之前写过一个服务发现系统,叫做 prometheus-http-sd,给 Prometheus 查找监控的目标使用。它的原理很简单,每当 Prometheus 请求 prometheus-http-sd 服务的时候,这个服务就执行用户的脚本,拿到 targets,然后返回。定位是作为一个中间系统,对接 Prometheus 和其他的 CMDB。用户通过写一个简单的脚本,可以将任何系统返回的结果,转换成 Prometheus 的 API 格式返回给 Prometheus.
于是就会有一个自然而然的需求:缓存。
如果部署了 100 个 Prometheus 采集端,那么每一个都需要来做服务发现,如果每 60s 请求一次,那么每分钟就有 100 次请求。监控目标的变更没有那么频繁,而且分钟级的不一致是可以接受的(Prometheus 原生的这个 HTTP 做服务发现的模式已经是分钟级不一致了)。所以我们可以把用户脚本的执行结果缓存起来,至少缓存1分钟,拿一次运行结果直接返回给这分钟内的其他请求。(考虑到内部系统一半写的比较差,这样可以节省巨大资源,笑)
以上是背景。这个缓存功能上线以后,我见到了10万行的一个错误 stack traceback:
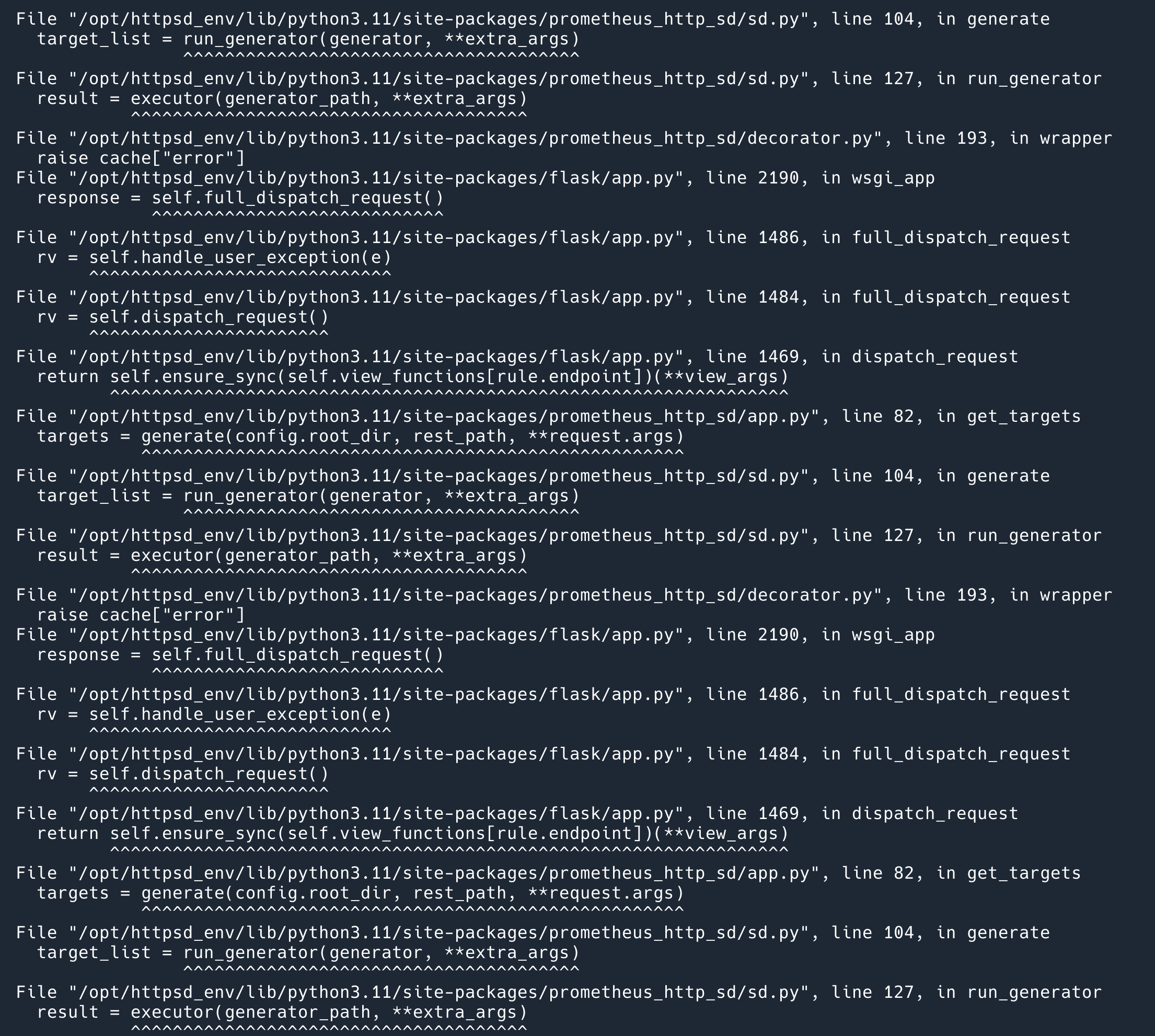
这是异常日志的一部分,不知道读者是否能发现什么端倪。这个服务是开源的,存在 bug 的版本是这个。
首先第一个比较明显的 bug 是,在用户脚本正常执行的时候才设置了缓存过期的时间,在发生异常的时候没有设置 expire 时间。这就导致了,一旦用户的脚本出发了 Exception,这个 Exception 就会进入到缓存中,并且不会过期,导致以后这个脚本永远会命中缓存返回 Exception。

但是为什么我会看到这么奇怪的 stack 呢?
看到这个 Exception,我的第一个想法是有什么地方拿到这个 Exception 之后,又作了修改,然后 set 回去,修改的时候又包上了当前的 stack,所以越包越长。但是在代码中看了好几遍,这个缓存都没有重新设置的地方。然后又用 PDB 去debug,跟着走了一遍代码,一切都是正常的。最后又用 watchpoint 这个库跟踪了一下,结果也是一样,cache 没有被重新修改过,只有第一次触发有 set。
那好吧,然后我又想到,会不会在 raise Exception 的时候,这个 stack 其实就是这样的了呢?又用 pdb 去跑了几遍代码,发现不存在这么深的 stack。(后来想了一下,Python 默认的 frame 最大好像是 1000,如果真是这样的 stack 的话肯定已经 stack overflow 了!)
想到这里已经没了思路,决定回家睡一觉。
第二天一醒,问题就解决了。
现在抛去一些无关的逻辑,最小化一个复现的 Case 是这样:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import traceback d = {"e": Exception("foobar")} def raise1(): raise d['e'] def raise2(): raise1() if __name__ == "__main__": for _ in range(3): try: raise2() except Exception as e: traceback.print_exception(type(e), e, e.__traceback__) |
其中 d 是我们的缓存,上来就已经有了,然后,我们在代码中会 raise 这个 Exception 3 次。和 prometheus-http-sd 中是一样的逻辑。
看似无害,其实是有 bug 的。
它的输出如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
Traceback (most recent call last): File "/private/tmp/1.py", line 17, in <module> raise2() File "/private/tmp/1.py", line 11, in raise2 raise1() File "/private/tmp/1.py", line 7, in raise1 raise d['e'] Exception: foobar Traceback (most recent call last): File "/private/tmp/1.py", line 17, in <module> raise2() File "/private/tmp/1.py", line 11, in raise2 raise1() File "/private/tmp/1.py", line 7, in raise1 raise d['e'] File "/private/tmp/1.py", line 17, in <module> raise2() File "/private/tmp/1.py", line 11, in raise2 raise1() File "/private/tmp/1.py", line 7, in raise1 raise d['e'] Exception: foobar Traceback (most recent call last): File "/private/tmp/1.py", line 17, in <module> raise2() File "/private/tmp/1.py", line 11, in raise2 raise1() File "/private/tmp/1.py", line 7, in raise1 raise d['e'] File "/private/tmp/1.py", line 17, in <module> raise2() File "/private/tmp/1.py", line 11, in raise2 raise1() File "/private/tmp/1.py", line 7, in raise1 raise d['e'] File "/private/tmp/1.py", line 17, in <module> raise2() File "/private/tmp/1.py", line 11, in raise2 raise1() File "/private/tmp/1.py", line 7, in raise1 raise d['e'] Exception: foobar |
可以看到,每一次这个 Exception 被 raise,它的 stack 都加深了。
到这里问题就明了了:raise Exception 这个操作本身就会修改这个 Exception。
从 PEP 3134 中发现,Python3 已经把和一个 Exception 有关的 traceback,局部变量等放到 Exception 对象中了。这里也说,你不能明确地指定一个 Python Exception 的 traceback。按照我们上面中代码的行为看,就是,Python 在 raise Exception 的时候,会把当前的 stack 写到 traceback 中,但是如果当前已经有 __traceback__ 了的话,就会把之前的 traceback 保留住。(但是没有找到相关资料和代码,欢迎读者补充)
所以,这里每次 raise 一次被缓存下来的 Exception,这个 stacktrace 就会加深一次。
那么问题如何解决呢?我觉得 Exception 不应该被缓存下来,从 Python 的机制可以看出,Exception 被 raise 的时候,应该是 Exception 真正发生的时候。而在我们的这个场景中,Exception 并没有发生,而只是我们返回了之前的一个缓存。缓存 Exception 对用户也有困扰,这个 Exception 看起来就像是:“我运行了你的代码,你的代码出错了”,而实际上用户的代码并没有执行过。所以我觉得这里应该缓存下来一个错误信息,string 就可以了。而不应该缓存 Exception 实例。
小插曲
在做以上实验的时候,我发现用这个代码,就会触发一个奇怪的错误:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import traceback e = Exception("foobar") def raise1(): raise e def raise2(): raise1() if __name__ == '__main__': for _ in range(3): try: raise2() except Exception as e: traceback.print_exception(type(e), e, e.__traceback__) |
错误如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
Traceback (most recent call last): File "/Users/xintao.lai/Downloads/ex.py", line 15, in <module> raise2() File "/Users/xintao.lai/Downloads/ex.py", line 10, in raise2 raise1() File "/Users/xintao.lai/Downloads/ex.py", line 6, in raise1 raise e Exception: foobar Traceback (most recent call last): File "/Users/xintao.lai/Downloads/ex.py", line 15, in <module> raise2() File "/Users/xintao.lai/Downloads/ex.py", line 10, in raise2 raise1() File "/Users/xintao.lai/Downloads/ex.py", line 6, in raise1 raise e ^ NameError: name 'e' is not defined Traceback (most recent call last): File "/Users/xintao.lai/Downloads/ex.py", line 15, in <module> raise2() File "/Users/xintao.lai/Downloads/ex.py", line 10, in raise2 raise1() File "/Users/xintao.lai/Downloads/ex.py", line 6, in raise1 raise e ^ NameError: name 'e' is not defined |
说这个 e 没有定义,好奇怪。
然后在文档中找到了答案。
![]()
原来 except 之后是有一个 clear 动作的。
想了一下,这应该是用来解决 GC 问题的。因为 Python3 把 trackback 放到 Exception 上,实际上是创建了一个环形的引用: err -> traceback -> stack frame -> err,引用计数无法清除,必须要等垃圾回收。而这部分环形的设计的对象又比较多,比如局部变量里面有已经关闭的文件的话,在 gc 之前,可能 file handle 会耗尽。所以这里解释器相当于做引用减 1 ,破掉 stack frame -> err 这个环。(不过感觉应该有办法区分开,当前的 e 不是 local,不要 del 吧?)
谢谢分享。。。