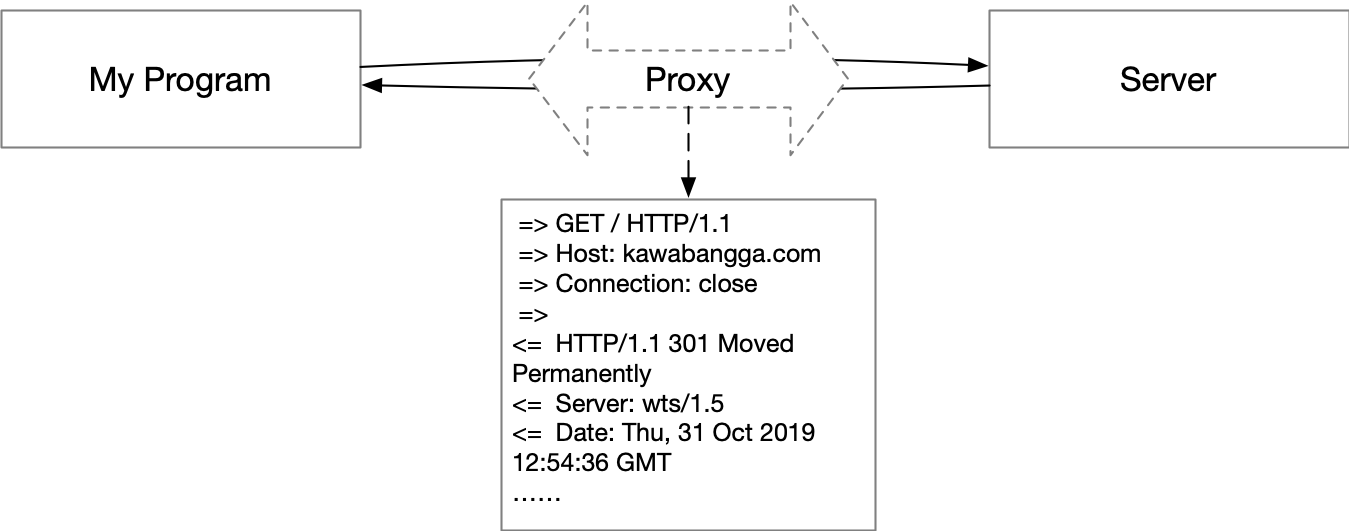
Linux 系统的 $PATH 变量通常会包含 /bin /usr/bin /usr/local/bin 。这三个目录下都有一些 binary 程序,至于有什么区别,网上有很多错误的解释。(就像介绍 HTTP GET 和 POST 有什么区别这个问题一样)。本文试图说明这个问题,基于我的理解和 Linux 文档。(本文里说的 Linux,更准确的说,应该是 Unix系系统)
TL;DR
这些 bin 的位置,仅仅是几个目录而已,并没有本质的区别。哪些命令放在哪里,完全看用户和发行版的喜好。比如,有一些发行版将 /bin 作为 -> /usr/bin 的符号链接。[命令,Ubuntu 放在 /usr/bin 下,OS X 就放在了 /bin 下。
但是通常来说,我们都认为这几个目录这样安排:
/bin放置系统的关键程序,比如lscat,对于“关键”的定义,不同的发行版会有不同的理解;/usr/bin放置发行版管理的程序,比如 Ubuntu 自带md5sum,这个 binary 就会在这个目录下;/usr/local/bin放置用户自己的程序,比如你编译了一个 gcc,那么 gcc 这个可执行 binary 应该在这个目录下;- 除此之外,还有对应的三个目录
/sbin/usr/sbin/usr/local/sbin,放置系统管理的程序,比如deluserchrootservice;
需要再次强调,这是一种文件的管理方式而已,你甚至可以把自己的 binary 放到 $HOME/bin 下。还有,OS X 用 homebrew 安装的软件,会放在 `/usr/local/Cellar` 下,然后在 /usr/local/bin 创建一个指向相关 bin 目录的符号链接;但是在 Ubuntu 下,会放到 /usr/bin 下。
更深的理解
(这一段来自知乎的 in nek)另外,需要知道 / /usr /usr/local 这些都是 prefix,你编译一个软件的之后,要执行 ./configure --prefix=/usr/local 然后 make && make install 。那么 /usr/local 就会作为 prefix,库文件就放在 /usr/local/lib 下面,配置文件就放在 /usr/local/etc 下面,可执行文件(binary)就放在 /usr/local/bin 下面。
然后我们看看这些prefix是怎么选择的。如果你编译过FreeBSD一类的系统,你会发现,这些系统的系统库,基础工具和内核是放到一套代码树中的,编译这个代码,内核和核心库,工具是一同完成的,这些都被认为是操作系统的一部分。这些核心文件,就以根目录作为prefix。所以,/是所有操作系统核心程序的prefix。
在这个核心之外增加新的程序,构成一个发行版,这个发行版增加的程序就用/usr作为prefix。
你把发行版安装好了,安装发行版之外应用程序,那些程序通常用/opt, /srv作为prefix。
但如果你自己从源代码开始编译一个应用程序,这些程序是专门向你这个Site编译的,这种情况下,默认的prefix是/usr/local。
一些历史…
可以看到,不同的发行版会有不同的理解。所以就有 Filesystem Hierarchy Standard 想要指定一个文件等级的标准。(其实我认为这个标准没有太大意义,这种规范不能强迫所有的发行版去理解。与其去理解这个,不如去理解你的发行版是怎么思考的,适用和学习你称手的发行版)。
即使现在大多数人认为这三个目录的含义就像本文开头讲的那样,但事实是,这三个目录创建的时候的目的不是这样的。
事实是,Ken Thompson 和 Dennis Ritchie 在 1969 年创建 Unix 的时候,用的是 PDP-11,磁盘是两块 RK05,每块只有 1.5M。
后来系统变得越来越大了,一块磁盘不够用了,需要用到第二块磁盘,于是就 mount 了第二块,叫做 /usr 用来放用户的文件(想象一下,有两块磁盘,一块放系统,一块放用户数据,非常合理)。然后把系统的目录,/bin /sbin lib … 都复制到新磁盘下,在新磁盘读写。
后来他们有了第三块磁盘(啊!!),mount 在了 /home 下,只把用户的文件移动了过去。这样通过不同的磁盘挂载到不同的地方,系统可以利用起3块磁盘了。
当然,他们必须有个规则:“当系统第一次启动的时候,第一块磁盘里面必须有所有需要的程序,来挂在第二块磁盘到 /usr,比如 mount 。如果 mount 放在 /usr/bin/mount 这里,就会遇上先有鸡还是先有蛋的问题。” 非常合理。
/bin 和 /usr/bin 的分裂是人为的,1970 年的这个实现细节一直延续了下来。要怪就怪那些墨守成规,不问为什么的人。
可以说这个分裂是“没有必要的”,如果磁盘空间足够的话。但是后来由于种种原因,这个“没有必要”的假设就被打破了。其中一个原因是,后来引入了共享库(动态链接),/lib 和 /usr/bin 必须 match。之前没有这个问题,因为所有的东西都是静态链接的。
Anyway,自从有了这两个目录,人们便开始赋予它们含义:/ 用来存放上游的文件,/usr 放本地的内容;后来演变成 / 放从 AT&T 官方发行的内容,/usr 放发行版的内容,那时是 IBM AIX 或 Dec Ultrix,/usr/local 放自己本地的内容;再后来人们觉得 /usr/local 放安装的新 package 不够好,那再加一个 /opt ! 将来说不定还有 /opt/local。
后来有一些组织尝试将它们标准化,比如我们前面提到的 Filesystem Hierarchy Standard ,但是他们并没有尝试去理解一开始为什么会这样……
参考资料: