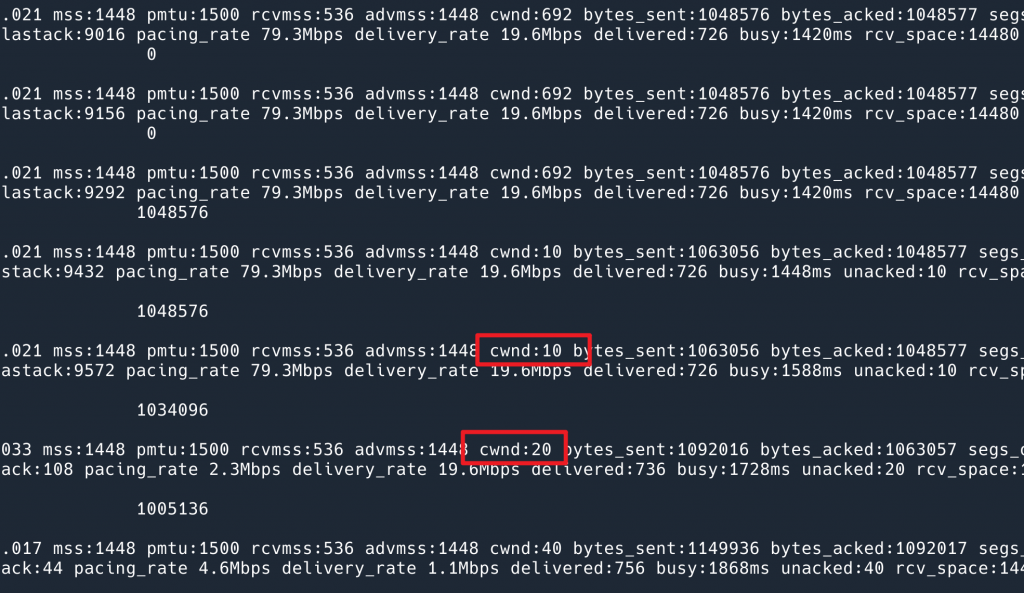 为了隐藏 IP 信息,这里只截取了部分输出,可以看到在发送完上一次的 1M 数据,10s 之后重新发送的时候 cwnd 又从 10 开始了
为了隐藏 IP 信息,这里只截取了部分输出,可以看到在发送完上一次的 1M 数据,10s 之后重新发送的时候 cwnd 又从 10 开始了
到这里我开始怀疑是 SDN 的问题了,为了验证,我去一个简单的网络环境,纯物理网,重新跑了一次我的代码,发现 cwnd 没有重置,说明就是 SDN 的问题。
于是叫来一个网络组的同事,给他看了这个。结果他也感觉很惊讶(再次卖个关子,不是只有我一个人不知道这个行为,有了些许安慰)。认为这不应该发生。但是他又对他们的代码很有信心,认为这不可能是是 SDN 的问题。然后他突然说,这应该是网络延迟造成的问题,SDN 所在的环境本身有 50ms 的延迟,我测试的物理网却没有。
于是我去找了一个有 100ms 延迟的物理网环境测试,结果……果然不是 SDN 的问题,观察到了一模一样的现象。
这时候已经进入到未知领域了。我去打开了 chatGPT 这个废物,它说是拥塞控制算法在 idle 之后会降低 cwnd。多新鲜呐,从没听说过。
我们的拥塞控制算法就用的 cubic,于是我和这个网络的同事一起去看了 cubic 的代码。如果能看到这逻辑的话,也就一切就说得通了。
看了半天,只有几百行,又是用 eBPF 探测又是测试的,愣是没找到这个会 idle 的时候 reset cwnd 的逻辑。感觉进入了死胡同,在网上搜 cubic reset cwnd when idle 也是徒劳无功。
同事想到一个点子:我们换成 BBR,看是否可以解决问题?!
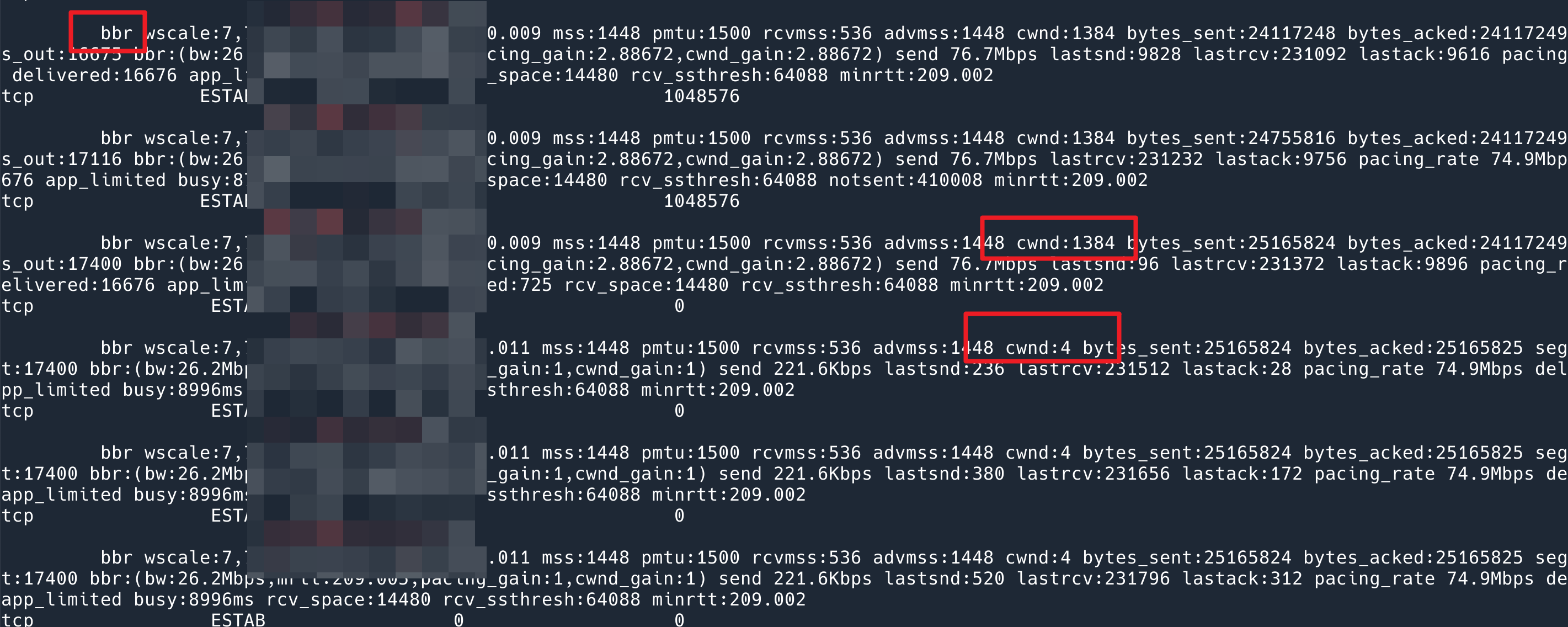
从现象来看,BBR 速度快很多。原本以为问题解决了,但是看了下我的脚本的输出,发现其实问题依然是存在的,发送完数据之后 cwnd 会降到 4,只不过 BBR window scaling 非常快,一开始发数据蹭就跳到 1384 了。
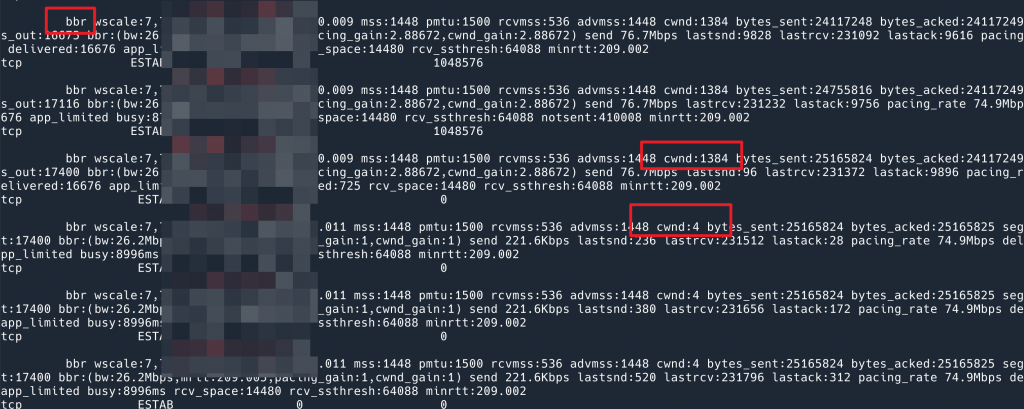 BBR 也会 reset cwnd
BBR 也会 reset cwnd
不过这倒是提醒我了:要么就是所有的算法都实现了这个 reset cwnd when idle 的鬼逻辑,要么,这根本不是算法实现的,而是系统实现的!
考虑到看了一下午 cubic 的代码了,我更倾向于后者。
接下来该怎么做呢?总不能把协议栈的代码看一遍吧。
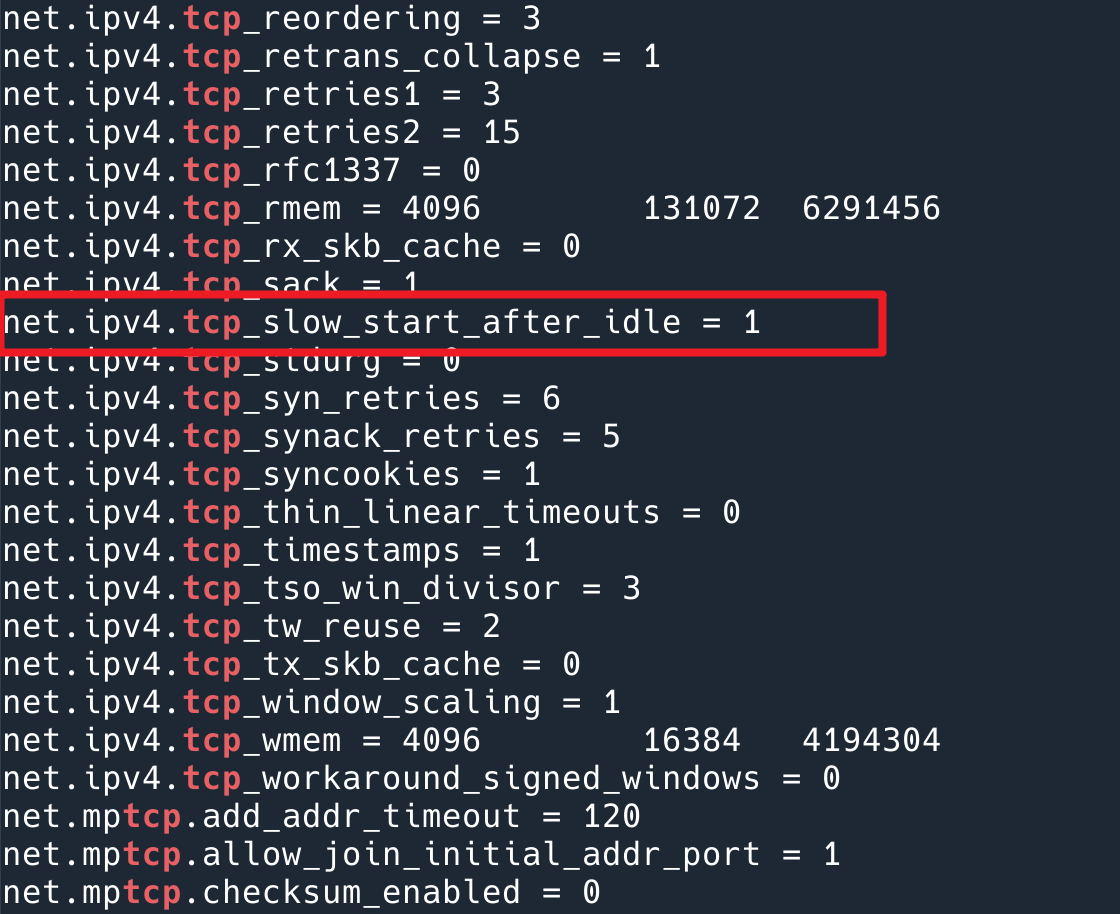
这时我靠直觉做了一个动作,我把系统 TCP 相关的配置打印出来,sysctl -a | grep tcp ,想看看有没有线索,结果一个 net.ipv4.tcp_slow_start_after_idle 直接就点醒了我。这不就正是我们遇到的问题么?
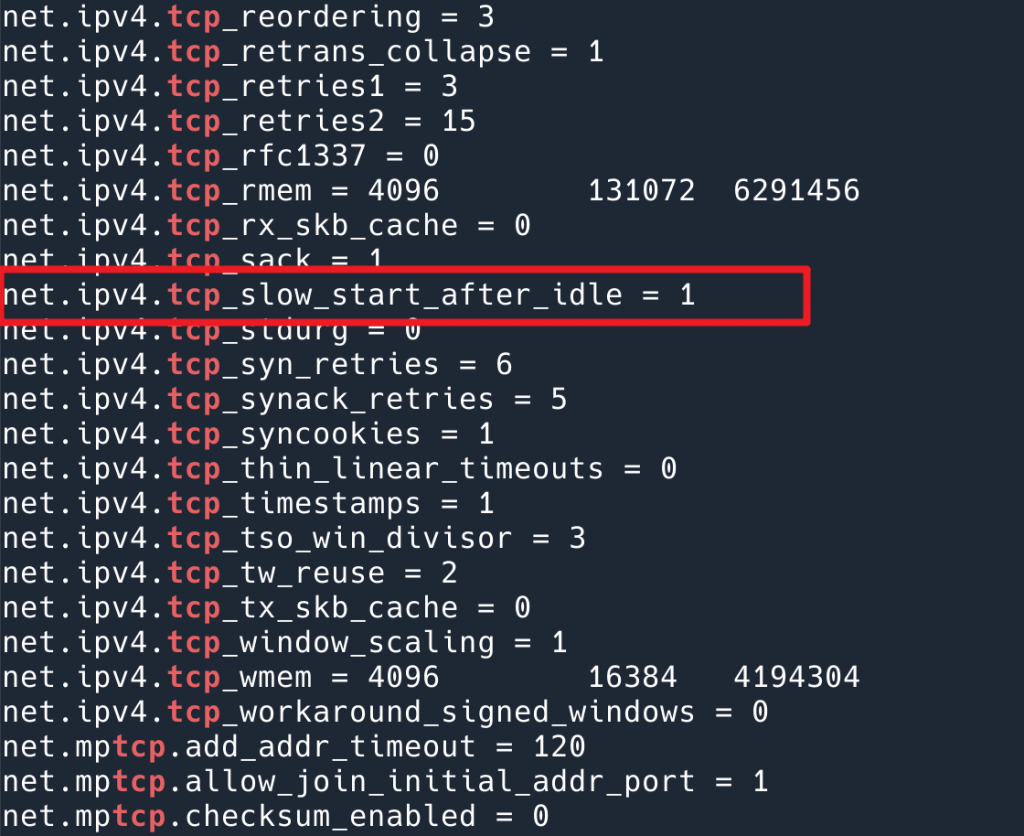 net.ipv4.tcp_slow_start_after_idle 参数,默认是 1(打开)
net.ipv4.tcp_slow_start_after_idle 参数,默认是 1(打开)
我把它改成 0,问题就完全解决了:
|
|
$ sysctl -w net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_slow_start_after_idle = 0 |
后面再观测 cwnd,稳定在 1000 左右。
有了这个行为,我再去寻找这么做的原因就简单了。
RFC2414 里面提到:
TCP 需要在 3 种情况用到 slow start(从这个表述也可以看出,slow_start_after_idle 不是拥塞控制算法应该做的,拥塞控制算法要做的是实现 slow start,TCP 的实现是使用 slow start):
- 连接刚刚建立的时候 (Initial Window)
- 连接在 idle 一段时间之后,重新启动的时候 (Restart Window)
- 发生丢包的时候 (Loss Window)
那么为什么需要 (2) idle 后要 slow start 呢?我找到了 RFC 5681,有关 “Restarting Idle Connections“ 的部分,大意是:
拥塞控制算法使用收到的 ACK 来确认网络质量从而避免拥塞,但是在 idle 了一段时间之后,没有 ACK 在传输,拥塞控制算法所保存的状态可能已经不能反映此时的网络情况了,比如发送了一波数据,直到发送完成的时候网络都比较空闲,然后连接 idle 了 10s,又要开始发数据,此时网络恰好负载比较高,如果 TCP 使用 10s 之前的知识去重新开始发送数据的话,就会造成拥塞;另外,10s 之后即使网络负载没变,网络环境可能变了(路由表切换之类的?),同样会造成 10s 之前的知识已经不适用了。
所以,这个 RFC 里面定义:
在 RTO(Retransmission Timeouts) 时间内,如果发送端没有发送任何 segment 出去,那么下次发送数据的时候,cwnd 要降低到 RW(Restart Window, RW = min(IW,cwnd)).
到此,以上的行为就解释的通了。
那么解决方法呢?因为这个参数是 by network namespace 的,我们打算在高延迟的网络中对我们这个进程关闭这个参数。
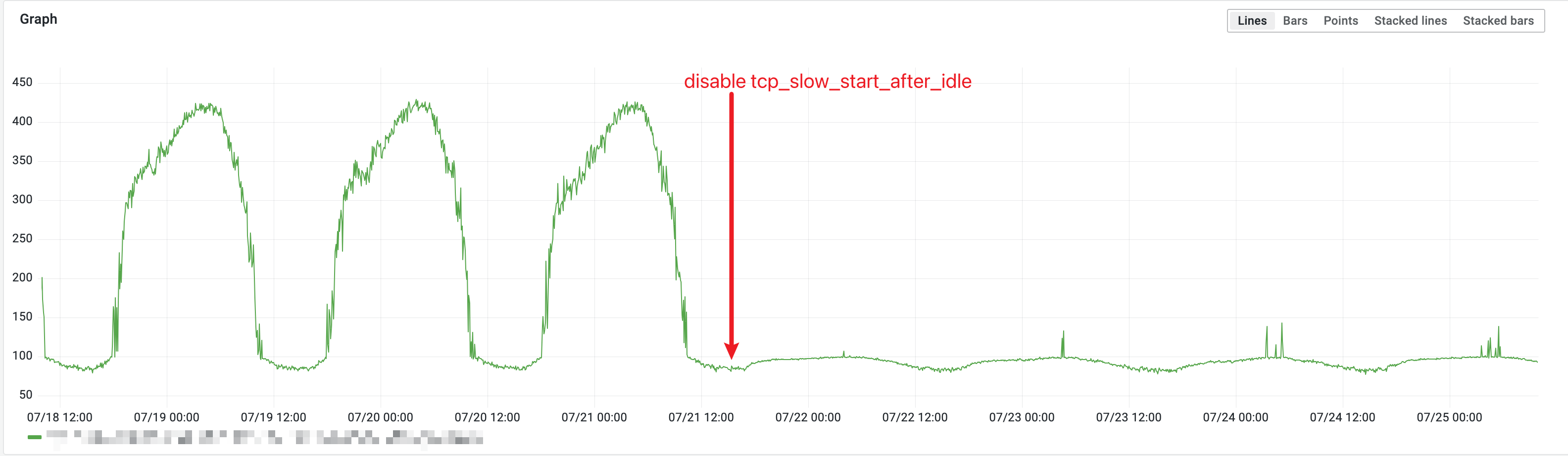
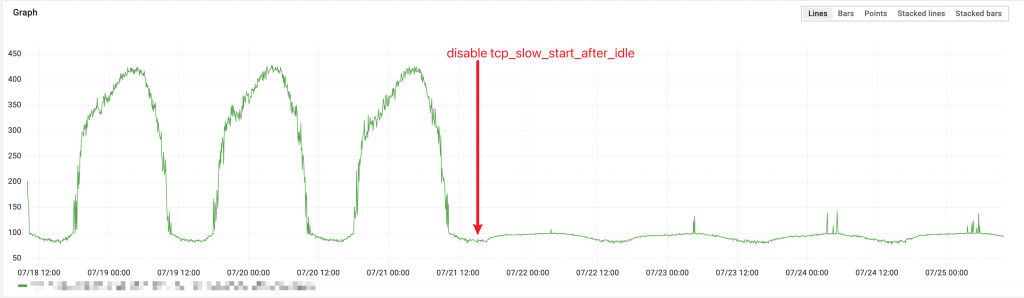 关闭
关闭 tcp_slow_start_after_idle 的效果,可以看到在业务低峰,QPS 比较低的情况下,延迟有很大改善
另一个思路是,既然 TCP 连接在 idle 的时候会 reset,那么我一直在这个连接上发送数据,不让它达到 idle 的条件,那么自然就不会被 reset cwnd 了。
将测试代码稍微修改一下,打开一个线程,每 100ms (只要低于 RTT 就可以) 发送一个 byte:
def start_keepalive(socket):
while 1:
socket.send("".encode())
time.sleep(0.1)
t = threading.Thread(target=start_keepalive, args=[s], daemon=True)
t.start()
然后用这个命令一直打印出来 cwnd 的参数:
while true; do ss -i | grep 10121 -A 1 | grep -Eo "cwnd:[0-9]+"; done
结果发现,cwnd 果然保持不变了。
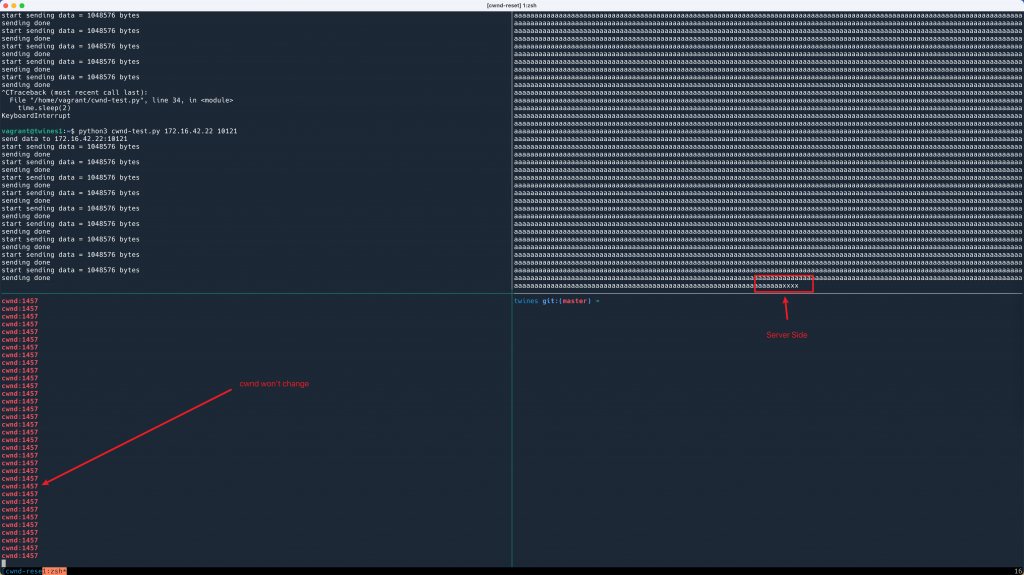 可以看到 cwnd 一直保持在相同的数值,
可以看到 cwnd 一直保持在相同的数值,a 是正常数据,而 x 是无论如何每 100ms 发送一次的冗余数据。
如果无法修改系统参数的话(比如,同一个系统上运行了很多服务,不想去影响所有的服务),可以通过这种 keepalive 的方法来解决。代价就是需要稍微消耗一些带宽。
几个细节:
为什么我一开始在延迟低的物理网测试的时候没能复现呢?
其实也是有一样的问题的,只不过我上面那个 while 循环,有 sleep 0.1,因为环境的延迟太低,所以只是命令无法显示出来而已。cwnd 也会 reset to zero 的。
RFC 5681 提到:Van Jacobson 最初的提议是:当发送端在 RTO 时间内没有收到 segment,那么在下次发送数据的时候,cwnd 降低到 RW。这样是有问题的,比如,在 HTTP 长连接中,idle 一段时间之后,Server 端开始发送数据,本应该 slow start,这时候 client 突然又发送过来一个请求,会导致 server 端不再 slow start。故改成了目前这样:数据的发送端如果在 RTO 那没有发送过数据,要 slow start。
前面的文章中,TCP 拥塞控制对数据延迟的影响 我们使用长连接试图解决长肥管道慢启动延迟高的问题,是错误的。
这个参数目前看只是一个系统参数。应用不可以通过 setsockopt() 来修改,原因可以看这个讨论。本质上跟我们在 TCP 拥塞控制对数据延迟的影响 中讨论的一样,这个参数和网络环境有关,而不能让应用自己去设置。