博客好久没更新了,最近非常忙。到德国交换落下的课必须这学期补,还有论文要写,加上实习,(其实还有每天忍不住玩守望先锋的时间)基本上时间就塞满了。最近实习的主要内容是写爬虫,工作有点无聊,技术上没有啥挑战,但是要处理很多边界值这种情况。也见识了很多让人哭笑不得的网站。
爬的目标很多是政府网站。在我的印象中,政府网站和大学官网是奇葩一般的存在,对了,国有公司的官网也算是吧。这种网站访问量不少,但是用户体验非常糟糕,看了页面的源代码,你都不知道这种网站是怎么写出来的,怎么维护(所以一般不维护吧……)。
比如说,某网站的css全部写在页面内,,<p>标签中穿插着各种<span> <font>,整个页面没有使用一个css class!这个页面的开发维护人员,一定惊为天人!于是这个页面的爬虫,只好写成了这样子……

还有一个神奇的网站,爬虫写好的时候,发现抓不到数据。打开网页一看,数据没了!网页是能打开的,但是没有数据!留下我一脸懵逼不知所措,回家睡了一觉之后发现,又能打开了!于是我发现了规律,上午9点到下午5点是能打开的,就在调度上让这个爬虫在每天的11点运行,并注释:此网站朝九晚五,估计是运行在工作人员自己的电脑上。
又想起来一个,一个公布著作权的网站,列表页打开特别慢,但是详情页能秒开。页数显示,这个网站的列表页有五百多万页,于是我想,这个网站的页数大概是把所有的数据取出来计算一下数量,才会这么慢吧……
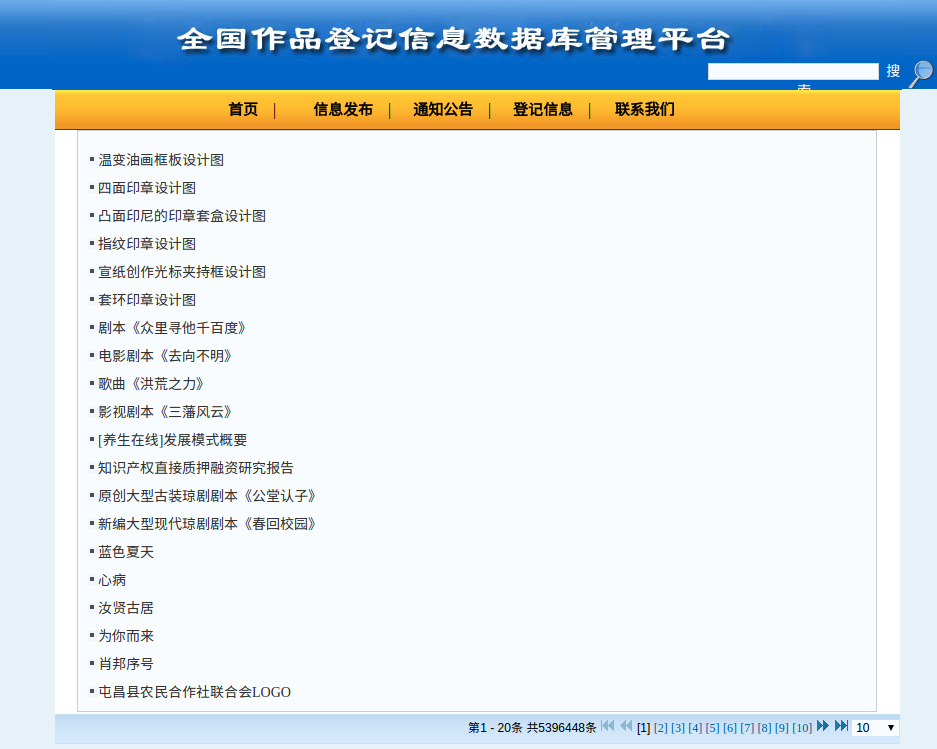
抓某个网站的时候,发现数据太多,但是列表页只显示前100条数据。于是按天来抓,竟然也超过了100页。仔细观察了列表页,发现url是长这个样子的:
|
1 |
http://www.xxxxx.com/tradingIndex.view?key=&pubDateBegin=2016-06-01&pubDateEnd=2016-06-01&infoType=&fundSourceCodes=&zone=&normIndustry=&bidModel=&timeType=custom&sortMethod=¤tPage=45&length=10 |
最后竟然有个length参数,将10改成300,原本每页只显示10条记录,现在变成每页显示300条了……好吧,爽啊……
我有点好奇,既然可以改成300,那么直接用一页就爬回来所有的数据呢?于是将length改成了13000000(数据总量),结果一段时间之后,网站返回504,然后……挂掉了……这可能是我见过最容易DOS的网站了,只要一条命令就能宕机。
大量的政府网站竟然……没有备案!比如说这个:http://119.6.84.165:8085/sfgk/webapp/area/cdsfgk/splc/ktgg.jsp …………这应该算是打脸了吧……
除此之外,这些网站的URL混乱不堪,页面结构杂乱无章,安全方面更不必说了,使用HTTPS的一个都没有,却基本上都会有被时代抛弃的flash。这都是政府的网站,稍微拨点款找个靠谱一点的外包公司,也不至于这样啊。
本来该付给外包的钱都被“收入囊中”了,最后可能只是找了个非常业余的中学计算机老师做了这种项目。
大学也基本上是这样,我室友就接过一些我校的校内网站项目(虽然不业余但是成本很低)……
捕获一只Spartan。
错了,最后可能只是找的学生做的,还一分钱不用
朝九晚五那个笑死我了哈哈
哈哈我也笑了好久。
我们学校经常会有“几点到几点登录教务处填写XXX”这样的通告,估计贪图省事都是直接在服务器开启一个进程监听端口,而没有部署吧Orz
Pingback: 爬虫工程师是干什么的? – 林清猫耳
Pingback: Spiderman的必备技能 – HCHL
Pingback: 爬虫工程师是干什么的 - 算法网