今天的工作太刺激了,一天下来正好解决了一个有意思的问题。晚上来记录一下。
上次解决了当有很大的 HTTP body,在 ngx_lua 里面读不到的情况后,还留下一个解决性能问题。上次提到,我们对于用户的每一个请求,都要根据一个 json 形式的规则,来判断怎么样路由这个用户。为了让读者更明白这个问题,举几个例子:
- 给出一个 10万元素的用户 ID 列表,如果用户的 ID 在这里面,并且请求 URL 是 xx,Cookie 含有 xx,就转发到 Server A
- 用户 ID 在列表转发出 10% 的用户到 Server B
此模块我是用 ngx_lua 写的,现在有问题的实现是这样的,将这个规则保存在 ngx.shared_dict 里面。每一个请求过来,我就解析成 lua 的 table,然后判断规则。我的测试环境是一台内网的服务器,单进程开 Nginx,wrk 测试是 1800~1900 request/sec。开启这个模块之后,只有 88 requests/sec,由于每一个请求都要经过这个模块,这样的延迟是无法接受的。
规则是发到每台机器的 Nginx 上,要在 Nginx 所有的 work process 共享一个变量,不知道除了 shared_dict 还有啥方法。其实我想过自己基于 shared_dict 实现保存 table,就是我把 table 打扁平,按照 key-value 放到 shared_dict,但是这项工作想想就挺大的,而且要踩坑才能保证正确性。
今天发了一个邮件到 openresty 社区(这个社区非常活跃和友好!),问了这个问题。mrluanma 和 tokers 回复说可以用 mlcache 。其实我之前也看了一下这个项目,但是没有看完文档,不知道靠不靠谱,既然大家可以说这么用,就去试一试了。
这其实是一个缓存,首先 L1 缓存是每一个 Nginx 进程里面的 Lua vm 会有缓存,如果没有命中,那么第二层缓存就是 ngx.shared_dict ,如果再没有命中,就会调用用户的 callback,也就是所谓的 L3. 由于是一个缓存项目,所以有一些缓存方面的问题,比如 dog pile,此模块都处理好了。我的用法比较特殊,只是拿它来做多个 worker/多个 HTTP requests 的共享数据,所以很多地方没有细看。
新建一个 cache 的 Nginx 代码如下,需要写在 http 里面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
lua_shared_dict rule_store 10m; lua_shared_dict mlcache_ipc 10m; lua_code_cache on; init_by_lua_block { local mlcache = require "resty.mlcache" local cache, err = mlcache.new("rule_cache", "rule_store", { lru_size = 500, -- size of the L1 (Lua VM) cache ttl = 0, neg_ttl = 0, ipc_shm = "mlcache_ipc", }) if err then ngx.log(ngx.ERR, err) -- TODO warning... end -- we put our instance in the global table for brivety in -- this example, but prefer an upvalue to one of your modules -- as recommended by ngx_lua _G.cache = cache } |
这里要注意 3 个地方:
- 因为要调用
set()方法,我们是主动更新规则的,而不是等他过期。调用set()和update()要提供 worker 之间通讯的方式。mlcache 实现了通过 shared_dict 来通讯,所以我只要另外申请一个 shared_dict ,然后将这个 shared_dict 设置给ipc_shm就好了。 ttl和neg_ttl设置成 0 ,理由同上。- 通过
_G可以执行全局的变量,这样 lua 就可以直接使用cache这个名字了。
然后在设置规则的时候,直接通过 cache 来调用即可:
|
1 |
local ok, err = cache:set("rules", nil, rules) |
读取规则也是一样:
|
1 2 3 |
local rule_table, err = cache:get("rules", nil, function() return nil,nil,0 end ) |
今天栽在这里很长时间,文档说第二个参数是 optional 的,我以为就可以不填。然后 set() 就填了两个变量。结果调试半天(Lua 奇葩的变量不够 nil 来补)。后来才明白这个 optional 的意思是你可以填一个 nil 进去,因为未定义的变量就是 nil 啊!难怪呢,我还想 lua 怎么实现的,难不成判断函数调用的参数个数?
另外一个点是 get() 方法要提供一个 callback 函数,L2 没有命中的时候提供就执行这个函数。在我这里,如果 L2 是 nil,那么 L3 也返回 nil 好了。
显示调用 set() 的一个非常重要的点是:一定要通知其他 worker 删除 L1 缓存。不然我们调用 set() 只是更新了一个 worker 的 L1 和 L2。在本文的场景下,worker 的数据不一致导致转发规则不一致是有问题的。这里只要在 这里之前写的 set() 的之后调用一下 purge() 之后,通知其他 L1 去删除自己的缓存就可以了。purge() 函数的使用是有错误的,purge() 是清除缓存,包括用于 worker 交流的 shm 和 lua-resty-lrucache 的缓存,导致所有 L1 和 L2 miss 然后去 L3 更新,所以开销是比较大的(虽然在我这里,整个缓存=我的一个 table)。
正确的用法是这样的,使用 set() 的话,要多加一步,在 get() 前面调用一下 update() 。从源代码和文档得知,它的工作原理是这样的:set() 内置会广播一条消息,然后更新 L1 缓存(仅自己的 worker)和 L2 缓存。get() 之前 update() 这个调用会队列里面的广播事件,如果有事件的话,就先消费掉事件,没有事件的话,就什么也不做。注意所谓的 update 并不是更新 L2 缓存,而是消费所有的事件的意思。这样就做到一个 worker 更新某个值之后保持和其他 worker 一致了。
下图的第一个 worker 先 set 了一个值,然后通过 shared_dict 广播出去这个值的 name,回调函数是从 L1 删除这个值。其他 worker 蓝色的箭头表示 get() 之前 update() 去检查是否有事件需要处理。
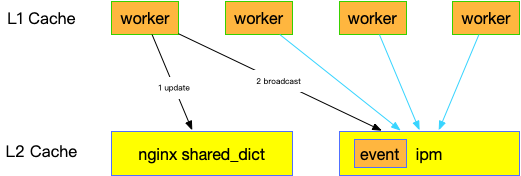
修改之后性能从 88 requests/sec 上升到 300+ requests/sec,所有提升,但还是很慢。平均下来一个请求的延迟增加 3ms 多。
然后我又顺着这 10w userid 进行优化,规则里面这个 uid 是一个很大的 List,所以逻辑上是遍历查找一个用户是不是在列表里面的,O(n) 的效率。主要的耗时点就在这里。我想改成用 Set 结构来存,这样只要 O(1) 复杂度就够了。
问题是,Json 只有 Dict 和 List 两种数据结构,这个回答说的很好:
- 编程实现 List 和 Set 互相转换是很简单的
- Json 用于数据交换,你不能信任一个数据输入是 Uniq 的
但是我觉得 Json 增加 {"foo", "bar", "banana"} 这种形式好像没有什么不妥。
Anyway,我只能自己实现了,写了一个函数,在 Json 转换成 table 之后,找到我想转换的 Key,将它的 value 从 array 形式的 table(key 是 1 2 3 4 5 …)改成 Set 形式的 table (key 是各个元素,value 为 true),代码如下:
|
1 2 3 4 5 |
local expected_table = {} for _, item in ipairs(expected['list']) do expected_table[item] = true end expected['list'] = expected_table |
这样,在找的时候,只要看 value 是不是 true 就可以了:
|
1 |
local in_list = expected['list'] ~= nil |
这样改了之后,性能上升到 1800 requests/sec,跟不开启这个模块相比,基本上没有性能损耗了。
话说回来,这个问题跟我上一家公司的面试我的时候出的题目很像:给你一个 IP 列表,内存可以随便用,但是查找速度要快,如何看一个 IP 是否在表中?
我当时的方法是,一个 IP 用一个 bit ,bit 位要么是 0 要么是 1,表示此 IP 在或不在。表示世界上所有的 IP(IPv4)需要 2^32 个bit = 536M,将 IP 列表中的 bit 都置为 1,其余为0. 这里的关键是 IP 如何映射成 bit 表,IP 其实是 4 个字节而已,直接用 4 个字节所表示的数字作为 index 就好了。
巧合的是,这个周我正好认识了布隆过滤器。哈,我的想法真先进。
话说回来,这个问题跟我上一家公司的面试我的时候出的题目很像:给你一个 IP 列表,内存可以随便用,但是查找速度要快,如何看一个 IP 是否在表中?
===========
内存随便直接上hash表了,bf是为了省内存造出来的。
是的,原理应该是一样的。我觉得 bloom filter 就像是一个定制了 hash 方法的 hash 表。bloom filter 是将 ip 转换成一个 int 数,查找这个位置是 0/1,而通用的 hash 方法是按照别的方法转换成这个 int 数(index),可能要面临效率的问题,hash 碰撞的问题,以及使用更多内存的问题。