本文介绍 HTTP 长连接的协议、历史,TCP 长连接,和一些客户端、服务器实现。
Disclaimer: 本文所引用的资料都会给出链接,如有疑问应该去原资料验证,如果存在错误请不吝指出。
HTTP/1.0 会为每一个 HTTP 请求都建立 TCP 连接,这样显然是很低效的,所以就有人想在同一个 TCP 连接上发送多个 HTTP 请求,这样就省掉后面 TCP 连接建立的三次握手了。这就是“长连接”,英文里面也有其他的名字:HTTP Persistent Connection,HTTP Keep-Alive,或 HTTP Connection Reuse。
可以用 nc 来测试一下,这里我用 nc 连接到 httpbin.org 的服务器,然后用 tcpdump 抓包看其中的 TCP 连接情况。
用 nc 打开连接后,输入和输出如下。其中高亮的部分是我的输入,其余是服务器的输出:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
➜ tmp nc -c 52.0.94.50 80 GET /ip HTTP/1.1 Host: httpbin.org HTTP/1.1 200 OK Connection: keep-alive Server: gunicorn/19.9.0 Date: Sat, 08 Dec 2018 05:58:39 GMT Content-Type: application/json Content-Length: 33 Access-Control-Allow-Origin: * Access-Control-Allow-Credentials: true Via: 1.1 vegur { "origin": "122.235.200.20" } GET /ip HTTP/1.1 Host: httpbin.org HTTP/1.1 200 OK Connection: keep-alive Server: gunicorn/19.9.0 Date: Sat, 08 Dec 2018 05:58:41 GMT Content-Type: application/json Content-Length: 33 Access-Control-Allow-Origin: * Access-Control-Allow-Credentials: true Via: 1.1 vegur { "origin": "122.235.200.20" } ^C |
可以看到我连续发送了两次 HTTP 请求,nc 都没有结束,并且还在等到我的输入,输入 ^c 之后才关闭,断开了连接。
抓包如下:
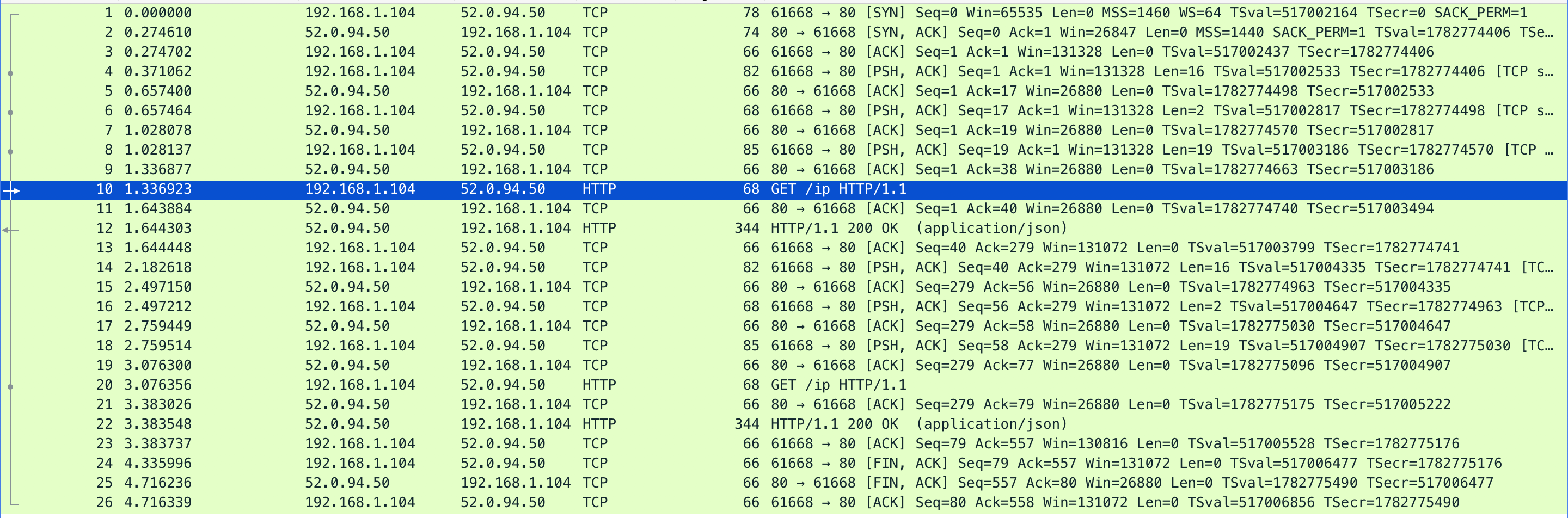
可以看到两次 HTTP 请求始终在同一个 TCP 连接上,只不过中间有很多保持心跳的 TCP 包。
HTTP/1.0 到 HTTP/1.1
在 HTTP/1.0 中,有人就尝试实现这样的长连接。实现的方式是客户端和服务器协商 Connection: Keep-Alive Header。加入浏览器支持长连接,那么就在 HTTP 请求的 Header 上添加 Connection: Keep-Alive ,如果服务器收到请求,就在 Response 中也加入这个 Header: Connection: Keep-Alive 。这样客户端再发送另一个请求的时候就会使用这个 TCP 连接,而不会新建一个。
然而,HTTP/1.0 的实现是错误的,主要的问题在代理。HTTP/1.0 的 Proxy Server 不懂这个字段,把它原样发给了后面的 Server,导致 Proxy 和 Server 之间建立了长连接,造成了一个 “Hung Connection”。有人提出一种处理的手段(RFC 7230 A.1.2),是想换一个字段来表示 Client 和 Proxy Server 之间的长连接 Proxy-Connection ,但是通常代理并不仅仅是一层,而是层层 HTTP 代理,这样依然就存在前面的问题,所以 Proxy-Connection 这个 Header 在任何情况下都用不到。
所以在 HTTP/1.0 使用长连接要小心,客户端要感知 hung 住的连接,要显示地关闭。因为 HTTP/1.0 的 Proxy 不支持长连接,所以在有 HTTP/1.0 Proxy 的情况下,不能使用长连接。
然而,和 Proxy Server 的对话是长连接一个重要的使用场景,所以粗暴地规定不能对 Proxy 使用长连接是不能接受的。所以就需要一种新的机制,要满足以下的需求:1)对于旧版本的 Proxy Server ,忽略了长连接请求不会造成 Hung Connnection. 2)新版本的机制能够让 Real Server 和 Proxy Server 都能正确处理长连接。
HTTP/1.1 提出的方案(RFC2068 19.7.1)是:所有的 HTTP 连接默认都是长连接。当 Header 中添加 Connection: close 的时候,表示不保持长连接。这样可以满足上面说的需求,兼容旧版本的 Proxy Server(不会携带表示长连接的 Header)。
HTTP/1.1 的 Server 也可以跟 HTTP/1.0 的 Client 建立长连接,如果 Client 显式地携带了 Keep-Alive 的话。但是 HTTP/1.0 的客户端不支持 Chunked transfer-coding,所以必须每条信息都带上 Content-Length 表示边界。
另外除了 Connection 这个 Header,还有一个可选的 Header Keep-Alive 可以控制一些有关长连接的参数:
|
1 2 3 |
Keep-Alive-header = "Keep-Alive" ":" 0# keepalive-param keepalive-param = param-name "=" value |
这个字段是可选的,只有带有参数的时候才生效。显而易见,这个 Header 必须和 Connection: Keep-Alive 一起发,毕竟它是控制长连接的,在没有长连接的情况下,这个 Header 就毫无意义。
最重要的一点,通过上面的描述你可能已经意识到了,就是 Connection: Keep-Alive 和下面要将的 Keep-Alive 这两个 Header 都是 hop-by-hop 的,就是说只对通讯的二者起作用,加入第二个人是 Proxy,那么 Proxy 和 Real Server 之间的连接是怎样的,就需要它们二者再自己商量了。
HTTP Keep-Alive Header
Hypertext Transfer Protocol (HTTP) Keep-Alive Header 这个 RFC 定义了 Keep-Alive Header 的一种形式。
为什么需要这些参数呢?
为了节省资源,Host 会选择关闭 idle 的长连接。比如一个连接很长时间没有使用,Host 会选择关闭它(显而易见)。
基于这个原因,很多客户端发送非幂等的请求的时候,会选择不复用现有的 idle 连接。理由如下,假设现在有一个非幂等请求进来,而恰好 Server 认为这个连接空闲了很长时间了,决定要关闭此连接。那么客户端收不到 HTTP 响应(也可能收不到 TCP 的 ACK),客户端就不知道这个非幂等请求到底被处理了没有。可能 Server 收到了这个请求之后又关闭的,也可能请求到达之前 Server 就关闭连接了。
所以很多客户端选择对所有非幂等请求都建立新的连接。但是每次都建立 TCP 连接,是很浪费资源的,也增加了请求的延迟。
假如 Client 知道 Server 的 timeout,客户端就可以在快要 timeout 的时候选择不使用这个已有的连接,或者发送请求来保证不超过 timeout。另外,如果客户端知道 timeout,那么在没有后续请求发送,而 timeout 时间又比较长的时候,客户端可以显示地要求 Server 关闭连接,释放资源。
Keep-Alive Header 的形式定义如下:
|
1 2 3 4 5 |
Keep-Alive = "Keep-Alive" ":" 1#keep-alive-info keep-alive-info = "timeout" "=" delta-seconds / "max" "=" 1*DIGIT / keep-alive-extension keep-alive-extension = token [ "=" ( token / quoted-string ) ] |
‘timeout’ 参数
timeout 参数代表当一个连接至少 idle 多长时间才会被关闭。它的 value 是一个代表秒数的 int 值。通常,连接上没有数据传输就被认为是 idle 的。但是不同的客户端和服务器实现对 idle 的理解不同,还受网络延迟的影响。所以建议客户端评估 idle 的时候算上网络延迟。
‘max’ 参数
max 参数表示在一个连接上客户端可以发送请求数的最大值。客户端在一个连接上请求的次数到了这个值,Server 就会关闭这个连接。
max 的 value 是一个 int 值,表示请求数。
对于客户端来说,收到了带有这个参数的 Response,就可以限制在同一个连接中发送的请求。举例说,假如客户端用一个队列来存放即将发送的请求,那么根据 max 就可以对队列分段。对于服务器来说,当服务器接收的请求达到了计数值之后就可以关闭连接。
Keep-Alive Extensions
除了这两个参数之外,也可以在 keep-alive-extension 字段中添加自定义的字段,如果服务器不理解这些字段,将忽略。
存在中间人的情况
在本文开头已经看到,HTTP 的长连接是基于 TCP 的长连接的。所以情况要复杂的多,实际情况有可能 TCP 保持长连接的时间要比 HTTP 短,HTTP 长连接 timeout 还没达到的时候,像 Net Address Translation (NAT) 这样的设备就将此 TCP 连接断开了,导致此连接不再可用。
HTTP/1.1 的中间人在转发请求的时候会直接丢掉这个 Header,因为它不需要认识这个 Header,它可以在任何时候断开连接。
HTTP/1.0 的中间人,我们前面说过了,会导致错误。
此外,如果客户端(或中间人)感知到后面中间人的中间人(或中间 TCP 转发设备)的 timeout 更短的话,可能会修改这个值。Again,这个 Header 是 hop-by-hop 的。
从以下这个例子可以看出,每一端的连接都是独立协商的。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
Client Proxy Server | | | +- Keep-Alive: timeout=600 -->| | | Connection: Keep-Alive | | | +- Keep-Alive: timeout=1200 -->| | | Connection: Keep-Alive | | | | | |<-- Keep-Alive: timeout=300 --+ | | Connection: Keep-Alive | |<- Keep-Alive: timeout=120 -+ | | Connection: Keep-Alive | | | | | |
这里 Client 想要建立一个 timeout 为 10 分钟的长连接,但是 Proxy Server 只支持 120 秒,所以 Client 和 Proxy 之间的长连接最终是 120 秒的 timeout。Proxy 想和 Real Server 建立 1200 timeout 的长连接,但是 Real Server 将其降低到 300s。(PS:上图中 120 这个数字在 RFC 中写的是 5000,这样的话跟 RFC 的解释就冲突了,我不是很理解,我觉得 RFC 这里这个数字可能写错了。如果我理解错了,请指出)
如果 Upgraded HTTP Connections 的情况,就更复杂一些。如果 upgraded 的协议没有指明 timeout,那么会继承长连接初始化时候的 timeout,max 这个参数没有意义,因为升级后的 request 和 subrequest 被视为一个 HTTP 请求。客户端、中间人、服务器对 Upgraded 的策略可能不同,但是这个长连接的各个参数不再像上面一样可以分别独立协商,而是从 Client 到 Proxy 到 Real Server 的连接属性是一样的。
由于 keepalive 这个词被用在很多地方,而意义不尽相同,下面介绍一下 TCP 的 keepalive。
TCP Keepalive
对于 TCP 来说,Keepalive 并不是标准 TCP 协议规定的,所以 TCP 本身并不知道这个东西的存在,这只是在 TCP 之上的一个实现。
简单说,TCP Keepalive 就是设置一个 timer,时间一到就发送一个 probe packet,并设置 ACK。如果对方发送回来一个 ACK,那么那就知道这个 TCP 连接依然是可用的。如果对方没有发送 ACK 回来,那么就知道这个连接已经被断开了(实际的实现,一般会在收不到请求 ACK 的情况下重复发送多次 probe packet)。可以这么做是因为 1) TCP 是面向流的连接,而不是面向包的,所以在这个“流”中插入一个长度为 0 的包不会对这个流的内容造成任何影响。2)TCP 对每一个 packet 都会发送一个 ACK 确认。所以就可以用长度为 0 的一段“stream”来当做 probe。
那这个 TCP 的 Keepalive 有什么用呢?
主要有两个,第一是检查连接是否可用。假设 TCP 的另一端断电了,或者中间的某一个转发的设备断电了,那么通过检查连接的可用性,就可以确保不会在一个已经不能用的连接上发消息,不会有 false-positive。
第二是可以起到类似心跳的作用,防火墙或 NAT 设备的内存只能保存有限的连接数,它们普遍采用的策略是保留最近用到的连接,丢弃最旧没有有消息的连接。通过 Keepalive 的机制,我们可以让 NAT 设备保持我们的连接在可用列表中。
对比一下:HTTP 的 Keep-Alive Header 做的是设置长连接的 idle 时间,超过了这个时间就关闭连接,TCP Keepalive 设置的 timer 到了就发送空的 probe packet。
最后再提一个 Nginx 里面的 keepalive 指令,这个指令就更加迷惑了,跟上面介绍的都不搭边。它表示的是:Nginx 与 upstream 之间保持最多多少个 idle 的长连接。这个 idle 很关键,比如 keepalive 100 ,那么收到 300 个请求的时候,Nginx 和 upstream 建立 300 个长连接,这 300 个请求结束后,又来了 50 个请求,那么只有 50 个长连接是工作的,idle 的连接就有 250 个,Nginx 会关闭 150 个。更具体的例子可以看这里。
参考资料:
- https://tools.ietf.org/id/draft-thomson-hybi-http-timeout-01.html
- https://tools.ietf.org/html/rfc7230#section-6.1
- TCP Keepalive Howto
- 为什么基于TCP的应用需要心跳包(TCP keep-alive原理分析)
- Nginx 长连接
说到长连接,好像想到了轮询。。。
Pingback: 请求为什么超时了? | 卡瓦邦噶!