上次在写了之后《有关 MTU 和 MSS 的一切》之后,最近又有了一个问题,苦苦思索了一个周,终于得到了答案。现在一想问题的答案简单而有效,但是中午吃饭的时候和几个同事讨论,我们都没有很快想到这个,所以还是觉得值得记录一下。
首先我要花一些篇幅来描述一下这个问题。因为和同事交流的时候发现大家会以为我在问另一个问题。
我们知道如果 IP 包的 size 整个大于 MTU 的话,那么 3 层就会负责 fragmentation,即讲一个大包拆成多个小包单独发送。那么我的问题是,三层在将数据从自己这边传给下一个 hop 的时候,只知道自己的 MTU,而不知道对方的 MTU,那么如果对方的 MTU 小于自己的时候,怎么拆包发给它呢?
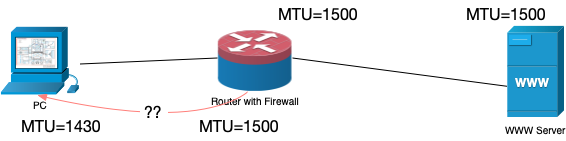
如何将数据发给 MTU 比自己小的另一侧?
在之前的文章中,我们知道,TCP 因为是有连接的协议,连接在建立的时候,就有 MSS 的协商,如果中间设备的 MTU 比较小,就会 MSS clamping,这样就能保证两端都不会发送超过 MTU 的数据。
但是对于面向无连接的协议,比如 UDP,怎么处理这个问题呢?
首先,不处理肯定是不行的,因为理论上收到了 MTU 比自己能接受的 MTU 还要大的包,就会被丢弃。UDP 有没有重传机制,那么就一直发,一直丢,发送端也不知道发生了什么事情。
然后想到了了 PMTUD,那篇文章也提到过。但是 PMTUD 的目的是:避免进行 IP fragmentation,先通过 PMTUD 得知链路上的 MTU 是多少,然后在后续的通讯中保证不发送大于 MTU 大小的包。这不是我问的问题,我的问题是,如果对方的 MTU 比较小,这时候 Don’t Fragmentation 又没有设置,三层是怎么拆包的。并且,向 UDP 这种协议,有一些场景也不现实,难道 DNS 一次请求之前我都要发送多个包去探测 MTU 吗?效率也太低了。我还实际去抓了包,确实是没有 PMTUD 的。
下一个得到的答案是:对方会把包丢弃,然后发送一个 ICMP 回来,Type=3 (Destination Unreachable) and code=4, packet too big and DF is set. 表示我收到一个包,大的我无法转发,但是这个包又设置了 DF,让我不要拆包,没办法,只好丢了,你要知道。这个答案我也不是很满意,因为按照语义,这个 Code=4 的意思是 DF is set 我才丢的。而我想问的是,DF 没有 set,你随便拆,你要怎么知道对方的 MTU 然后拆包呢?
这些答案是我和同事们讨论过的,好像都可以解决问题,但是又好像都不太合理。
其中搜索了一些资料,感觉都没有直接回答这个问题,大部分文章提到这部分的时候好像都直接略过了,只是介绍如何根据自己这一端的 MTU 进行 fragmentation。有一些感觉比较离谱,比如这里,说路由器知道对方的 MTU。我就好奇了,它怎么知道的?IP 协议没有任何机制协商 MTU 呀。

我还自己做了一个实验,进行验证。搞了两个虚拟机,A MTU=1000,B MTU=500,然后用 A 去 ping B,size=800,结果发现 A 到 B 没有 fragmentation,B 到 A 有 fragmentation。但是两边都能收到包(我猜这个是实验环境的问题,因为两个 VM 中间的网络比较简单,所以网卡都能处理这种不合理的包?)至少,我们证明了在 IP 这一层,它不会去关心对方的 MTU 是什么,只会根据自己这边的 MTU 去 fragmentation.
某天有同事从深圳来新加坡出差,我们一起吃饭,又提起这个话题,他直接说:UDP 不管这个问题呀!
对哦,这就是我为什么在 UDP 相关的资料中都没发现和 MTU 有关的东西。这个协议太简单了,不处理这个问题。如果你要基于 UDP 实现一个协议,就要自己处理超过 MTU 的问题。
这是我基于自己读了一些 RFC 之后认为的答案,如果有错误,欢迎指出。
比如:
DNS 协议规定:RFC 1035 DNS 响应不能超过 512 bytes(UDP message),如果超过 512 bytes,在 512 bytes 之后的内容就会被截断。512 bytes 的内容是安全的吗?(链路上所有的节点都能正常接受这个 size?),我们来算一下:2 层 Ethernet 最小的 Frame 是 576 bytes, IP header 20 bytes + IP option 0-40 bytes, UDP header 8 bytes, 所以在 IP option =0 的时候,512 bytes 的 UDP message 最终的 Ethernet Frame 是: 512 bytes + 20 bytes + 0 + 8 = 540 bytes, 小于 576 bytes。是安全的。IP option 在小于 576 – 540 = 36 bytes 的时候是安全的,可以说,在绝大部分情况,这个大小是安全的。
这是 DNS 对 MTU 问题的解决办法:我只发送全世界最小的二层包,总没问题了吧?
与之类似解决方法的是 TFTP 协议(RFC 1350),默认是 512 bytes,但是可以配置。不过用户要自己对配置负责,配置不当就直接丢包。
KCP 也是有一个默认值 1400 bytes,但是支持通过函数 ikcp_setmtu 来设置。因为本质上这个是 “Pure algorithm protocol”,你可以有自己的 MTU 探测实现。
最后是 QUIC,这个最具有代表性。它的处理方法是:
- QUIC 的实现应该(RFC 用的是 SHOULD)使用 PMTUD,并且应该记录每一个 source ip + dest ip 的 MTU
- 但是如果没有 PMTUD 的话,也可以认为 MTU=1280,协议设置 max_udp_payload_size = 1200 bytes,如此,按照上面的算法的话,IPv4 的 header 最多可以有 52 bytes,IPv6 的 header 可以有 32 bytes,正常情况下也够用
- 如果链路上连 1280 的 PDU 都支持不了,QUIC 就会这个 UDP 无法使用(和端口连不上等同),然后会 fallback 到 TCP
对于3,还有一个问题,就是 QUIC 如何知道 1280 的 MTU 能不能传呢?我发现了这个协议一个很神奇的设置,就是它的每一个 IP 包大小都是一样的,比如 MTU=1280,那么发送的每一个二层包都是 1280 bytes,不够的就 padding 到 1280,如果传不过去,那么握手包也传不过去,一开始就被丢弃了。
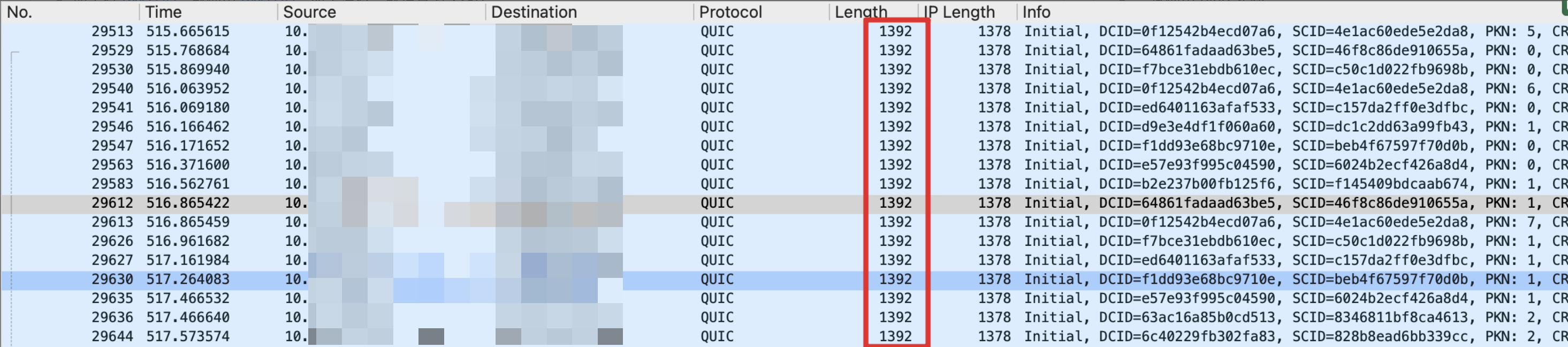
QUIC 所有的包都一样大
很绝妙,不过我觉得有一点要注意的是,中间 overlay 协议在设计的时候可能要注意这一点:比如 Overlay 要在中间插入 100 bytes 的数据,MTU 设置为 1400,那么就不应该接收 1450 的包。即,即使有时候没有 100 bytes 的数据要插入的时候,也应该 padding 100 bytes 进去。否则的话,像 QUIC 这种协议,就可能握手阶段没问题,让它过去了,协议认为 MTU=1450,但是后面可能会频繁丢包。
最后,重申一下我对 QUIC 不是很了解,只是浅读了一些资料。如果读者发现本文错误,欢迎指出。