前言:这个系列(以及我的博客)好久不更新了,原因有两个,一个是我在学习用双拼打字,手跟不上脑子,写的东西读起来不顺畅,不过现在已经复健了。双拼确实能极大地减少按键次数,在 AI 的时代,每个人需要和 AI 对话,那么怎么赶上时代的潮流,从芸芸众人脱颖而出呢?我的建议是:练习打字,打字打得快,和 AI 沟通效率高,做 AI 时代的佼佼者;第二个原因是我最近在思考人生的意义。上次录制博客 laike9m 提到了存在主义危机,第一次知道这个词,我觉得我就是陷入了存在主义危机。苦苦思索人生的意义,没有思考出什么结果。看了一些书,看的是莫言,刘震云,看了一本漫画,《我以为这辈子完蛋了- [美]艾莉·布罗什》,让我思考了很多。但是依然没有结论。人生没有思考明白,问题先来了。
有一天,我们在上线新的设备,上线之后,用户反馈他们的服务出现了网络超时的错误。超时的概率大概在 0.01%,并且出现的时间和我们上线新的设备的时间完全一致。我们把新上线的设备隔离(不再处理线上流量)用户的服务没有再出现错误了。
我们对新设备的性能非常有信心,不应该比原来的设备转发速度还低。这中间一定是有什么问题。
拓扑图简化如下:
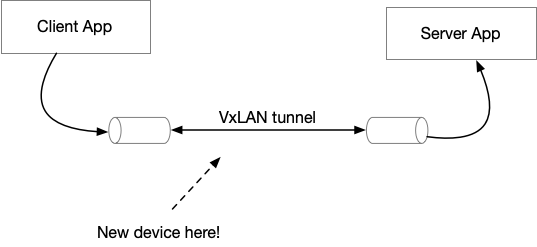
其中,用户的 Client 和 Server 侧之间的网络是无法连通的,我们的网络设备会把用户的 Ethernet 包封装到 UDP 里面发送(overlay,原理就和 VPN 一样),这个设备提供了封装,转发的服务。但是用户的 Client 和 Server 感受不到中间这个 tunnel 的存在,Client 和 Server 之间的 IP 地址是可以直接 ping 通的,TCP 也是可以连通的,全靠我们的设备在中间做了转发。
我们做了一些常规检查没有发现问题,然后重新上线新的设备,要求用户在 Server 端进行抓包。得到文件如下。在一般的问题分析中,我们一般只看 packet 的 header 就够了,不需要看 application 层的 TCP payload,所以在抓包的时候我们会截断 TCP 的 payload,这样,在下载抓包文件和交流的时候,更方便一些,并不影响问题的分析。
请据此分析,造成小概率超时的问题在哪里。
如果没有头绪,请看下面的提示。
在找不到问题的时候,我们会对比正常情况下的表现,通过正常和异常的情况的不同来寻找线索。以下是原有环境的抓包文件,没有超时的请求。
对比两个抓包问题,请分析问题的根因。
==抓包破案录==
这篇文章是抓包破案录系列文章(之前叫做《计算机网络实用技术》,后来改名了)中的一篇,这个系列正在连载中,我计划用这个系列的文章来分享一些网络抓包分析的实用技术。这些文章都是总结了我的工作经历中遇到的问题,经过精心构造和编写,每个文件附带抓包文件,通过实战来学习网络抓包与分析。
如果本文对您有帮助,欢迎扫博客右侧二维码打赏支持,正是订阅者的支持,让我公开写这个系列成为可能,感谢!
如果您正在阅读的是题目类的文章,这个目录内容正好用来隔离其他读者的评论。读完题目可以稍作暂停,进行思考,继续向下滑动,可能会被其他的读者剧透答案。
没有链接的目录还没有写完,敬请期待……
- 序章
- 抓包技术以及技巧
- 理解网络的分层模型
- 数据是如何路由的
- 网络问题排查的思路和技巧
- 不可以用路由器?(答案和解析)
- 网工闯了什么祸?(答案和解析,阅读加餐!)
- 重新认识 TCP 的握手和挥手(答案和解析)
- 3.5 秒初始延迟问题 (答案和解析)
- 网络断断续续…… (答案和解析)
- 延迟增加了多少?(答案和解析)
- 压测的时候 QPS 为什么上不去?(答案和解析)
- TCP 下载速度为什么这么慢?(答案和解析)
- 请求为什么超时了?(答案和解析)
- 0.01% 的概率超时问题 (答案和解析)
- 后记:学习网络的一点经验分享
与本博客的其他页面不同,本页面使用 署名-非商业性使用-禁止演绎 4.0 国际 协议。
感觉这是人生必然的一课啊!人生的意义大约就是一直在寻找意义这个过程吧,加油!
> 苦苦思索人生的意义,没有思考出什么结果。
我时不时的就会把《士兵突击》拿出来看一遍
直接语音输入比打字更快
语音输入嗓子会比较累,而且遇到出错、不流畅的情况,识别得不对,修改起来很麻烦。
我一直在使用五笔输入法,不光打得比全拼快,而且大部分时候都不需要选词,能省不少心力,甚至还可以在打字的时候闭眼让眼睛休息一会儿~
双拼的问题就是候选词重叠的问题比较大。语音输入就算了,太慢了。跟不上思维。
情分析问题 -> 请…
谢谢,已改正
现在有一些基于大模型的语言识别软件在尝试用大模型纠正识别错误和润色了,不过解决不了嗓子累的问题。
盼了好久终于更新了,虽然我是一个菜鸡
抓包里完全看不出来有超时呀。难道是没开gso然后处理不过来丢包了?
timeout包中的2135号包开始重传,后面的把之前的包都重传了一遍,对比分析正常的数据包,应该是接收方没有打开GRO导致数据没有处理过来,能在中间网络上抓个包可能更容易看出来^_^,不知道分析的对不对
观察到一个现象:正常情况下捕获的 VXLAN/TCP 包都很大,但加入新设备后的数据包长度都是 1514B。这说明这些小包并没有使用网卡 Offload,导致大 TCP Segment 被 CPU 拆分成多个 MTU 包。由于 CPU 处理拆包和封装的开销较大,在高并发或大包场景下可能出现 ACK 延迟或请求超时。
因此可以怀疑:新加入的设备没有启用网卡 Offload 功能,从而引发了超时问题。
https://www.kawabangga.com/posts/4983 这篇文章很棒
谢谢!
很接近了,不过这里是 server 端抓包,方向是 server 收到的包比较多。
两个包还有个区别
正常的:server 会给 client 发 zerowindow 随后又发 window update,server 处理的慢但节奏在 server 这里。
超时的:没看到窗口更新的包 都是 client 给 server 发送,2136 包到 2149包能看到重试 15次。
要说 server 处理的慢,只看到一次超时后面全部正常,你说中间设备处理的有问题吧 它还只有0.01的超时概率
zero window 在这里其实是一个好的现象。
数据进入的处理路径是:
NIC -> Kernel process -> tcp connection buffer -> 应用程序读取
正常的:
正是因为 kernel 处理的速度够快,才能填满 buffer,应用程序处理的不够快,导致 buffer 填满了,接收端发送 zero window 让发送端暂停发送。
超时的:
因为 kernel 处理的带宽(由于没有开启 LRO)变慢,导致无法填满 buffer,所以不会出现 zero window。同时,由于 NIC 收包比较快,很可呢是 kernel 处理不过来,导致了丢包。
我一直用的五笔输入法,86 版的,始终觉得输入还是用五笔科学
你的新设备(可能是交换机或防火墙)的入站或出站缓冲区(Buffer)太浅了。