最近在学习 BPF,这是一种目前比较流行的动态追踪技术,简单来说,它允许我们在不中断目前正在运行的程序的情况下,插入一段代码随着程序一起执行。比如你想知道某一个函数每次 return 的值是什么,就可以写一段 BPF 程序,把每次 return 的值给打印出来;然后把这个函数 hook 到函数调用的地方,这样,程序在每次调用到这个函数的时候都会执行到我们的 BPF 程序。
这种不终止程序,能去观测程序的运行时的技术是很有用的。
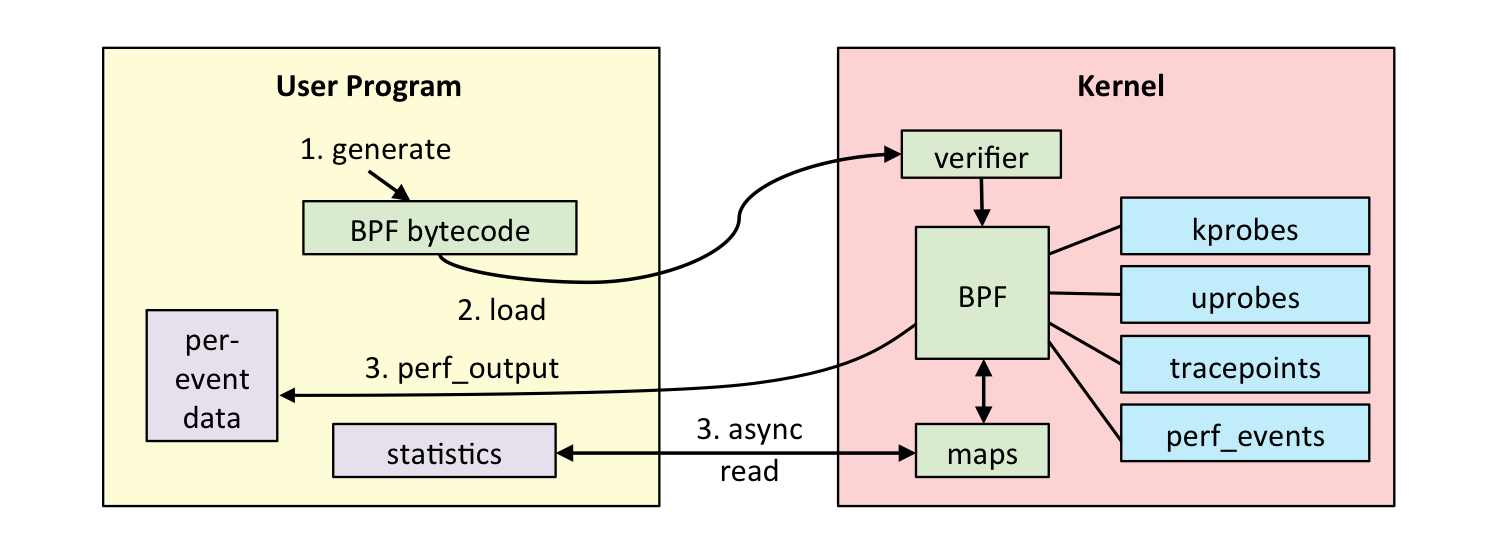
它的原理大致上是:
- 找到要观测函数调用的地址(所以用 BPF 的时候我们通常需要带 debug 符号的 binary),将这个地址的指令换成
int3,即一个 break,把原来应该执行的指令保存起来; - 当程序执行到这里的时候,不是直接去调用函数了,而是发现这里是一个 uprobe handler,然后去执行我们定义的 handler;
- 原来的程序继续执行;
- 当我们停止 probe 的时候,把原来保存的指令复原。
例子:这行程序可以把系统中所有执行的命令打印出来 bpftrace -e 'tracepoint:syscalls:sys_enter_execve { join(args->argv); }'. 原理就是,每次执行 execve 的时候都会执行到我们定义的 join (print).
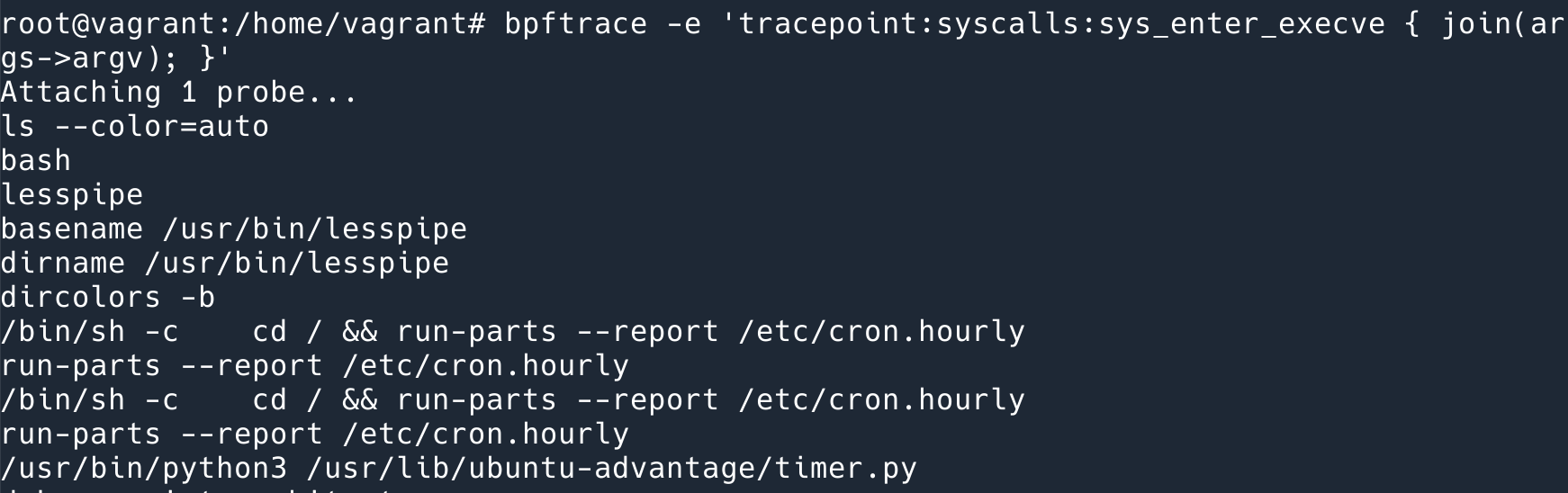
bpftrace 是一个命令行程序,它的语法类似 awk,做的事情就是:将我们写的程序(这里的程序指的是 bpftrace 定义的语法,而不是 BPF 程序)编译成 BPF 程序,然后 attach 到相应的事件上。
通过上面的描述可以看出,使用这个方法来追踪程序所需要的必备条件是:
- Kernel 要支持 BPF;(4.19+);
- 有 binary 可以追踪;
像 Python 这种解释型语言,binary 其实是一个解释器,解释器里面才是运行的 Python 代码。如果按照上述方法,追踪的其实是解释器的代码而不是我们的 Python 应用的代码。
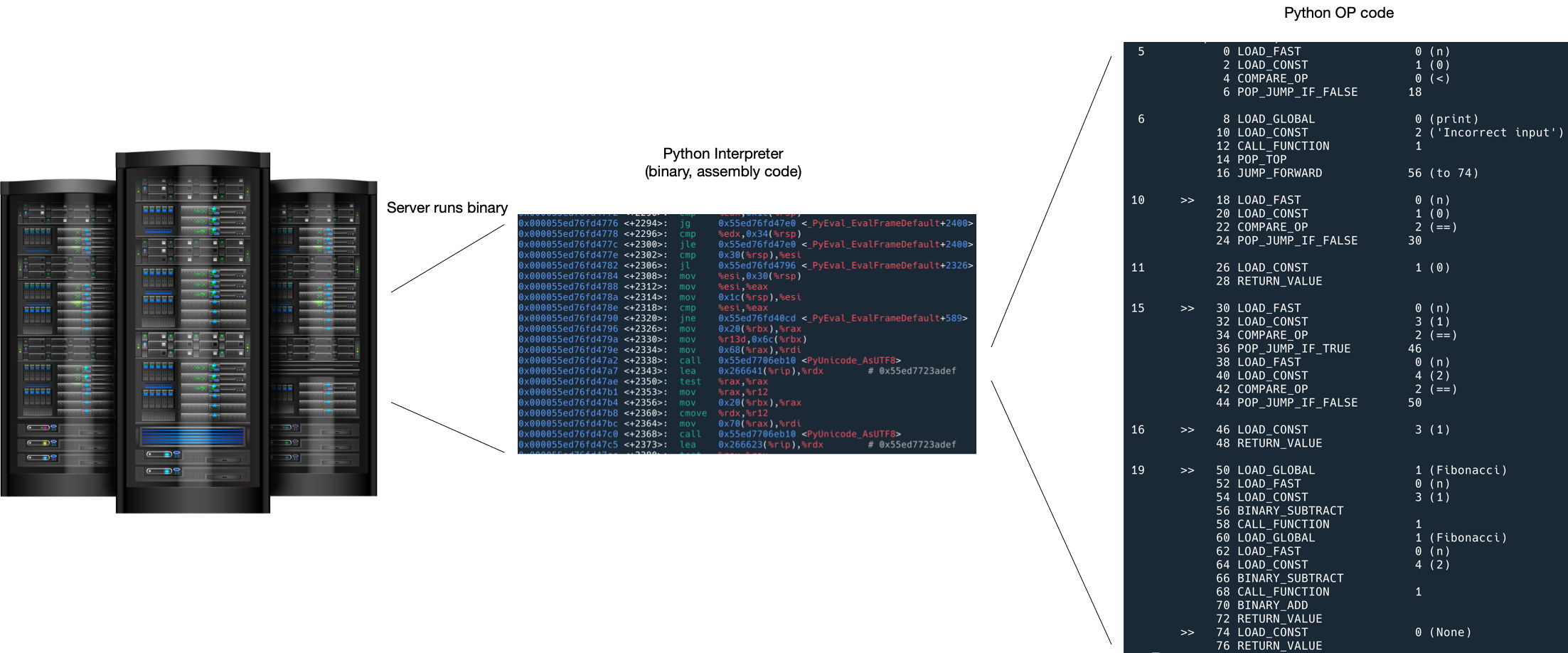
使用 USDT 追踪 Python 程序
一个解决方法是使用 USDT 追踪。
USDT 全称是 User-level statically defined tracing. 是在程序的用户态定义的追踪点。Python 解释器为我们提前定义好了一些追踪点(可以叫做 probe,或者 marker),这些追踪点默认是不激活的,所以对性能丝毫没有影响。要追踪的时候可以激活其中的几个追踪点,然后将其提供的 arguments 打印出来。
能够使用 USDT 有几个前提:
- Kernel 要支持 BPF;(4.19+); (其实使用 Dtrace 或者 systemtap 也可以)
- Python 编译的时候要打开 trace 的支持 (编译的时候有 –with-dtrace 选项),我的几个服务器中,Ubuntu 上面的 Python3.10 是开了的,Fedora 上面的 Python 3.10 貌似没有开。
使用 USDT 追踪 Python 程序
首先需要安装 bpftrace. 安装说明可以参考这里。
通过这个命令可以列出 binary 中的 USDT markers: bpftrace -l 'usdt:/usr/bin/python3:*'
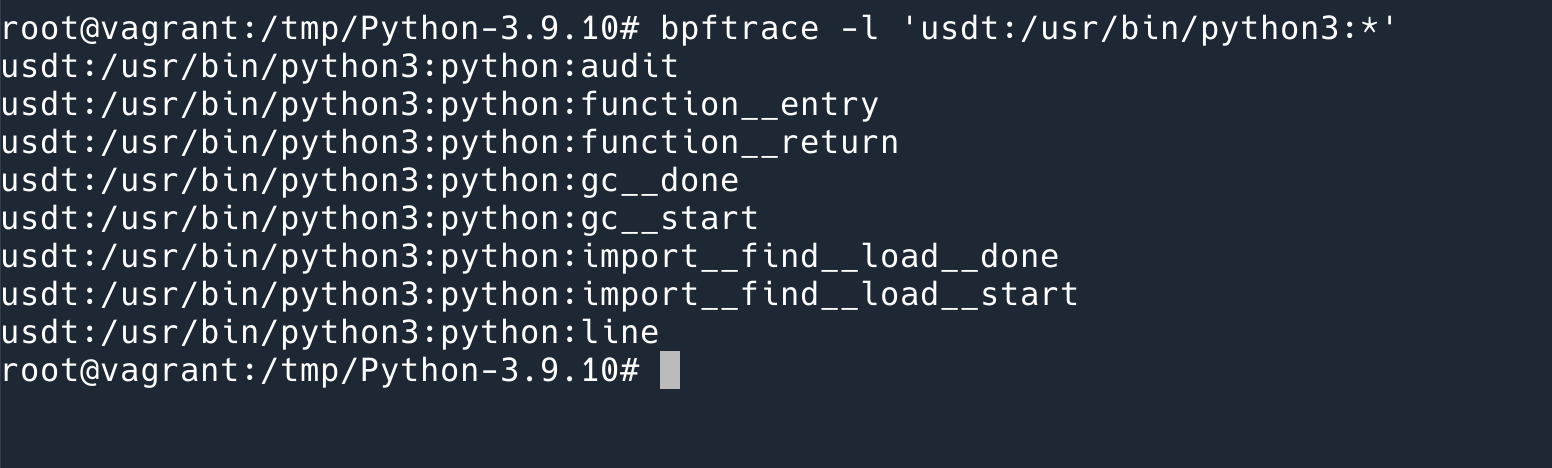
可以看到目前支持的 markers 不多,一共也就 8 个。
先拿一个来试一下:执行这个命令可以打印出来 Python 每次函数调用的时间、源代码的地址,函数名字,和行号:
bpftrace -e 'usdt:/usr/bin/python3.10:function__entry {time("%H:%M:%S"); printf(" line filename=%s, funcname=%s, lineno=%d\n", str(arg0), str(arg1), arg2);}' -p 15552
其中,-p 15552 是正在运行的 Python 程序的 pid,-e 后面跟的就是 bpftrace 的代码,很像 awk,第一个是 probe,{} 里面是代码,主要要两行,第一行打印出来时间,第二行打印出来 function__entry 这个 probe 提供的三个参数。(需要稍微注意的是,字符串参数需要用 bpftrace 内置的 str() 函数打印出来字符串,否则的话打印出来的是 char * 的地址;另外要注意虽然 Python 文档中说的这三个参数是 $arg1 $arg2 $arg3,但是实际打印的时候,应该使用的是 arg0, arg1, arg2.)
效果如下:
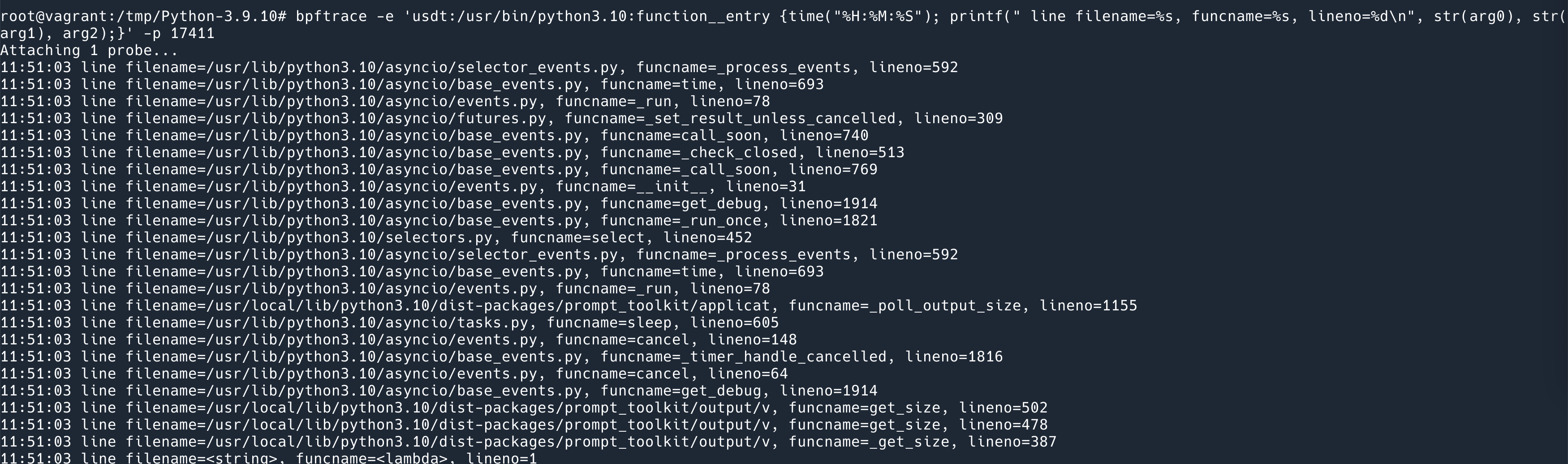
其他的几个 marker 作用是:
- function__entry: 函数入口
- function__return: 函数退出的时候
- line: 每执行一行 Python 代码都会触发
- gc__start和gc__done: gc 开始和结束的时候触发
- import__find__load__start 和 import__find__load__done:import 开始和结束的时候触发
- audit:
sys.audit调用的时候触发
可以看到,当前支持的并不多,而且从这几个 marker 可以看出,大部分的作用是让你知道 Python 解释器正在干啥,而不是 debug。如果遇到性能问题的话可以通过这个解决,但是如果遇到逻辑错误,帮不上太大的忙。比如你无法通过 usdt 看到某一个变量在某个时刻的值。
USDT 的原理
USDT 工作的原理和上文提到的 uprobe 差不多,激活的时候会改变原来执行的指令,插入 int3 去执行我们的 handler.
Seeing is believing.
我们可以通过一些工具来观察它执行的原理。
以 function__entry 为例,我们先找到它在 Binary 中的 marker, 在 .note.stapsdt 里面:
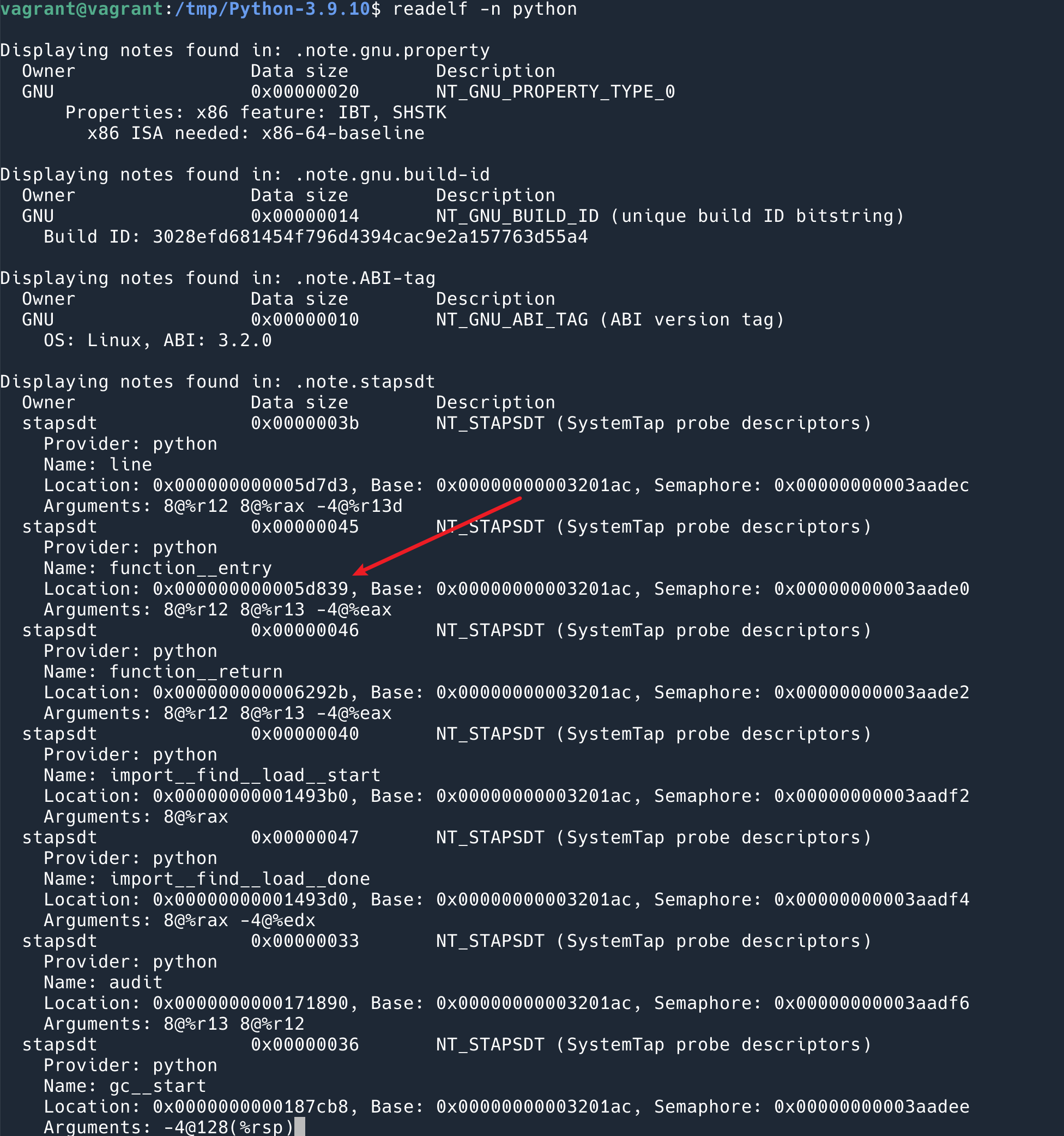
可以看到我们刚刚使用的 function__entry 的位置是 0x000000000005d839.
然后我们找到这个位置的指令。
`gdb -p 17577` 去 attach 到正在运行的这个 pid 上。然后运行 info proc mappings dump 出来地址,可以看到 Offset 0x0 的位置是 0x55bfcc88d000.
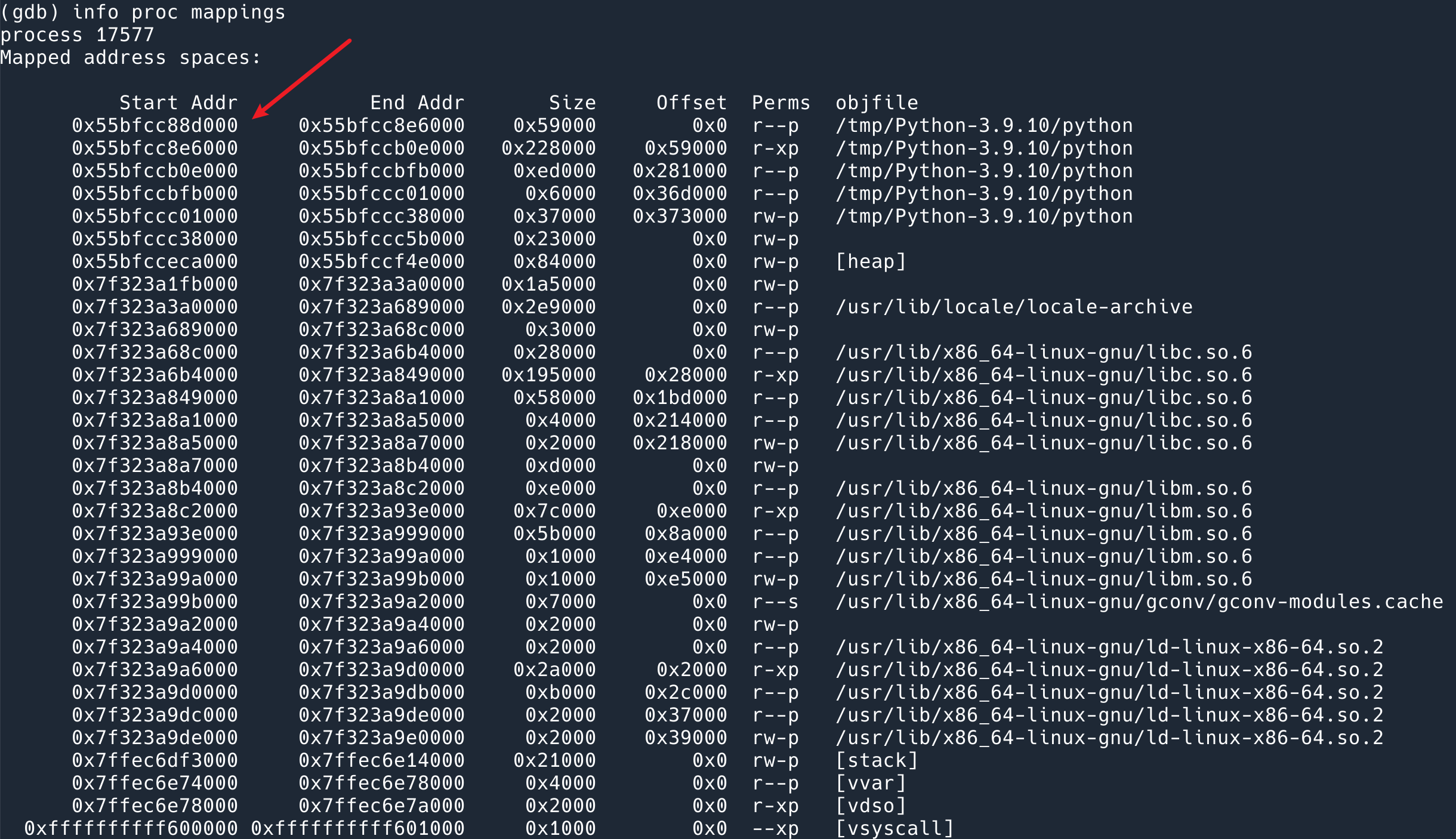
那么 function__entry 的位置应该是 0x000000000005d839 + 0x55bfcc88d000.
下面用 disas 命令可以 dump 出来这段地址的指令:
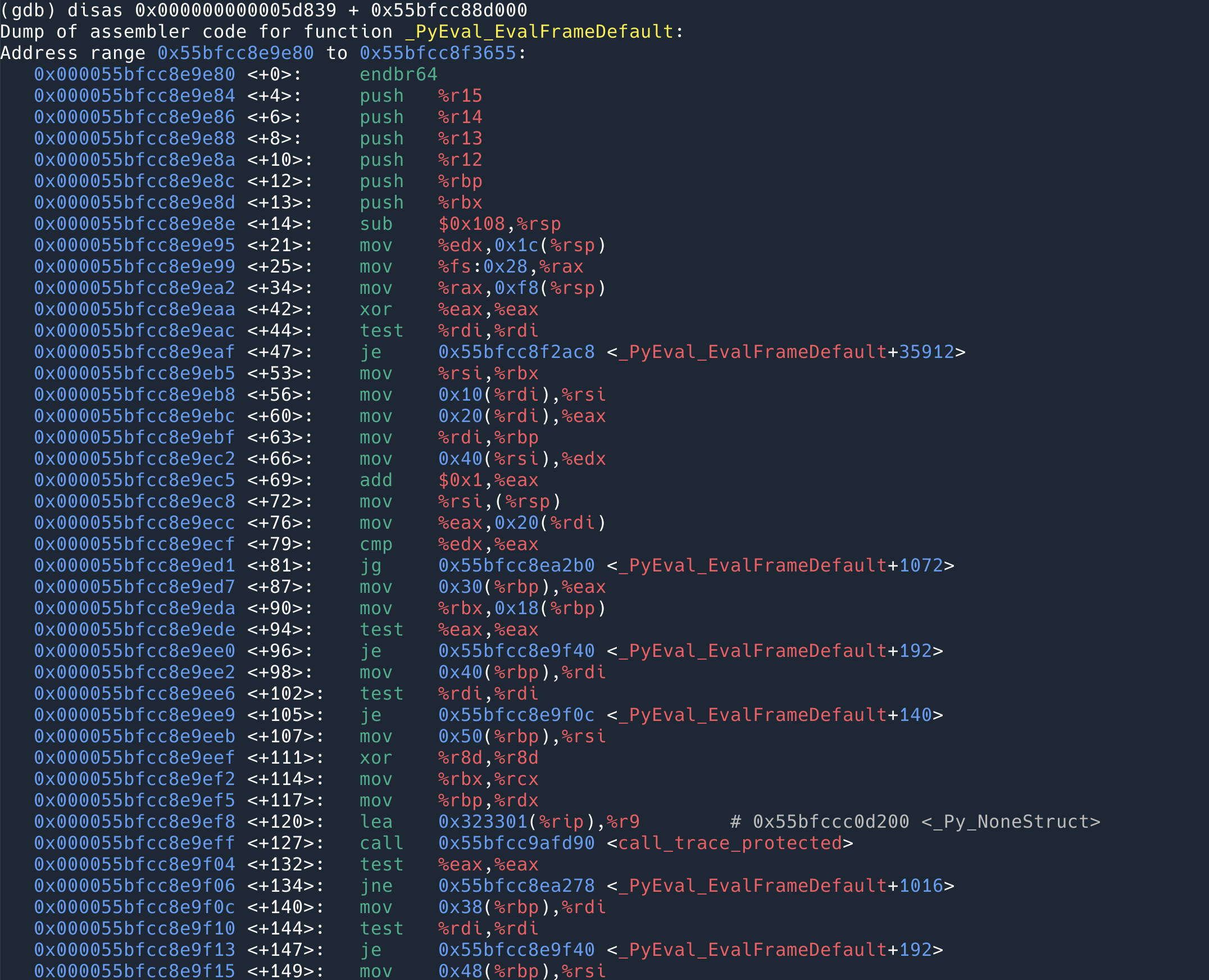
>>> hex(0x000000000005d839 + 0x55bfcc88d000) '0x55bfcc8ea839'
查找 0x55bfcc8ea839 这个地址的指令:
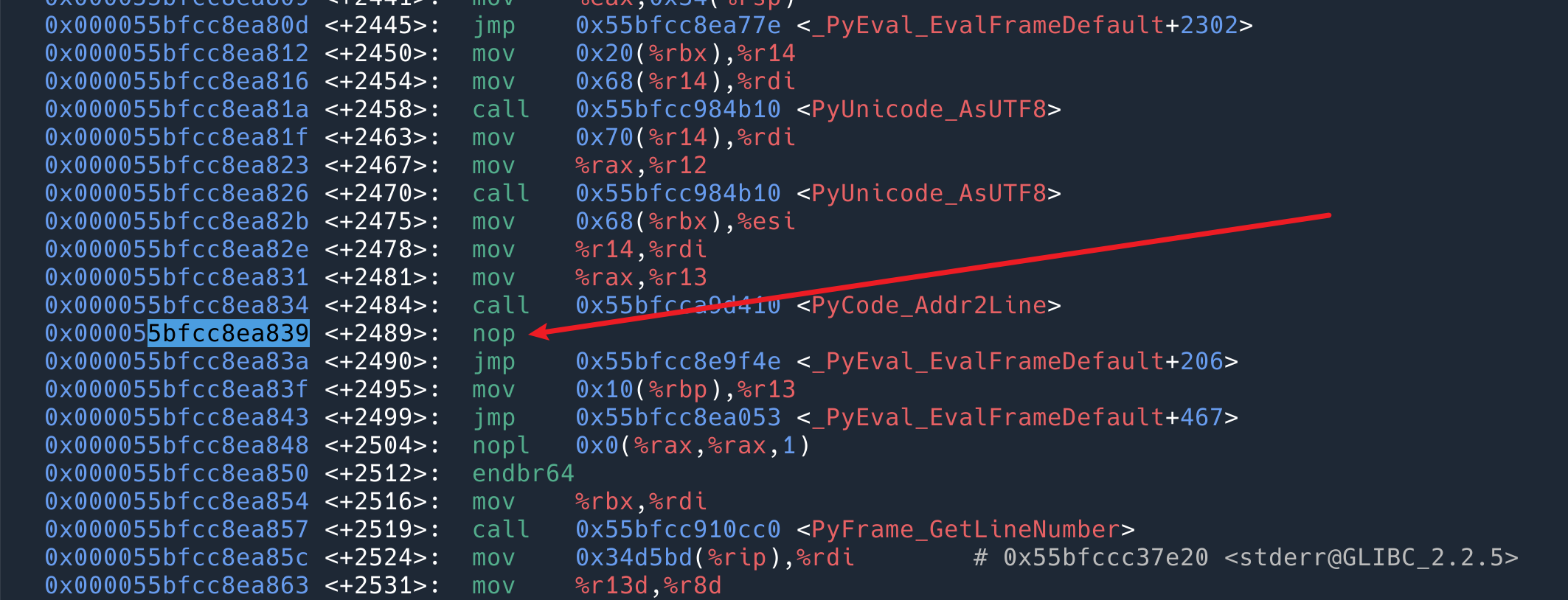
发现是一个 nop,即什么都不做。所以这就是为什么上文说,在 usdt 不开启的时候,对性能是完全没有损失的。只是多了个一个什么都不做的占位指令而已。
下面使用之前的命令去 attach 这个 usdt probe:

然后重新看一下 0x55bfcc8ea839 这个位置的指令:
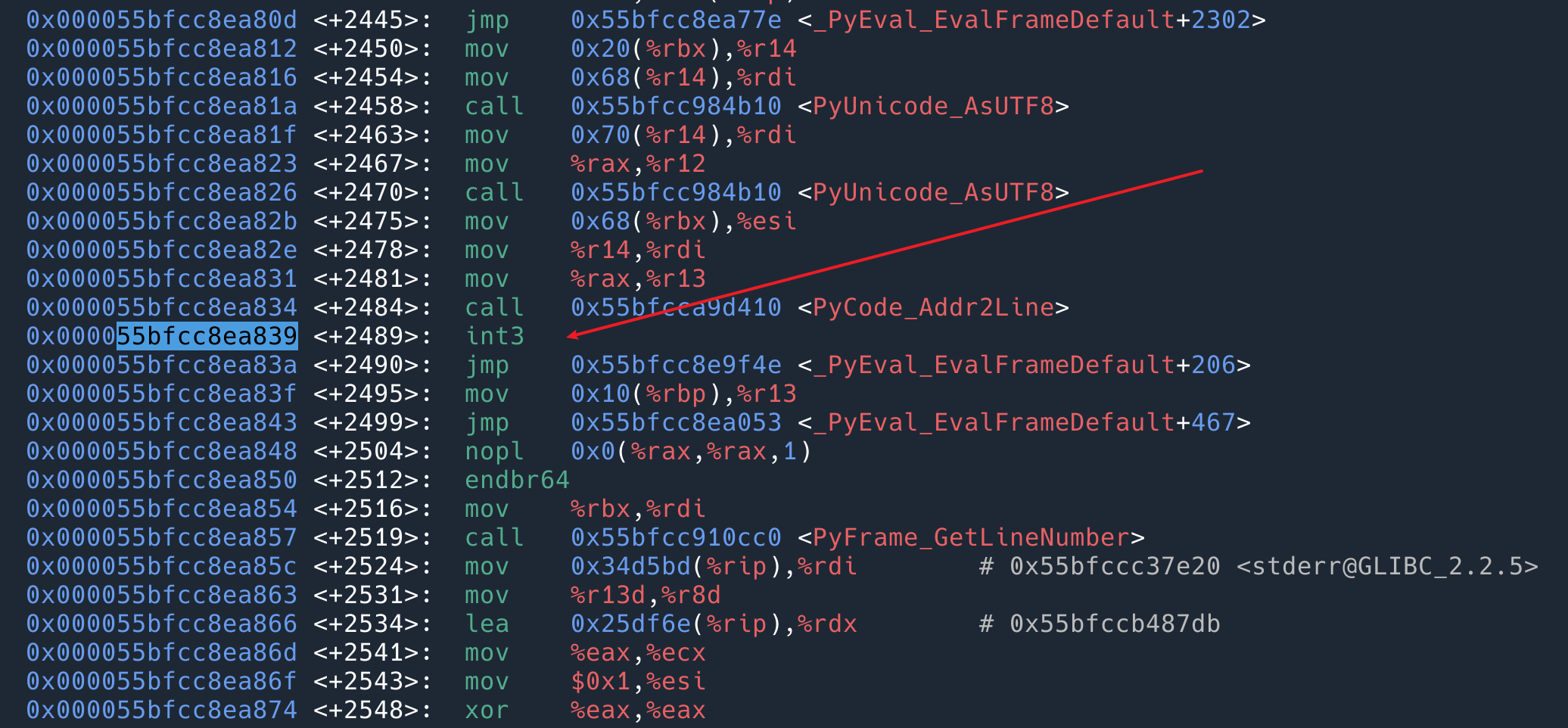
可以看到这个位置的指令已经变成了 int3. 当程序(解释器)执行到这里的时候,kernel 就会执行用 usdt 提供的变量去执行我们的 BPF 程序。当 BPF probe 退出的时候,int3 会被恢复成 nop.
更多的可能?
在网上查询和 Python 有关的 BPF 内容大部分都是“如何通过 Python(BCC)来使用 BPF”,而不是“如何用 BPF 去 profile Python 代码”,可能在解释型语言方面用的不多吧。
USDT 有很大的局限,就是只能使用 Python 解释器定义的几种 probes, 目前能做到的基本上是看看解释器正在干嘛,而不能看到一些具体的变量的参数,解释器的状态等等。如果要做到更加精细的动态追踪,目前有两个想法:
- 用 uprobe 去追踪 Python 解释器。不过大部分都是
PyObject指针,需要了解解释器的工作原理,比较复杂; - 自定义更多的 USDT。通过 python-stapsdt 这个库可以在 Python 程序中插入更多的 USDT marker。但是我觉得意义也不大:我们要解决的问题,往往是不知道问题出在哪里了,你要解决问题的时候,又不能停止程序,再想起来要插入 marker,就晚了。换句话将,既然知道一个地方可能会出问题,可观测行非常重要,那么为什么不直接打印日志呢?