我们遇到的 Harbor 的另外一个问题是 image 的下载瓶颈。在容灾的时候,我们需要在短时间内启动几万个容器。Harbor 这里就成了瓶颈,抛开所有的数据库和文件系统的瓶颈不说,网络这里就需要 Tib 级别的带宽。这是不现实的。
用户构建的 image 质量参差不齐,大于 10GiB 的 image 比比皆是,尽管这些 image 都有很大的优化空间,但是期望所有的用户都按照构建 image 的最佳实践1进行优化,也是不现实的。
于是问题就成了:如何才能够大量的 worker 节点迅速扩容上万的容器?
此外,在平时,遇到工作日多个系统发布的时候,或者整点的时候运行定时任务(定时任务每次都会下载 image),harbor 的压力也非常大,经常满载运行。如果能解决这个问题,平时的负载问题也可以缓解。
之前介绍过 Spegel 的下载方案2,Spegel 的想法很好,基本思想是,先去其他已经存在这个 image 的机器上去下载,如果找不到,再 fallback 到 Harbor 下载。可惜的是,Spegel 把 P2P 下载和 P2P 服务发现混为一谈了,导致服务发现的性能极低。
什么意思呢?去其他的机器上下载 image,需要的一个信息是:哪一个机器有这个 image?这就是下载源的服务发现。这个服务发现和 P2P 本质上没有什么关系,用什么都可以。P2P 技术解决的是下载上的瓶颈,只有能有一个方法记录每一个机器上现在都有什么 image 就可以,用 Etcd 也可以,不一定也得用 P2P 形式的。
但是 Spegel 这里是用 P2P (libp2p)做的服务发现。在我看来这是完全没有必要的。我们在实际的部署中遇到的问题有:
- 服务发现的 latency 高,现在的配置是 30s,还是会有超时,P2P 本质上是在一个不稳定的分布式网络中寻找一个资源,效率不高;
- 成功率低,在 P2P 网络里面,能否发现一个 key 是概率性问题,不是确定的3;
- 删除 image 不会分发到 p2p 网络中,必须有访问事件得到 404 然后触发清除,这是 libp2p 本身的设计决定的,这又会导致服务发现的错误率高;
在实际的部署中,Spegel 的缓存命中率在 25% 左右。
当然,使用 P2P 做服务发现也是有好处的,好处就是部署简单,不需要额外的存储依赖。只不过这个好处和它带来的问题相比就微不足道了。
我觉得如果解决服务发现的问题,使用 P2P 下载的方法,是可以解决资源的瓶颈问题的。
所以设计的方案是:使用中心化的,高性能的服务发现,去中心化的 P2P image 下载。
原本 Spegel 的代码,服务发现层是独立的模块,所以我从 fork 它的代码来添加一个新的服务发现方式开始。但是随着修改,发现问题越来越多,比如 subscribe containerd events 的时候没有正确 defer 关闭,没处理好 containerd 重启的情况,等等,最后开始了一个独立的仓库,叫 Piccolo。代码4依然是开源的,但是还没时间写文档和注释,这篇博客先写一下原理。
项目主要分两部分:
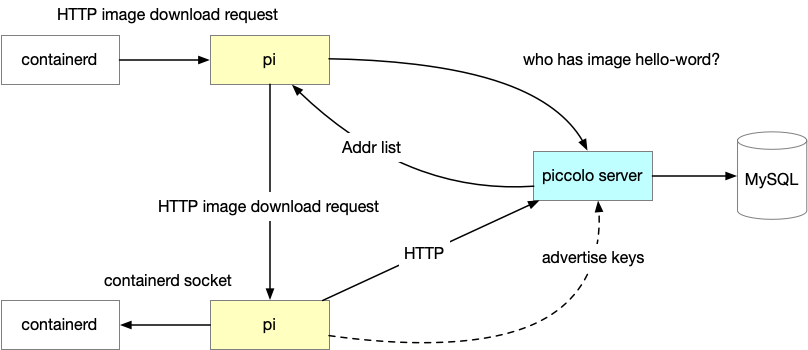
Pi – 安装在每台机器上的 daemonset,负责:
- 作为 containerd 的本地 mirror,当 containerd 需要下载 image 的时候,会先尝试本地的 Pi 端口,如果得到 404 (或者 5xx),再尝试下一个下载 mirror,一般是 dragonfly,最后是 harbor source;
- 连接本地的 containerd,跟踪本地的 image 状态,本地的 image 增加或者减少,报告给 Piccolo server;
- 连接本地的 containerd,其他的 Pi 发送来下载 image 请求的时候,上传本地有的 image。
Piccolo Server 是服务发现的源,全局只有一组(几个实例就够用了),提供 3 个接口:
- Advertise:其他 Pi 上报的 image 列表,存储到 MySQL;
- Findkey:Pi 来询问一个 image(实际上是 image 的 manifest 和 blob)在哪里有的时候,回复地址列表;
- Sync:其他 Pi 可以用这个接口做全量同步(定时,以保证 image 总是最终一致的);
部署之后,97% 的下载请求可以在 Pi 完成而不必请求 Harbor。
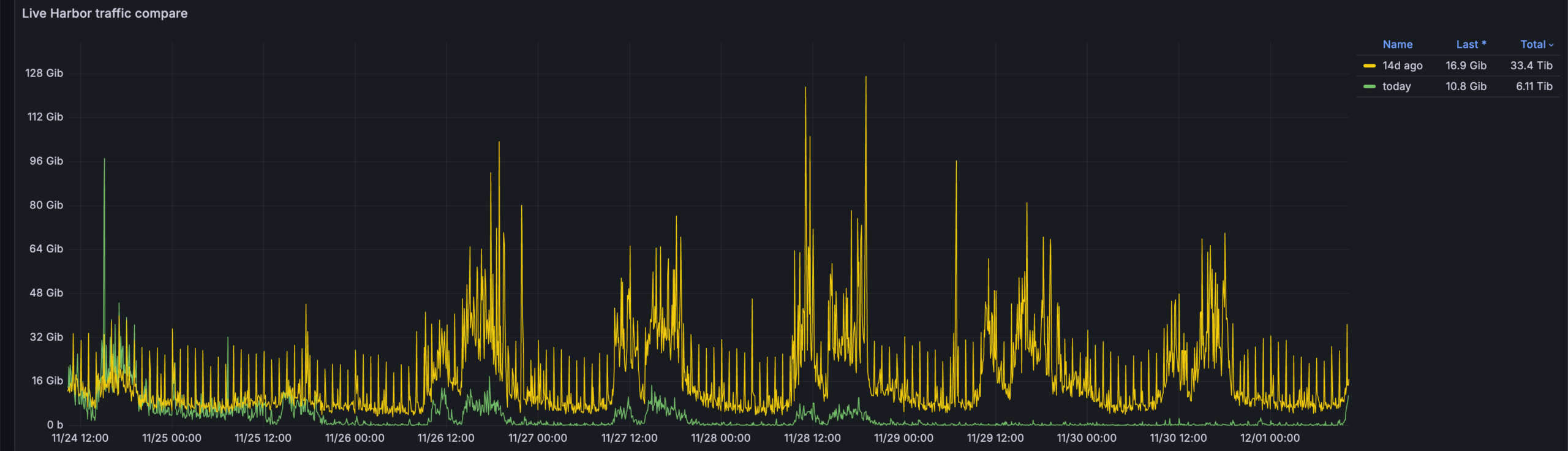
从这个监控可以看出,随着 Piccolo 的发布,Harbor 的流量骤降。而且每个小时的峰值流量也几乎没有了。
Pi 部署在每一个机器上,使用的资源也非常少,平均 CPU 用了一个 core 的不到 1%,可以忽略不计。平均内存用了 22M 左右,也可以忽略不计。
Piccolo 为集群提供了大约 8Tib 的下载带宽,没有消耗额外的资源,几乎是免费的 8Tib 带宽。
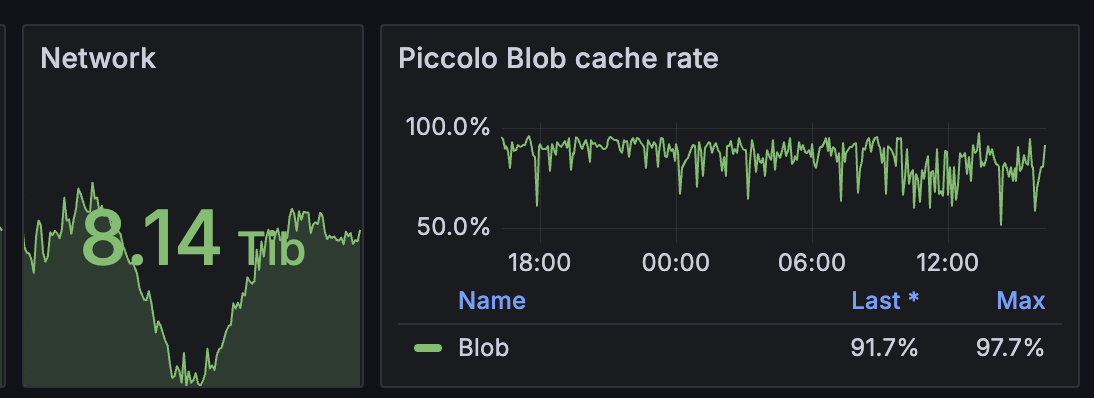
Piccolo server 方面,性能也很高,一台 8C8G 的 instance 足以支撑 5 万个 Pi (实际的物理机 worker 节点)。秘诀就是注重细节的性能优化。
比如全量同步的资源消耗较大,一起部署的机器会定时发送 keeplive,通过对这些定时执行的 API 加随机偏移,可以保持这些 API 的频率几乎是均匀的,解决了资源的峰值问题。
服务发现的核心,是用一张 MySQL 表,存储了 blob 和 IP 的对应关系。服务发现请求主要是通过这张表的查询完成的。Piccolo 支持把不同的 group(同一个 group 的 Pi 可以互相发现,不同的 group 的 Pi 不可以互相发现。其实这个功能也可以通过部署多个 Piccolo Server 来实现)放到不同的数据库中,加上索引优化(极致的索引优化,所有的查询都是 index-only 的),每一个库 2千万的数据,请求在 200 QPS,耗时在 10ms 以内,已经足够使用了。
Piccolo server 在服务发现接口返回的时候,会根据请求者的 IP 地址,把所有的资源拥有者的 IP,根据和请求者的 IP 相似度(距离)排序,返回。这样 Pi 在下载的时候,会从距离和它最近的邻居开始尝试,这样可以最大程度减少跨网络设备的带宽流量。
所有的 API 接口都有重试和指数时间退让,这样在大规模部署的时候,可以分散一些请求,不至于大家一起失败。
在高可用方面,由于 Piccolo server 是无状态的,所以部署多个实例即可。在预防未知的 bug 上,系统的每一个阶段都是可以降级的:
- 如果 containerd 从 Pi 下载失败,会 fallback 到下一个下载源;
- 如果 Pi 从一个 Pi 下载失败,会继续尝试下一个 Pi,直到超时;
- 如果 Pi 访问 Piccolo 失败,会等待并重试,直到超时;
- 这里是之前 blog 过的一些技巧 Docker 镜像构建的一些技巧 ↩︎
- Spegel 镜像分发介绍,也讨论了一些其他的可能方案,比如 dragonfly,或者 lazy loading ↩︎
- https://en.wikipedia.org/wiki/Kademlia ↩︎
- Github 地址:https://github.com/laixintao/piccolo ↩︎