答案是 MTU 设置错误1,链路可以发送的最大 MTU 小于 1500 bytes,但是客户端侧配置的 MTU 却是 1500 bytes。所以 TCP 连接建立之后的包,无法到达另一端。在等待 3.5s 左右,发送端觉得链路存在问题,尝试降低发出的包的大小,这时候就可以发过去了,链路上才开始数据传输。
要定位这个问题,我们现在抓包文件中,找到传输数据最多的那个 TCP flow,就是传输数据最多的那个。这个连接是我们重点研究的对象。右键选择 Follow > TCP Stream,来只展示这一个会话。(如何追踪某一个 TCP 流,在前面 重新认识 TCP 的握手和挥手2 中也介绍过)。
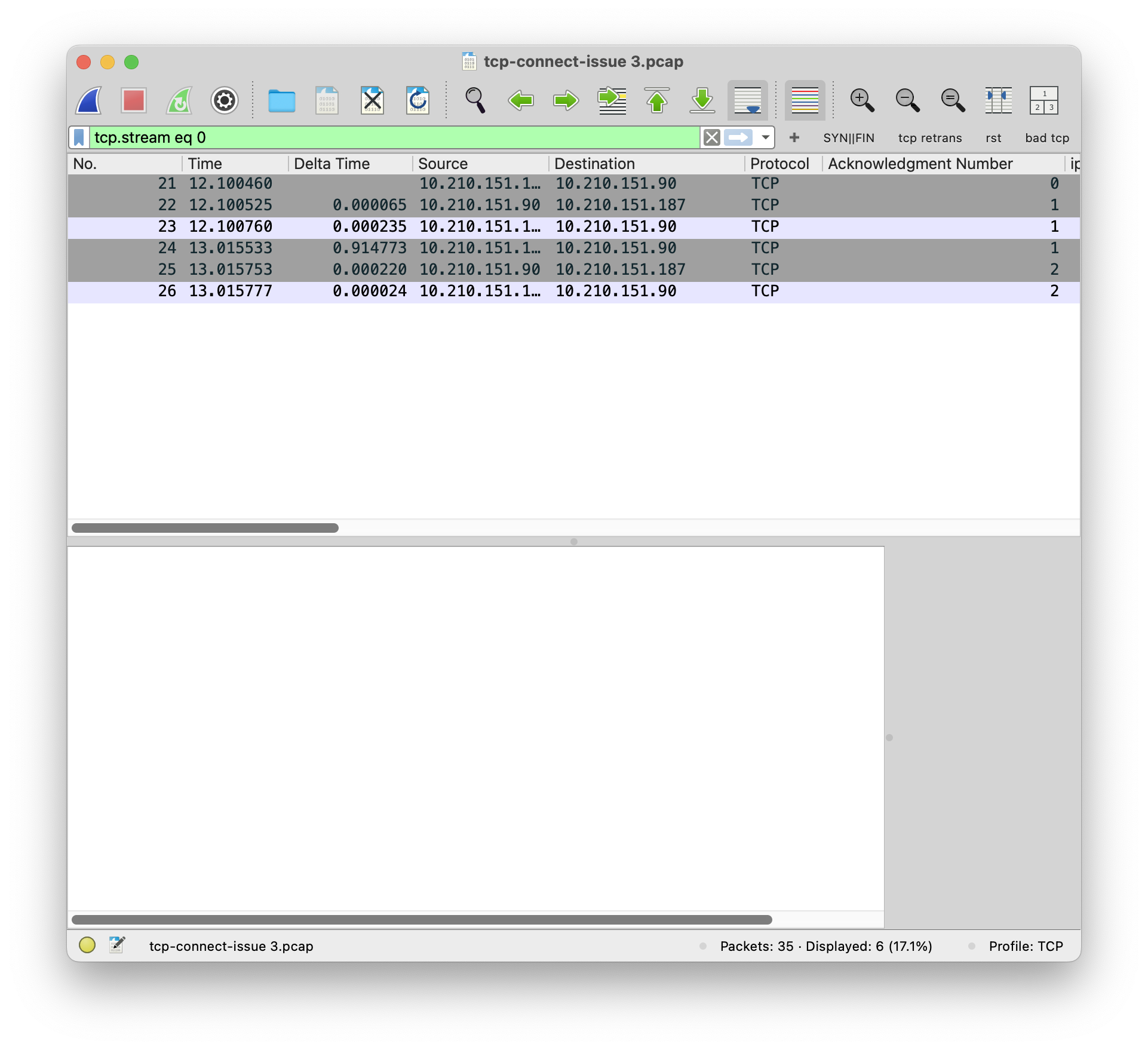
TCP connection 建立之后,客户端一下发了 10 个包,大小都为 1500 bytes。但是服务端一个都没有 ACK。
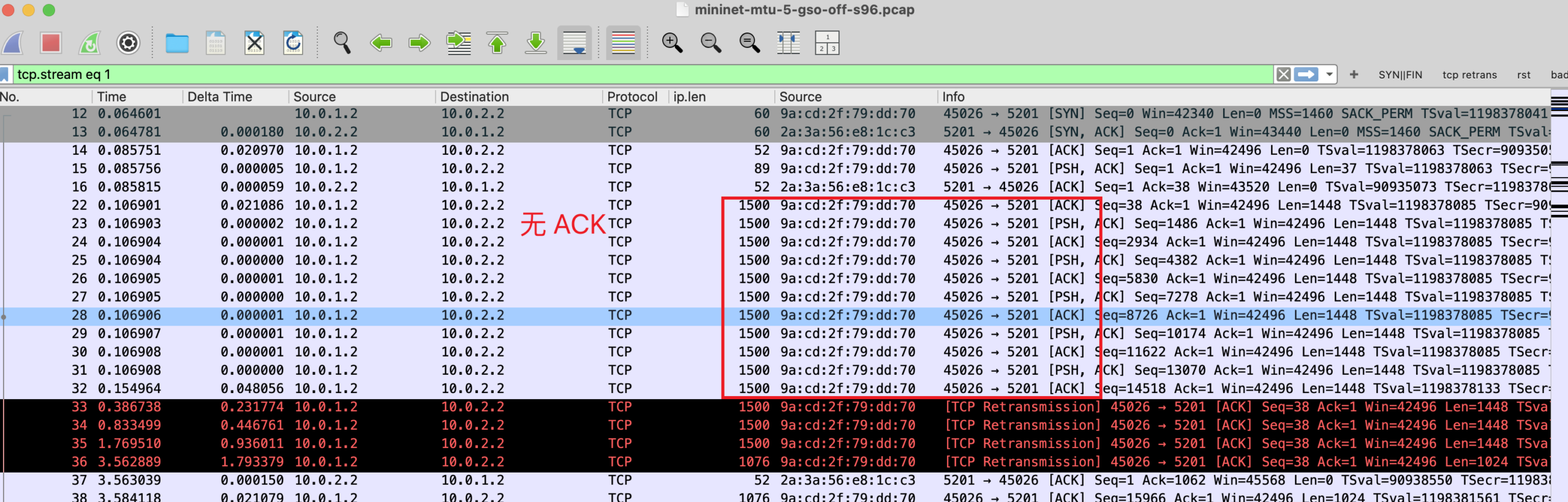
然后客户端开始重传。
前 3 次重传分别发生在 0.3s, 0.8s, 1.7s,也都没有收到 ACK。
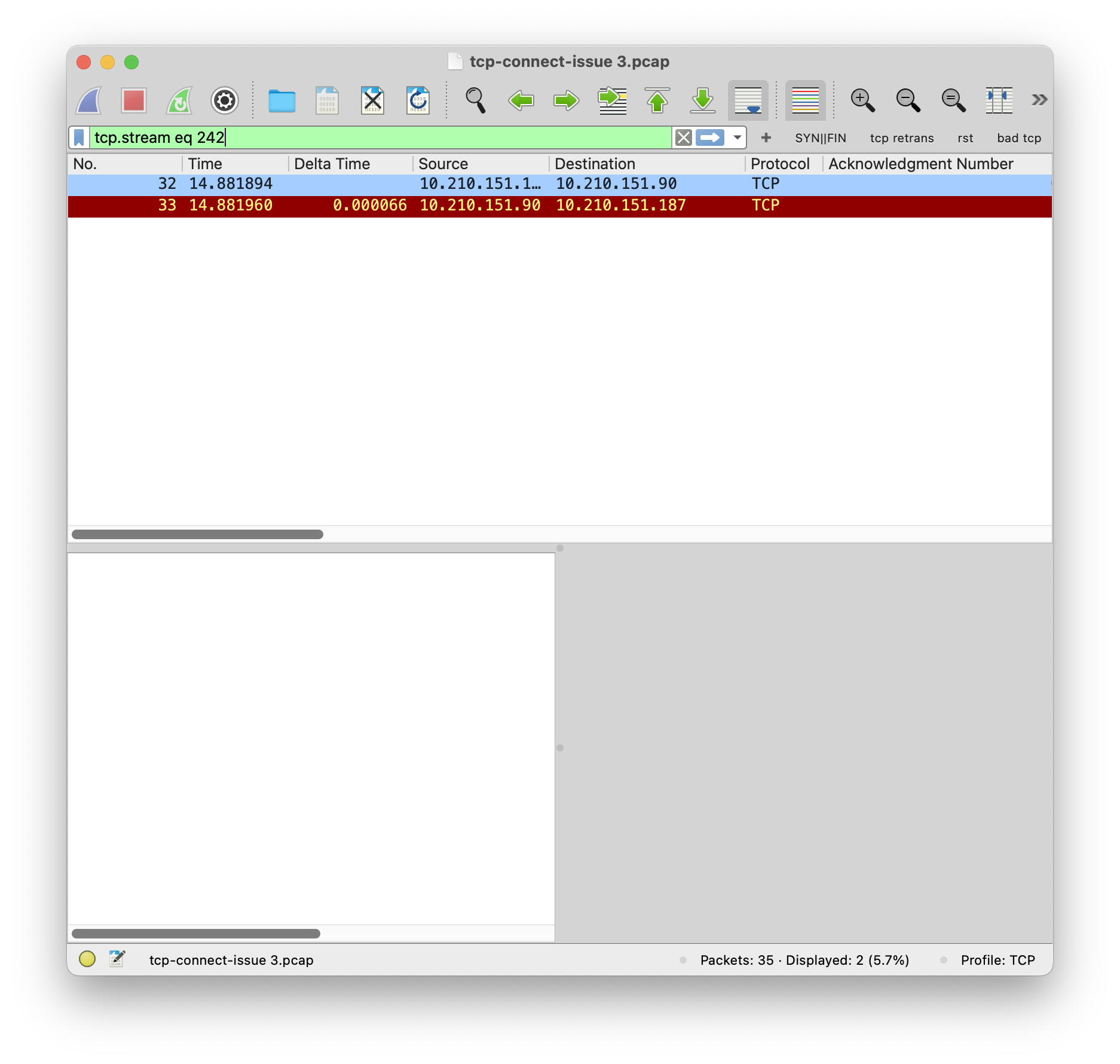
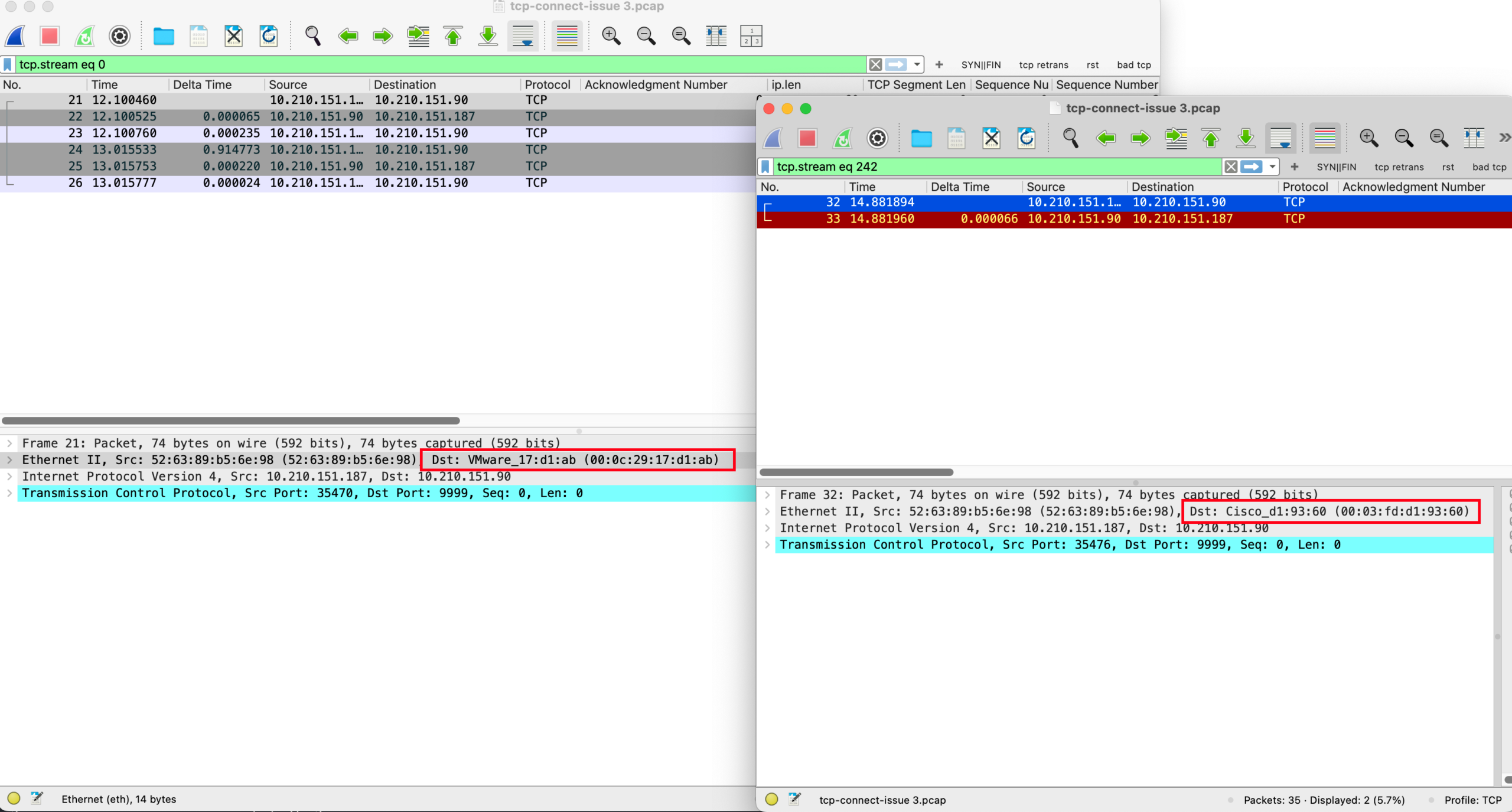
第 4 次重传发生在 3.5s 这个包不再以 1500 bytes 发送了,而是 1076 bytes (TCP 层是 1024 bytes) 发送。这个包得到了服务端的 ACK。
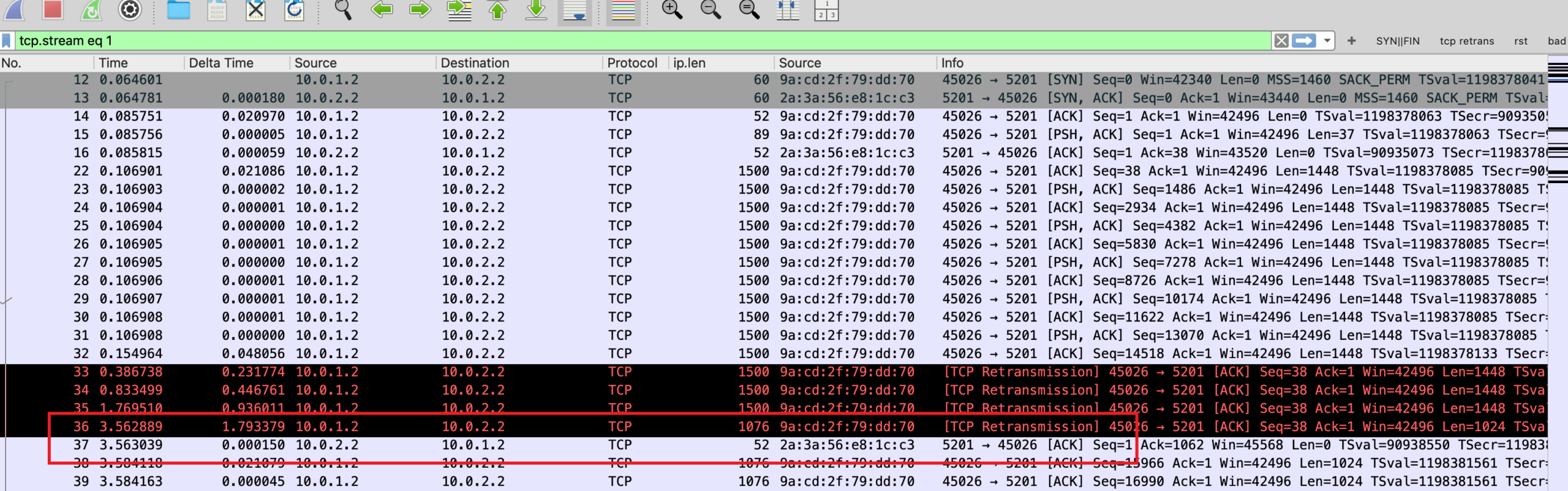
于是客户端知道,1076 bytes 的包可以被服务端收到,所以后续都用 1076 bytes 作为 MTU 发送。过一段时间之后尝试更大的包,1288 bytes,1394 bytes,发现也没有被 drop,就继续 probe 并且增大 MTU,最后用 1399 bytes,接近链路的真实 MTU (实际链路 MTU 是 1400 bytes)。
这就是每一个连接都会卡 3.5s 的原因。
为什么要重传 3 次才开始降低 MTU 呢?
这是通过 tcp_retries1 设置的。man 是这么说的:
The number of times TCP will attempt to retransmit a packet on an established connection normally, without the extra effort of getting the network layers involved. Once we exceed this number of retransmits, we first have the network layer update the route if possible before each new retransmit. The default is the RFC specified minimum of 3.
即 TCP 会尝试 tcp_retries1 次数的重传,而不涉及 IP (network) layer.
如果超过了 tcp_retries1 还没有重传成功的话,(默认第 4 次)就会认为链路存在异常了,需要 IP 层接入,比如开始 mtu probe 尝试解决问题。
如果设置为 1,那么在卡的时间就会降低到 1s 左右。(当然,最好的解决方式还是设置正确的 MTU)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# sysctl -w net.ipv4.tcp_retries1=1 net.ipv4.tcp_retries1 = 1 # iperf3 -c 10.0.2.2 -b 10M Connecting to host 10.0.2.2, port 5201 [ 5] local 10.0.1.2 port 54580 connected to 10.0.2.2 port 5201 [ ID] Interval Transfer Bitrate Retr Cwnd [ 5] 0.00-1.00 sec 0.00 Bytes 0.00 bits/sec 2 1.41 KBytes [ 5] 1.00-2.00 sec 128 KBytes 1.05 Mbits/sec 22 15.7 KBytes [ 5] 2.00-3.00 sec 3.50 MBytes 29.4 Mbits/sec 2 150 KBytes [ 5] 3.00-4.00 sec 1.25 MBytes 10.5 Mbits/sec 0 200 KBytes [ 5] 4.00-5.00 sec 1.12 MBytes 9.44 Mbits/sec 0 200 KBytes [ 5] 5.00-6.00 sec 1.25 MBytes 10.5 Mbits/sec 0 200 KBytes [ 5] 6.00-7.00 sec 1.12 MBytes 9.44 Mbits/sec 0 200 KBytes [ 5] 7.00-8.00 sec 1.25 MBytes 10.5 Mbits/sec 0 200 KBytes [ 5] 8.00-9.00 sec 1.12 MBytes 9.44 Mbits/sec 0 200 KBytes [ 5] 9.00-10.00 sec 1.25 MBytes 10.5 Mbits/sec 0 200 KBytes - - - - - - - - - - - - - - - - - - - - - - - - - [ ID] Interval Transfer Bitrate Retr [ 5] 0.00-10.00 sec 12.0 MBytes 10.1 Mbits/sec 26 sender [ 5] 0.00-10.02 sec 12.0 MBytes 10.0 Mbits/sec receiver iperf Done. |
而根据 TCP 的重传时间,大概就是在 3.5s 左右了。
前面说,第 4 次重传的包是从 1076 bytes 开始发送,为什么是这个数字呢?
这个是 sysctl 参数 net.ipv4.tcp_base_mss = 1024 控制的。TCP payload 是 1024 bytes,加上 TCP 的 header,就是 1076 bytes 了。
如果读者尝试复现这个例子,会发现在 MTU 设置错误的情况下,会一直卡住。这是因为 MTU 出现问题的时候,默认的工作机制是靠 ICMP 消息 “Fragmentation Needed” (Type 3, Code 4 in IPv4) 来提示需要降低 MTU 的。但是现实情况中,这个 ICMP 一般是收不到的(因为各种设备为了所谓的「安全问题」丢弃了 ICMP),这样就会出现 blackhole,一直重试缺卡在这里。默认情况下,MTU 错误的设置地大了,是会一直卡住的。
但是可以通过 sysctl 参数设置 net.ipv4.tcp_mtu_probing,默认是 0,即不用 probe。
如果是 1 的话,在出现 blackhole 的时候就会尝试降低 segment 的大小看能不能通。即本文中的情况。
如果是 2,是一直启用,即 TCP 不管对方说的 MSS,发送的时候总是从一个小的 MSS 开始发,如果没有问题,再逐渐加大。
MTU 常见的原因,以及一些其他的相关讨论,可以参考下面列出来的 有关 MTU 和 MSS 的一切 一文。
- 有关 MTU 的详细分析,可以参考之前的文章:有关 MTU 和 MSS 的一切 ↩︎
- 重新认识 TCP 的握手和挥手:答案和解析 ↩︎
==抓包破案录==
这篇文章是抓包破案录系列文章(之前叫做《计算机网络实用技术》,后来改名了)中的一篇,这个系列正在连载中,我计划用这个系列的文章来分享一些网络抓包分析的实用技术。这些文章都是总结了我的工作经历中遇到的问题,经过精心构造和编写,每个文件附带抓包文件,通过实战来学习网络抓包与分析。
如果本文对您有帮助,欢迎扫博客右侧二维码打赏支持,正是订阅者的支持,让我公开写这个系列成为可能,感谢!
如果您正在阅读的是题目类的文章,这个目录内容正好用来隔离其他读者的评论。读完题目可以稍作暂停,进行思考,继续向下滑动,可能会被其他的读者剧透答案。
没有链接的目录还没有写完,敬请期待……
- 序章
- 抓包技术以及技巧
- 理解网络的分层模型
- 数据是如何路由的
- 网络问题排查的思路和技巧
- 不可以用路由器?(答案和解析)
- 网工闯了什么祸?(答案和解析,阅读加餐!)
- 重新认识 TCP 的握手和挥手(答案和解析)
- 3.5 秒初始延迟问题 (答案和解析)
- 网络断断续续…… (答案和解析)
- 延迟增加了多少?(答案和解析)
- 压测的时候 QPS 为什么上不去?(答案和解析)
- TCP 下载速度为什么这么慢?(答案和解析)
- 请求为什么超时了?(答案和解析)
- 0.01% 的概率超时问题 (答案和解析)
- 后记:学习网络的一点经验分享
与本博客的其他页面不同,本页面使用 署名-非商业性使用-禁止演绎 4.0 国际 协议。