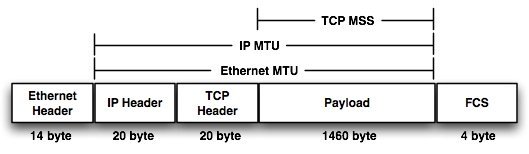
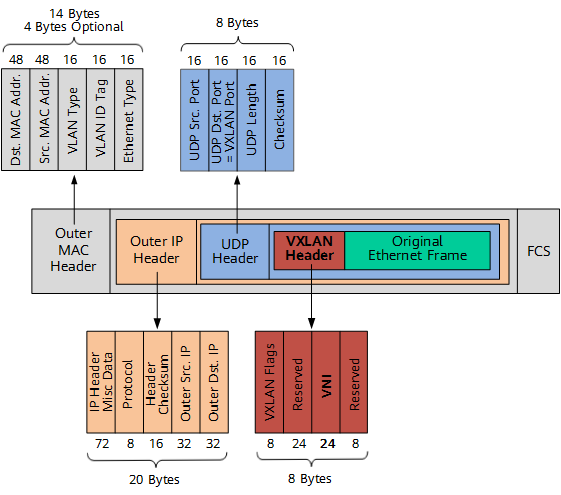
TCP MSS is an option in the TCP header that is used by the two ends of the connection independently to determine the maximum segment size that can be accepted by each host on this connection.
但是很多地方也说两边的 MSS 会一样。
这个我自己测试了一下,手动调整一端的 MTU,另一段不调整,发现两端发送数据都会比较小的值。
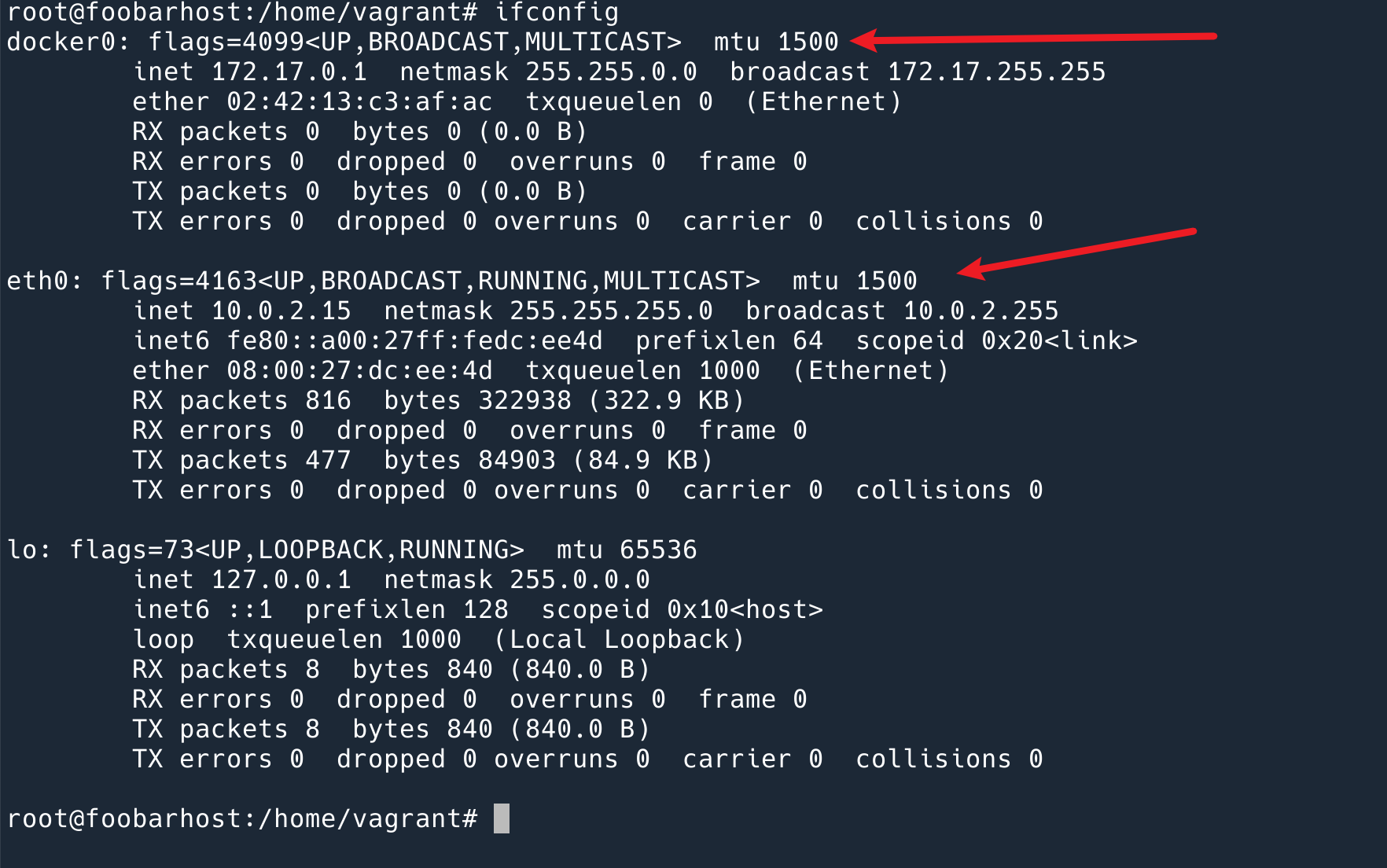
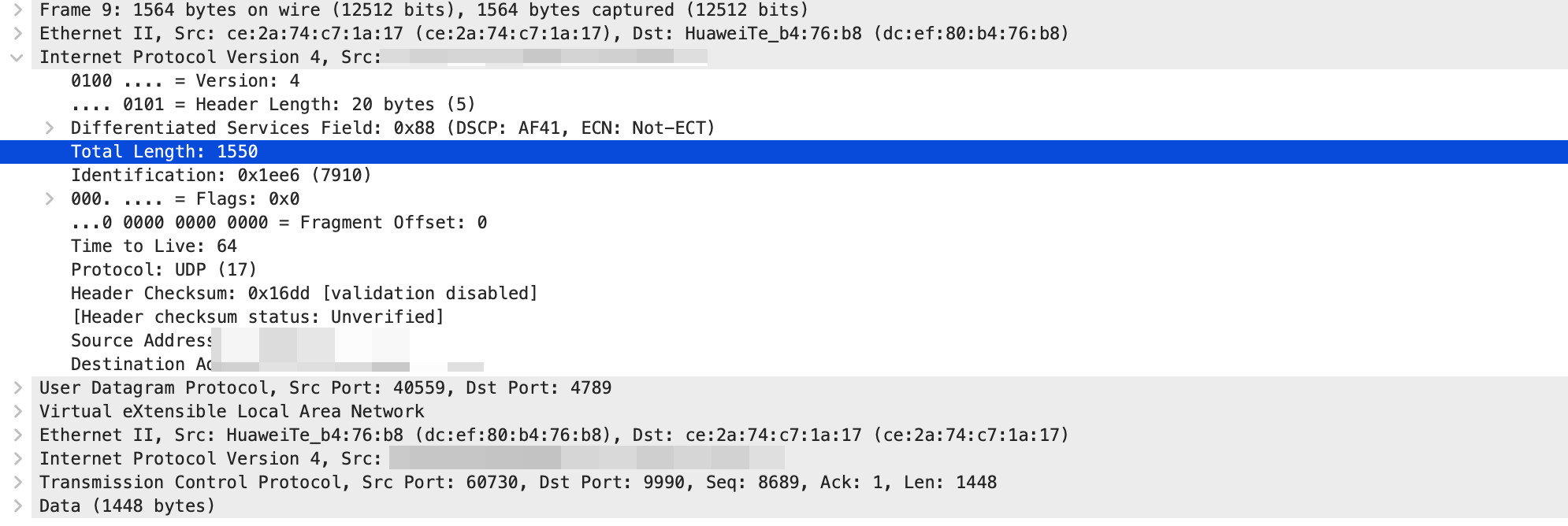
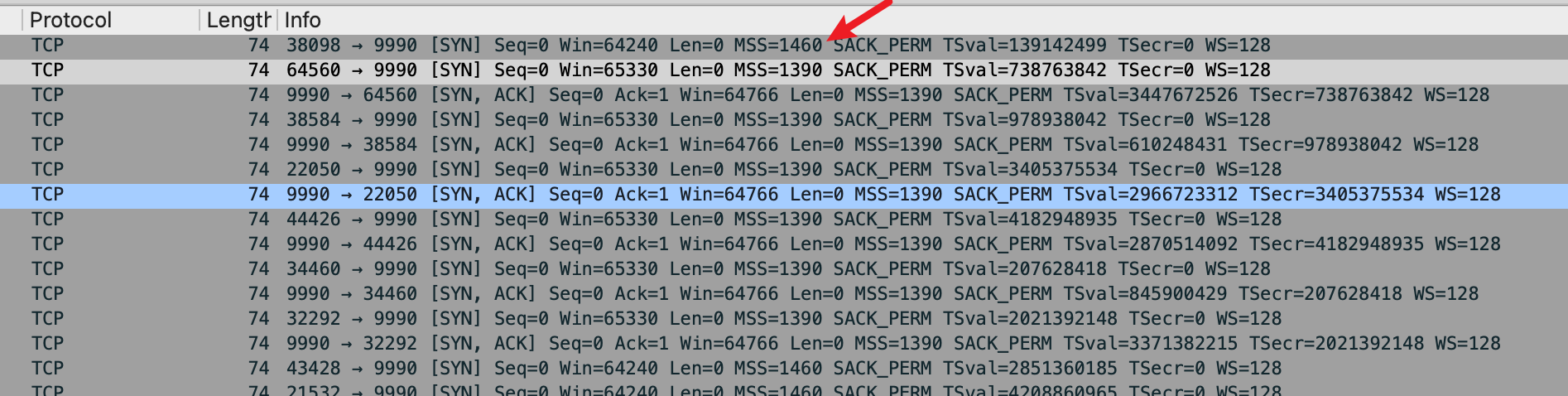
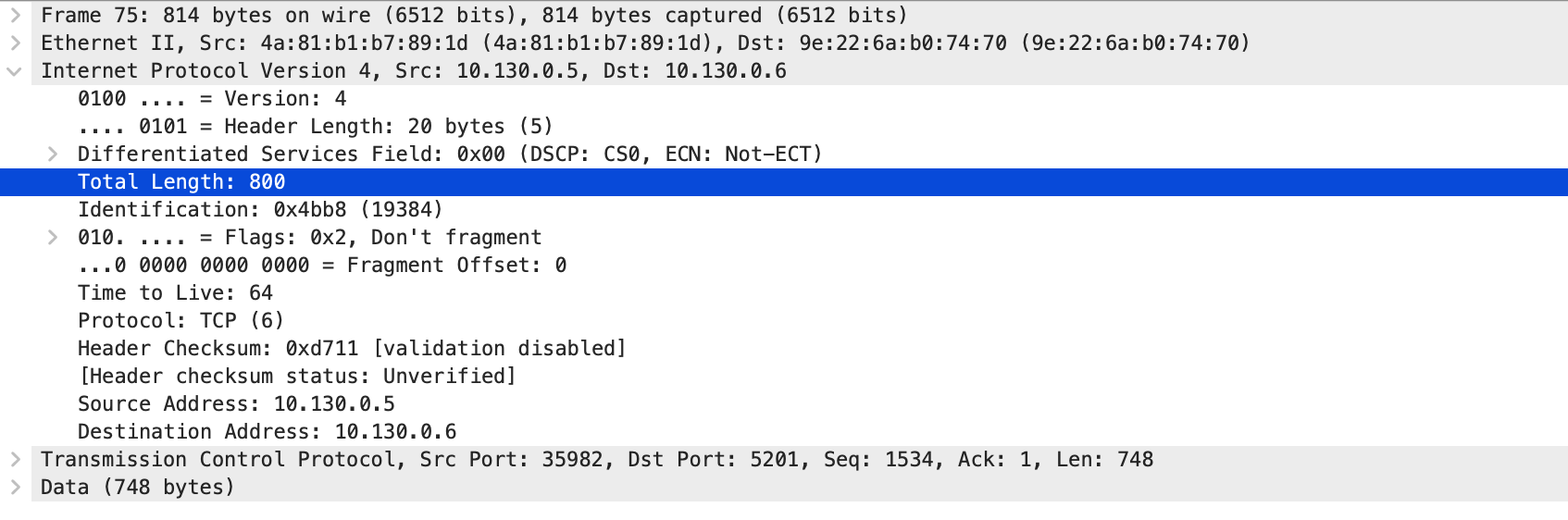
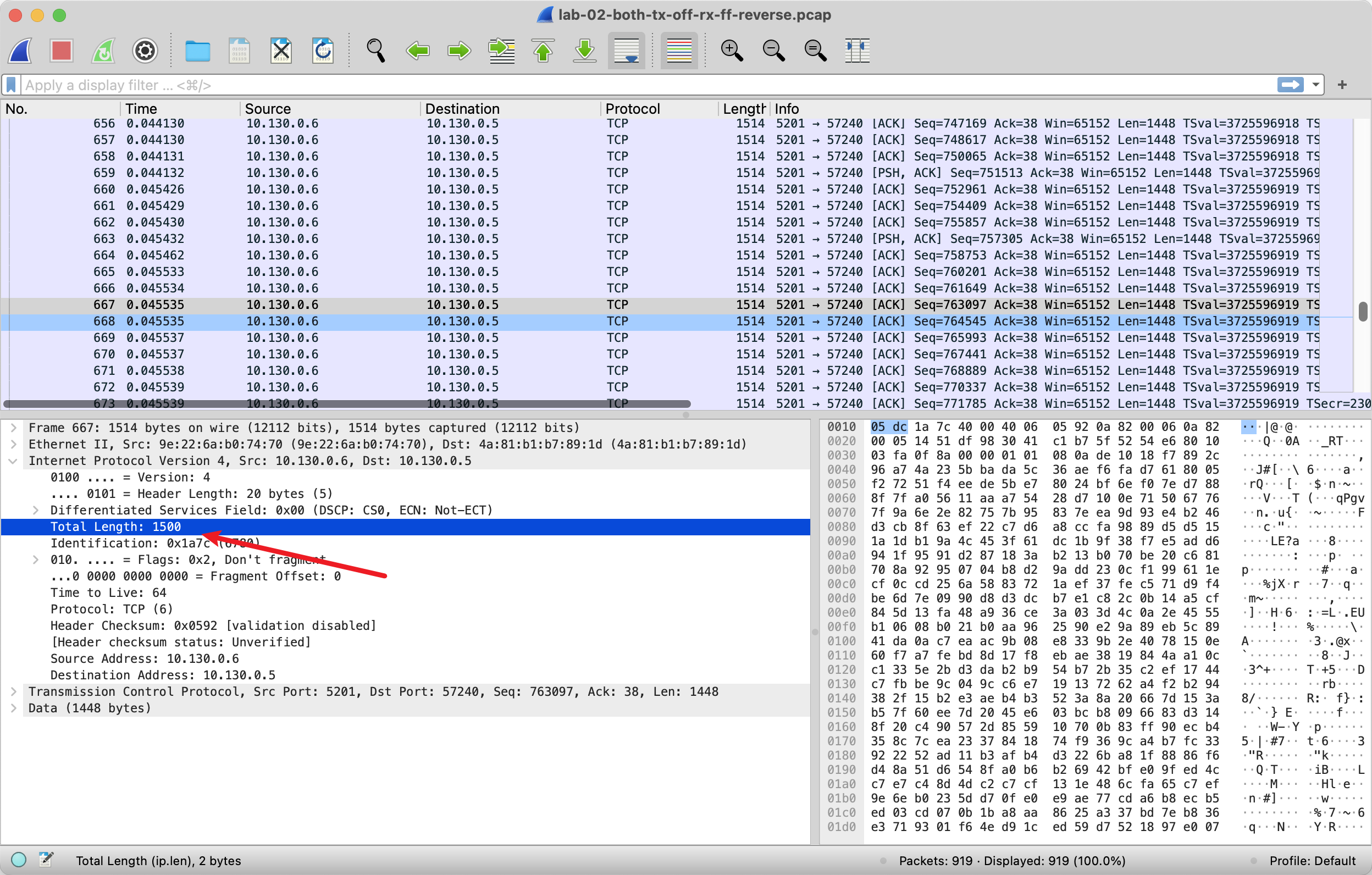
MTU 一段设置为了 800,另一段是 1500,在 TCP 握手阶段可以看到。
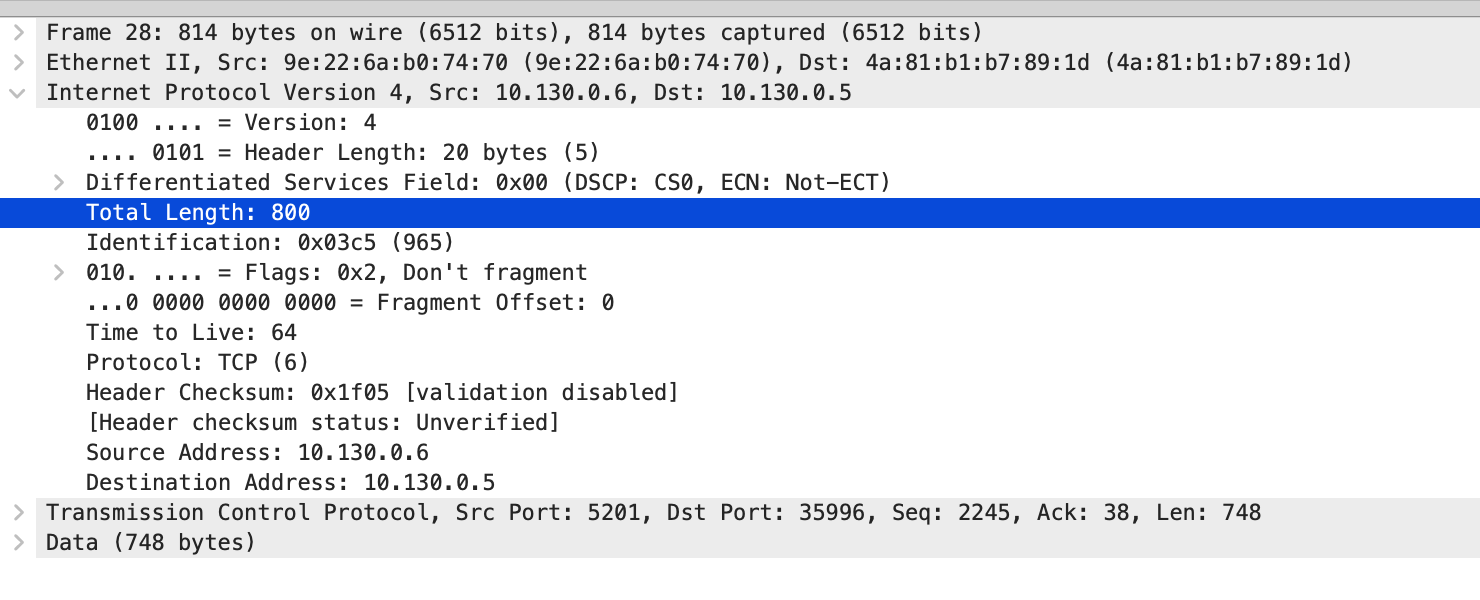
从 10.130.0.6 发送给 10.130.0.5 最大的包是 800.
从 10.130.0.5 到 10.130.0.6 也是 800.
为啥双方用一个共同的最小值,这个我没找到确凿的原因,我觉得理论上两端分别用 MSS 是可以的,就像 TCP 的 rwnd 一样。但是,在现实的网络上,A 发送 B 有限制,那么 B 发送到 A 很大可能也有一样的限制。所以两边会把这个 MSS 作为链路上某一个点的瓶颈。毕竟,每一端都只知道自己这部分网络的情况,最好是基于自己和对方综合的信息来做决策。
MSS 设置的方法
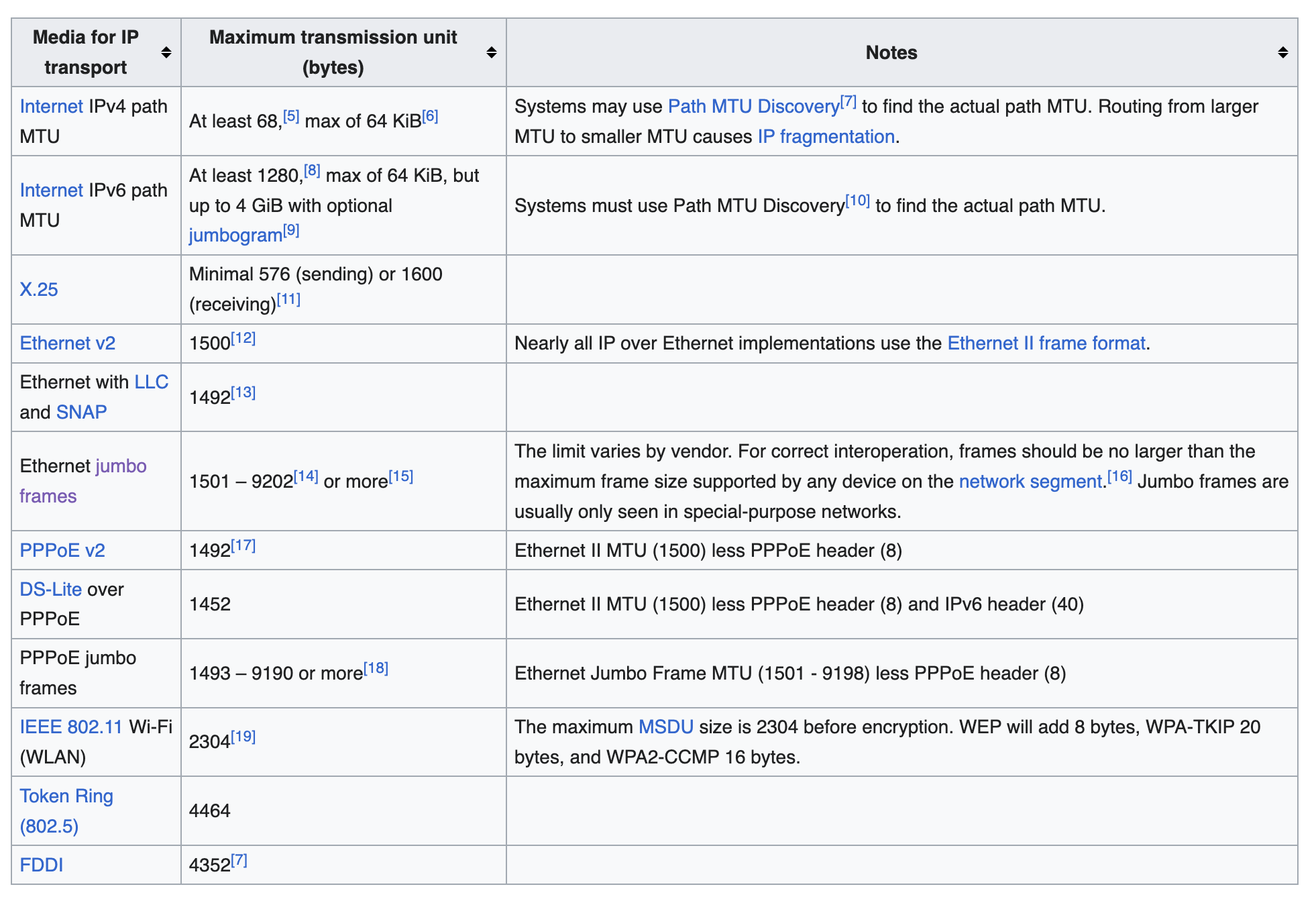
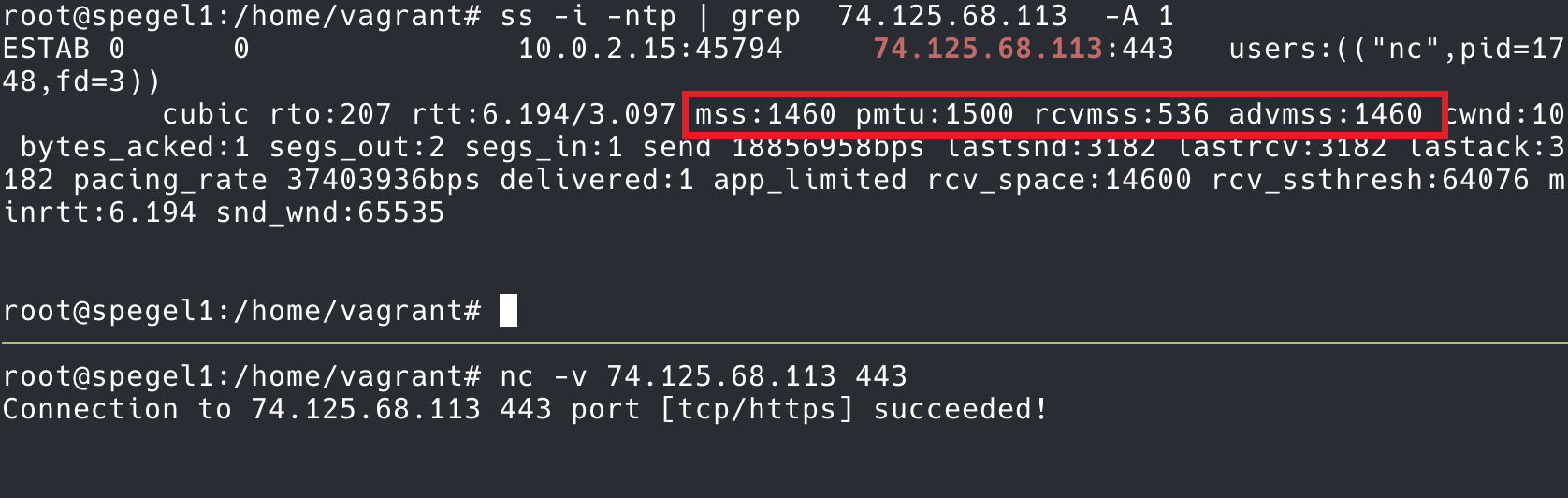
如上所说,TCP 连接建立的时候,通告给对方的 MSS 会是发包网卡的 MTU – 40 bytes(包括 20 IP headers + 20 bytes TCP headers)。但是如果已知有明确的网络情况(比如要经过 overlay 网络,要预留出来 header),怎么调小自己的 MSS 而不使用基于网卡 MTU 计算得到的 MSS 呢?设置的方法有 3 种:
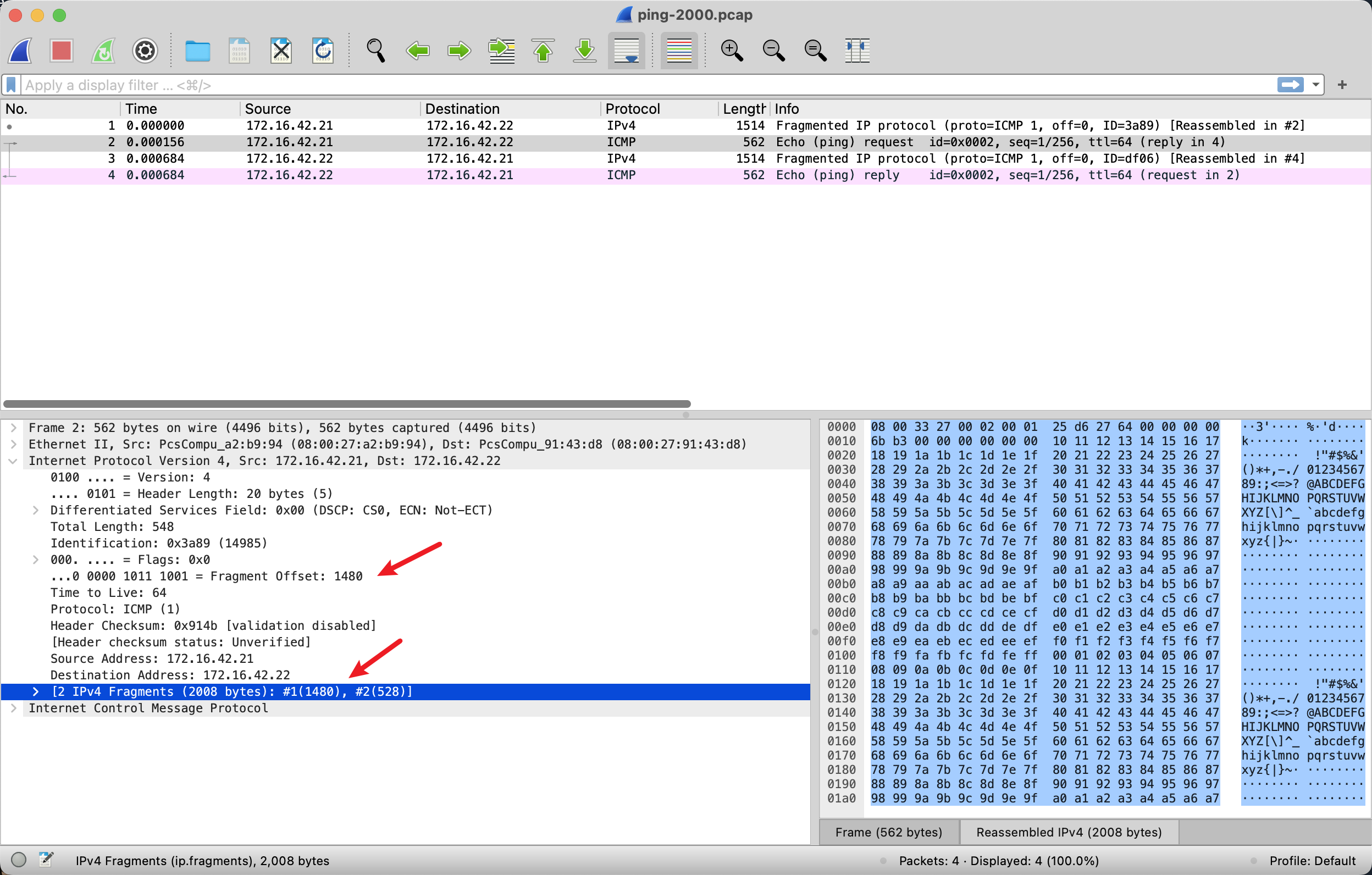
可以看到一个 ping 一共有 4 个 IP 包,2个完成 Echo 2 个完成 Reply. 其中 Echo request,第一个 IP 包总大小是 1500 bytes,除了 IP 包的 20bytes header,还剩下 1480 bytes 是 ICMP 的数据,第二个 IP 包里面有 528bytes 是 ICMP 数据,两个 IP 包带的数据一共 2008 bytes,是符合我们的预期的,8bytes 是 ICMP 的 header。
由此,可以发现 IP Fragmentation 其实是把上层的数据拆分到多个 IP 包里面,不管上层的数据是什么。说白了,第一个 frame 有 ICMP 的 header,第二个 ICMP 包没有。如果把承载 ICMP 协议换成 TCP 协议,我们就可以发现问题了:收到了 IP framented frame,是无法处理的,因为这个 IP 包的数据对于上层协议来说是不完整的,假设一个 IP 包被 fragment 成了 3 个 IP 包,我们就必须等到 3 个 IP 包全部到齐才可以处理。
此外,IP Fragmentation 本身就存在一些攻击面(见文末),我猜这也是 GCE 关闭了 IP Fragmentation 的原因?
所以,在现实的世界中,我们几乎看不到 IP Fragmentation 的,要依靠上层协议保证传给 IP 层的数据大小不需要 fragment.
Layer 4
上文已经提到了 MSS。但是我们平时写应用程序的时候,从没有自己分过 Segment,这是因为 TCP 是面向数据流的,你有一个 socket 之后,尽管向里面写就可以了,Kernel 的协议栈会负责给你将数据拆成正好能放到 IP 包里的大小发出去。注意这里是拆成多个 TCP segment 发送,在 IP 层并没有拆开,每一个 IP 包里面都有 TCP 的 header。
Layer 3 的 IP Fragment 会导致这么多问题,我们宁愿这个包被丢弃,也不要分成多个包发送。
DF(Don’t fragment bit)
IP 协议的 header 中有一位 bit 叫做 DF,如果这个 bit 设置了,就是告诉中间的路由设备不要分片发送这个包,如果大于最大传输单元的大小,直接丢弃即可。丢弃这个包的设备会发回一个 ICMP 包,其中,type=3 Destination Unreachable, Code=4 Fragmentation required, and DF flag set. RFC 1191
用 tcpdump 我们可以这么抓 ICMP 包:tcpdump -s0 -p -ni eth0 'icmp and icmp[0] == 3 and icmp[1] == 4'
还可能有另一个问题,有些 DC 可能用了 ECMP 技术,简单来说,一个 IP 后面有多个服务器,ECMP 会根据 TCP 端口,和 IP 来做 hash,这样可以根据 IP + Port 来保证路由到正确的 Server 上,即使 IP 一样。但是对于 ICMP 包来说就有问题了,ICMP error 包可能被路由到了错误的服务器上,导致 PMTUD 失败。Cloudflare 就遇到过这个问题。
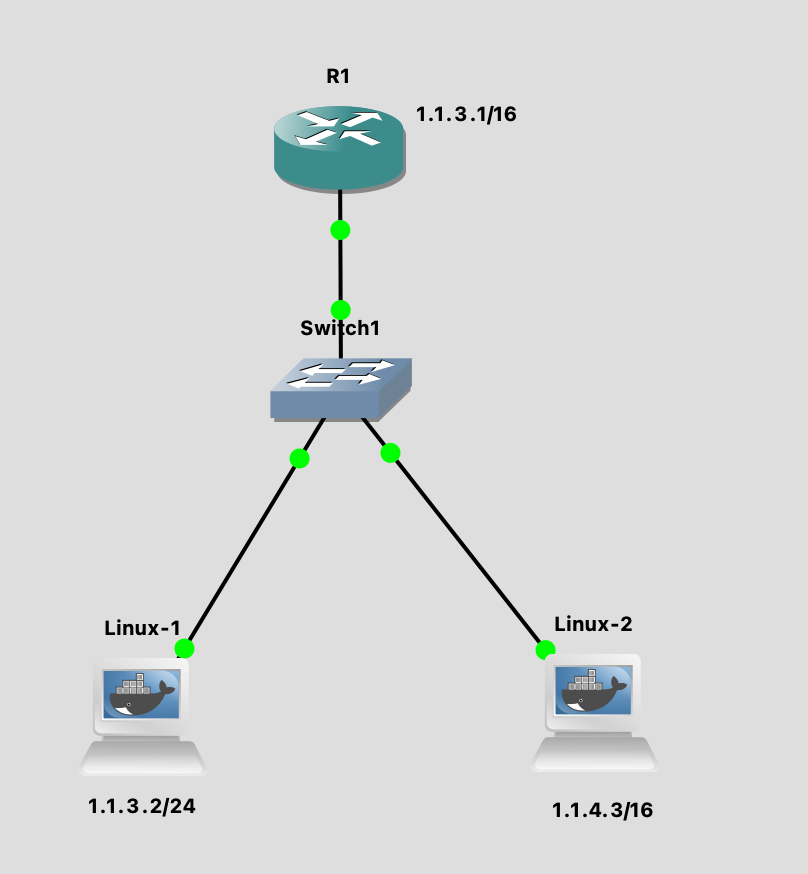
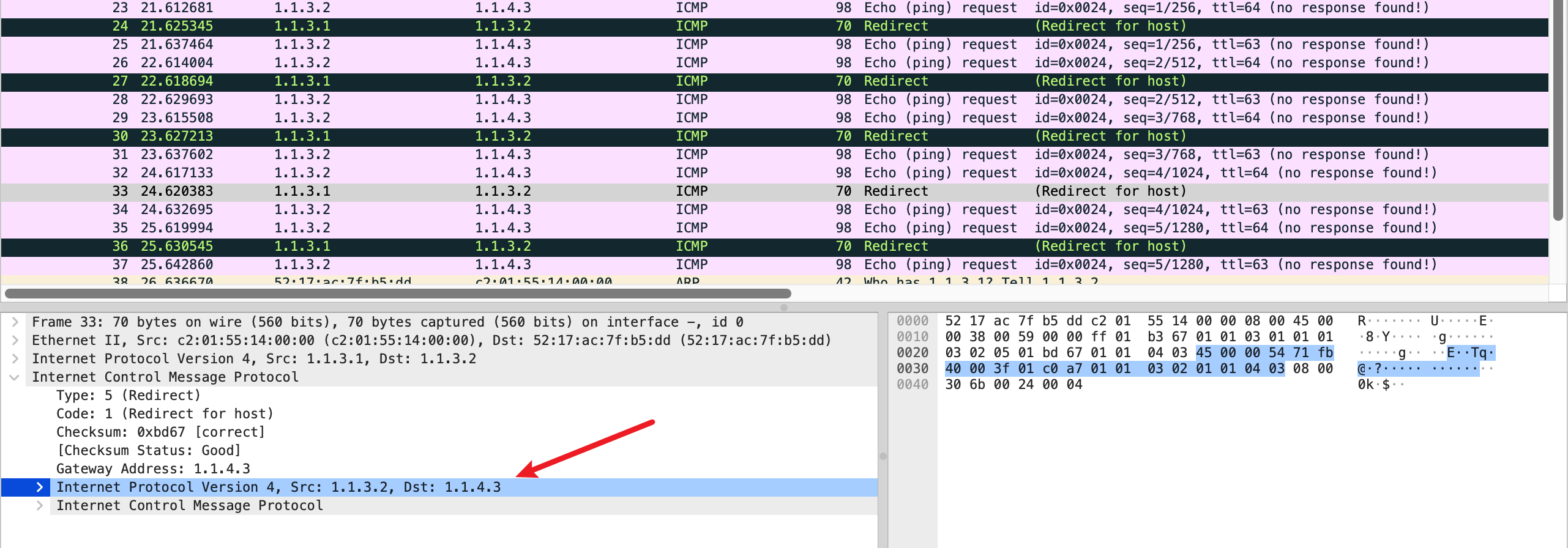
The gateway sends a redirect message to a host in the following situation.
A gateway, G1, receives an internet datagram from a host on a network
to which the gateway is attached. The gateway, G1, checks its routing
table and obtains the address of the next gateway, G2, on the route to
the datagram’s internet destination network, X. If G2 and the host
identified by the internet source address of the datagram are on the same
network, a redirect message is sent to the host. The redirect message
advises the host to send its traffic for network X directly to gateway
G2 as this is a shorter path to the destination. The gateway forwards
the original datagram’s data to its internet destination.
arp_ignore – INTEGER
Define different modes for sending replies in response to
received ARP requests that resolve local target IP addresses:
0 – (default): reply for any local target IP address, configured
on any interface
1 – reply only if the target IP address is local address
configured on the incoming interface
2 – reply only if the target IP address is local address
configured on the incoming interface and both with the
sender’s IP address are part from same subnet on this interface
3 – do not reply for local addresses configured with scope host,
only resolutions for global and link addresses are replied
4-7 – reserved
8 – do not reply for all local addresses
The max value from conf/{all,interface}/arp_ignore is used
when ARP request is received on the {interface}
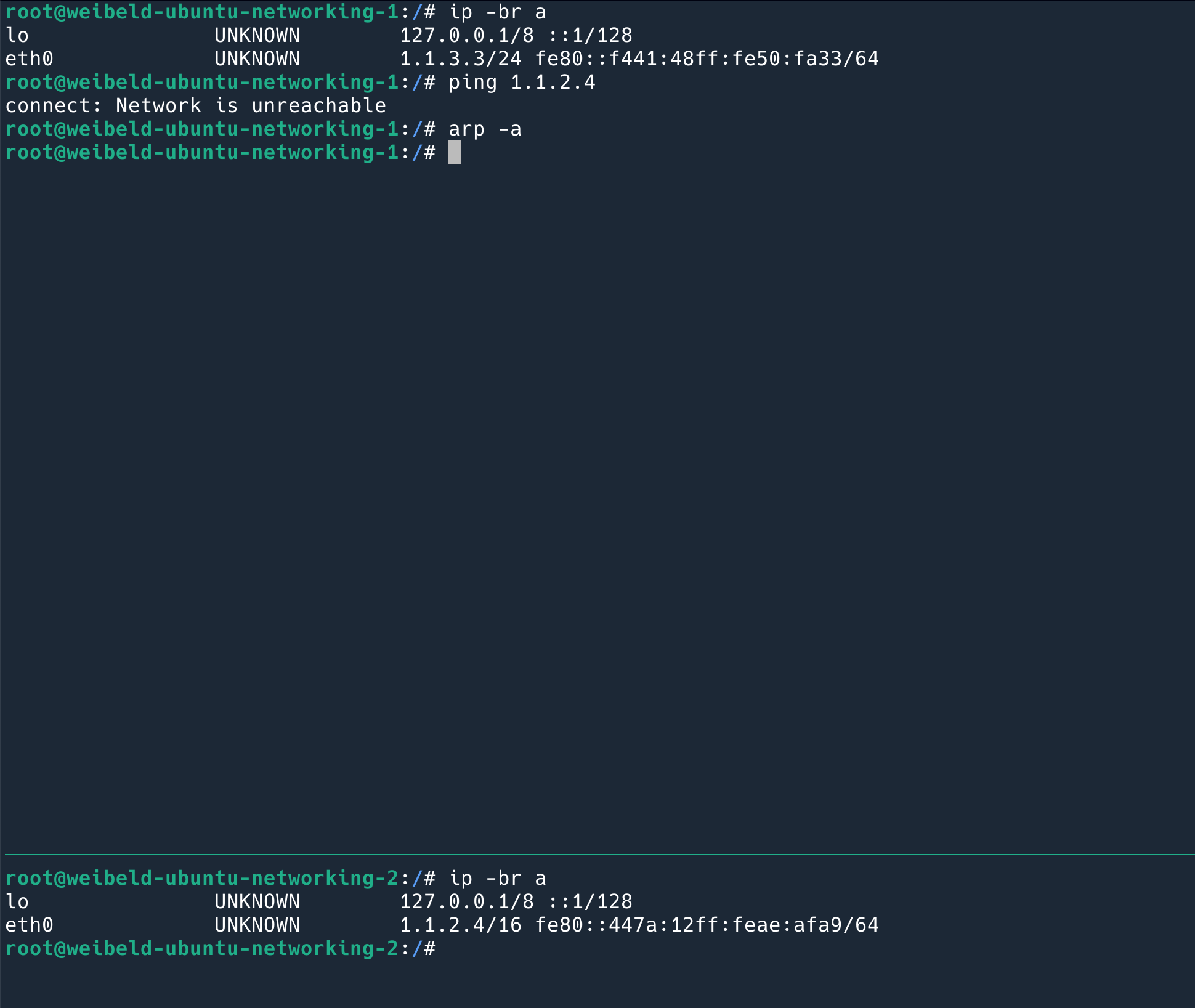
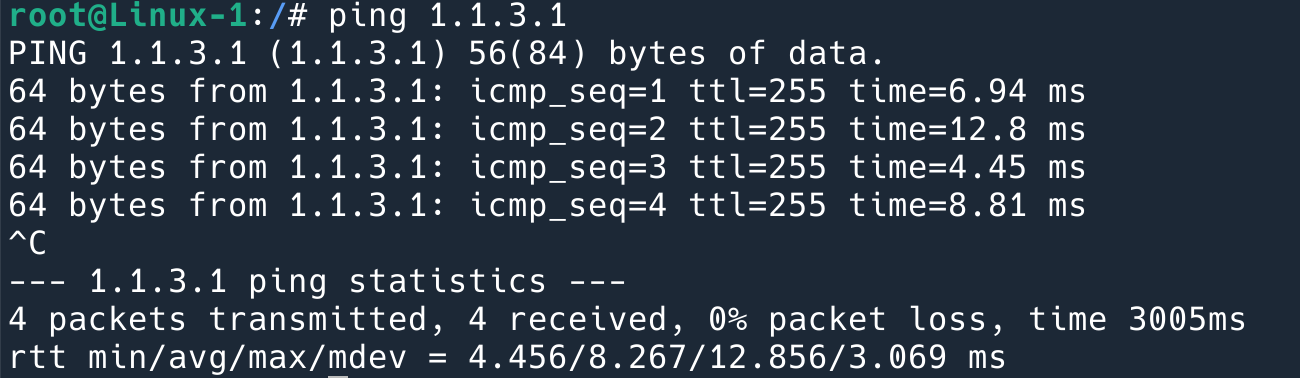
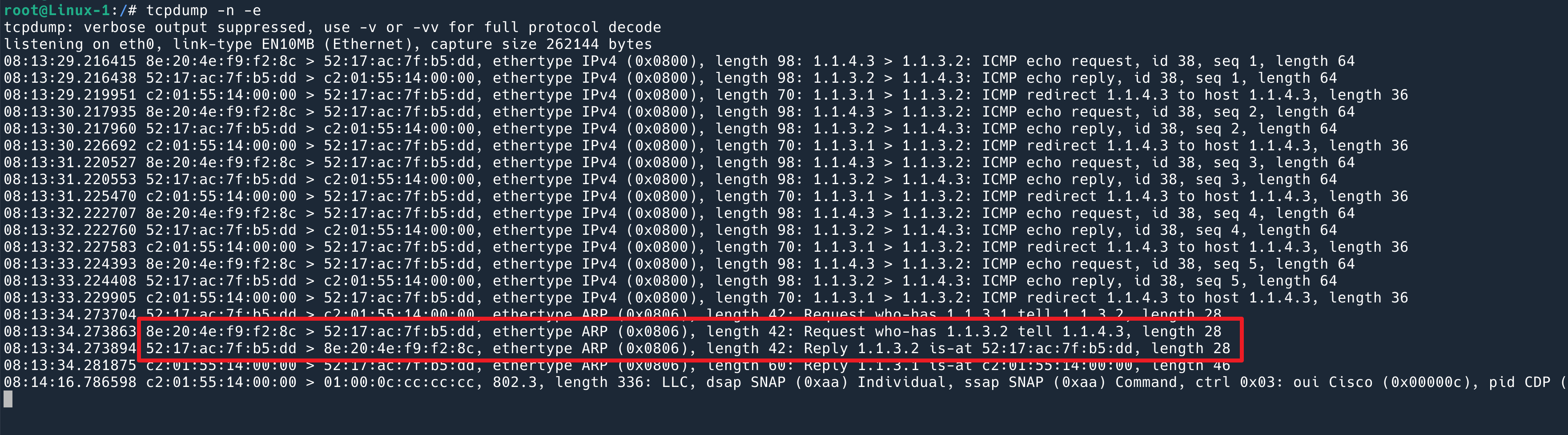
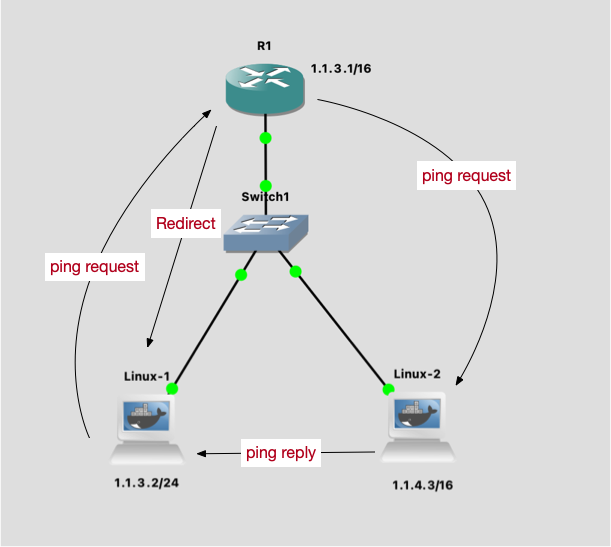
因为默认值是 0, 所以是会回复的。通过 tcpdump 在 linux1 上抓包可以确认:
这时候 1.1.4.3 拿到了我的 MAC,就直接在二层把 ping 的 reply 发给我了。
如果在 Linux2 这台机器上,即 1.1.4.3 上,抓包,会发现一个有意思的现象:它从路由器 MAC 收到的 ping 包,回复给了另一个 MAC 地址。
RTLD_NEXT
Find the next occurrence of the desired symbol in the search order after the current object. This allows one to provide a wrapper around a function in another
shared object, so that, for example, the definition of a function in a preloaded shared object (see LD_PRELOAD in ld.so(8)) can find and invoke the “real” func‐
tion provided in another shared object (or for that matter, the “next” definition of the function in cases where there are multiple layers of preloading).
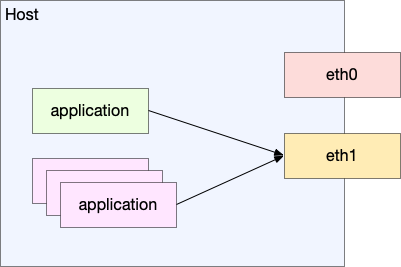
所以这里用的就是 glibc 提供的 socket 函数了。
这个方法也有缺点,就是它只对 dynamic link 的程序有效,像 golang 这种语言默认是全部静态编译的,连 glibc 都不用,LD_PRELOAD 自然就无效了。这种情况我们就只能修改程序的代码,让它自己标记自己的流量了。
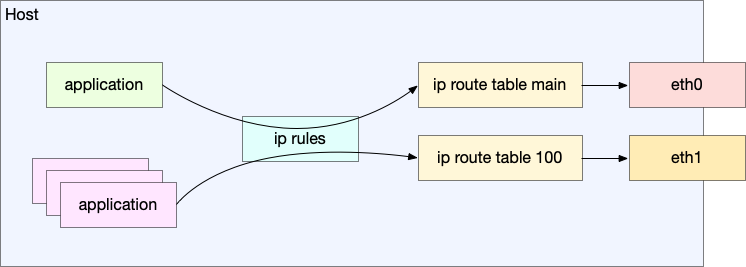
iptables 居然支持直接按照 uid 来匹配,之前一直不知道这个。这样的话只要给进程分配一个单独的 user 来运行就好了。
此外,还支持 gid, pid, sid, cmd owner 来匹配:
–uid-owner userid
Matches if the packet was created by a process with the given effective user id.
–gid-owner groupid
Matches if the packet was created by a process with the given effective group id.
–pid-owner processid
Matches if the packet was created by a process with the given process id.
–sid-owner sessionid
Matches if the packet was created by a process in the given session group.
–cmd-owner name
Matches if the packet was created by a process with the given command name. (this option is present only if iptables was compiled under a kernel supporting this feature)