本文所谈到的过载,容易和雪崩混淆。雪崩指的是在分布式系统中,某一个依赖无法正常提供服务,但是系统无法屏蔽掉这个依赖,最终导致整个系统都无法提供服务了。
过载指的是某一个服务所收到的请求量原大于它能处理的请求。
所以后续的讨论使用过载这个词,虽然有的时候我们在讨论相同的问题,但是用的是“雪崩”这个词。
对于过载,似乎有一个很简单的解决方法:现在很多系统的设计都已经考虑好限流了。即,假如某一个系统能处理的 QPS 是 1000,那么它只会同时允许 1000 个请求进入处理,当第 1001 个请求来的时候,会迅速得到错误,直接返回。这样保护系统总是可以成功处理 1000 个请求的。
这就是 Rate limit, 一个典型的 overload protector. Rate limit 有很多实现的方法:Token bucket, Leaky bucket, 等等。
然而这样就足够了吗?
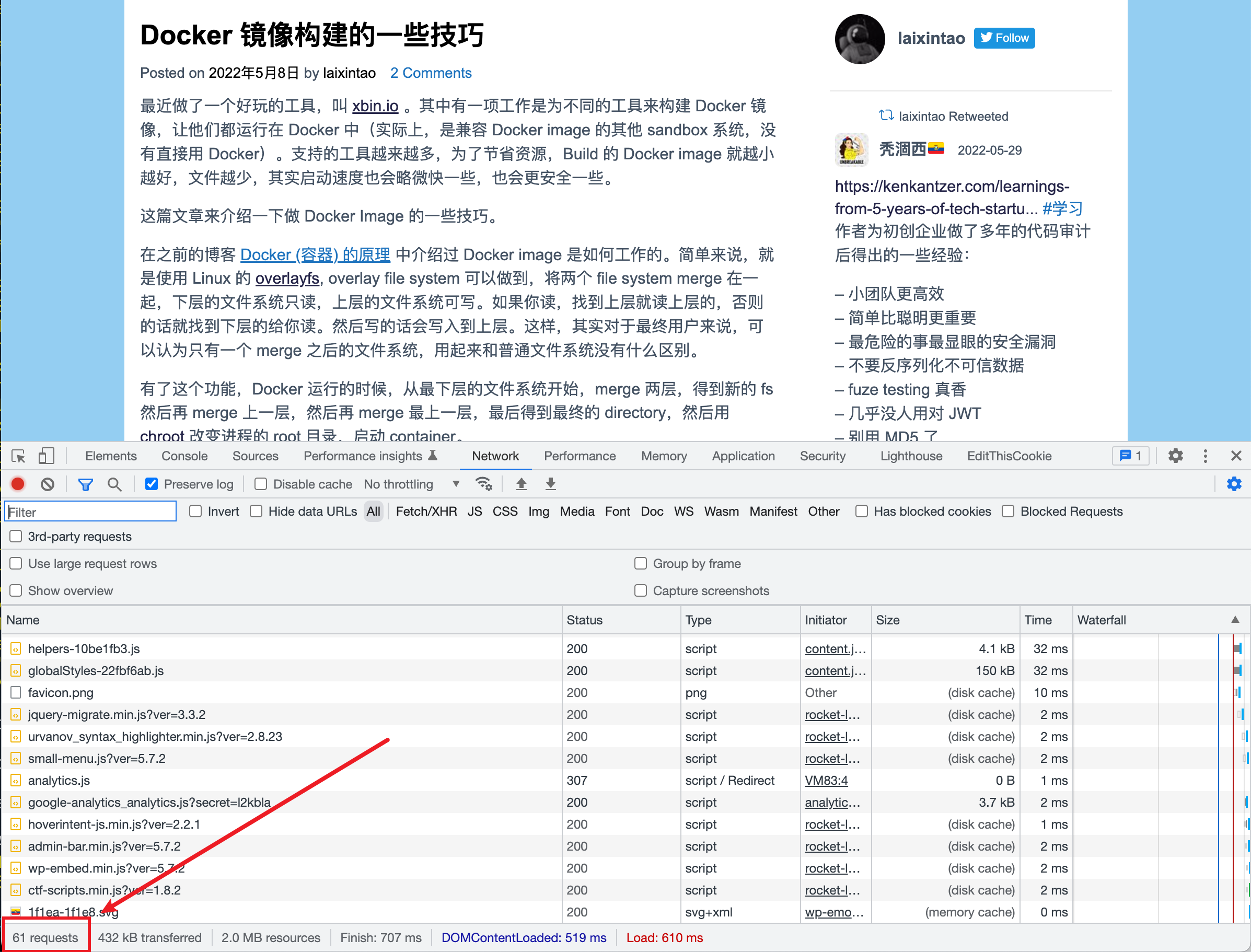
想象这样一种情况:有一个网站(比如您当前正在阅读的这个博客),所能够处理的 HTTP 请求是 1k/s. 但是目前有 1万 个访客正在访问,然后触发了网关(比如说是 Nginx)的限流机制,对于每秒钟第 1000 个之后的请求都直接访问 429 Too many requests.
这样的话,网站本身每秒都在处理 1000 个请求,看起来是在正常工作的,但是对于终端的用户来说呢?他们能正常浏览网页吗?答案是不能的。因为,拿博客的首页来说,一共要发送 61 个 HTTP 请求才能正常显示。也就是说,每一个用户都需要成功拿到 61 个 HTTP 的响应才能看到一个完整的网页,否则,可能缺失一些 css 文件导致网站的格式显示不正确;或者缺失了某些图片导致不知道内容在说的什么;或者无法请求某些 js 导致部分功能缺失。为了看到完整的网页,他们可能重新刷新网页,进一步加剧了当前网站承受的总流量。
再考虑这样一种情况。在一个微服务的系统中,为了展示一个商品的详细信息,“商品微服务” 需要调用3次“用户微服务”,目的分别是:
- 拿到用户所在的地区,用来计算运费;
- 拿到用户的会员等级,渲染优惠;
- 拿到用户当前账户中的积分信息,渲染出来如果使用积分的话可以优惠多少钱;
假如“用户微服务”过载的话,用户微服务对于所有的请求来源进行限流,那么现在这三个请求每一个都可能失败,每一个失败了都无法成功渲染出来商品详细信息。
还有一种情况。假设某一个服务发现系统使用 Etcd 这种带 lease 的数据库作为后端依赖。一个服务注册上之后,需要不断 renew lease, 才能保持在线上。如果它挂了,不再 renew lease,那么当 lease 过期之后,Etcd 就会将其从数据库中删除掉。
某一天,这个系统重启了,所有的服务都开始重新注册自己,请求量太大导致 Etcd 过载了。为了保护自己,Etcd 也有 Rate limit 机制,它只允许 3000 个请求同时处理,对于第 3001 个请求也会直接返回错误。这时候,有一些服务能够注册成功, 但是后续的 renew lease (keepalive) 请求可能失败。这样,即使 Etcd 能够成功处理 3000 个注册请求,但是这些注册功能的服务因为 keepalive 请求无法被接受,所以不得不重新注册自己。就会导致 Etcd 一直处于一种 overload 的状态,永远无法恢复。
以上几种情况,都是在有 Rate limiter 的情况下,系统依然会被 overload。
Overload 的时候,总请求量是比容量要大的,那么我们的解决思路就是,要保证总请求量随时间不断减少,最终,总请求量在能够处理的容量之内。虽然有些请求可能失败,但是他们最终的重试是会成功的。换句话说,要保证我们处理的请求都是“有效的”请求。
举一个反例:网站使用队列来缓存住超过容量限制的 HTTP 请求,然后不断从队列中取出来请求处理。这之所以是一个糟糕的方案,是因为在 HTTP 的场景中,如果一个用户打不开网页,那么他会刷新而不是等在这里。所以网站服务器从队列中拿出来的请求总是用户已经放弃的请求,那么一直在处理“无效”的请求了。
一些可以考虑的思路如下。
按照上下文进行限流
当过载的时候,我们要保证依然在容量限制内的数量的用户是可以正常服务的。但是不能单纯的从请求的角度来进行限流。而是应该加入业务上下的维度。比如:
- 假如一个用户打开了某一个页面,要保证后续的操作都是成功的,至少可以完成一次交易;假如某一个用户已经被 rate limiter 失败了,那么这个用户的请求我们都让它失败掉,不要再处理他的请求浪费资源了;
- 或者按照用户 id 进行 sharding,只保护某一部分用户;过一段时间保护另一部分用户;
原子化调用
在上文中第二个例子中,可以考虑将三次请求变成一次请求。这样按照请求维度的限流依然是有效的。
切换成异步链路
对于某些情况,可以考虑使用上面的“反例”。比如说用户的付款请求,如果遇到了失败,那么用户很可能放弃这笔交易。我们可以考虑使用队列来让付款请求排队,尽可能让付款请求有更大的能够成功处理的机会:
- 显示明确的处理中的字样,尽量给与用户安抚;
- 如果用户尝试取消,弹出确认提示可以取消付款,交易尚未发生,但是鼓励继续等待;
- 对于信用好的用户,或者单价低的订单,考虑先推进交易,异步从账户中扣款;
临时的降级(断路)
在雪崩的情况下能够有应急的方式临时屏蔽掉一些消耗资源的特性。
比如在上述 Etcd 的场景中,我们可以考虑,当服务首次注册成功的时候,将 lease 的时间设置为 20min,在第15min 的时候开始尝试 renew,如果失败,以指数级的时间退避重试。如果重试的次数比较少就成功 renew 了,就将 lease 的时间设置为 10min;下一次再缩短 lease,直到 lease 是一个足够短,满足服务健康检查的时间。这样可以在短期内给与 Etcd 足够的时间去恢复,保证它当前正在处理的请求都是最终的要求(指的是,把服务注册上去是第一要务,健康检查踢掉异常服务是次要任务,可以暂时降级)。
Pingback: 系统的过载(Overload)以及处理思路 – 爱读书网
说到 ETCD 的限流和性能问题,勾起了我被 Sigma 坑的痛苦回忆。
但凡实时计算稍微凶狠点,同时多申请了一些任务 Pods,Sigma 就立马罢工了。
当然 PR 稿永远都是世界最强 K8S 集群。
哈哈。我们现在内部系统也是,我现在就被坑的很痛苦。
现在很多系统开始弄自己的 Raft,也算是对 ZooKeeper 和 ETCD 的一种有声控诉