最近写了一个小工具,用处是可以将数据库的备份文件上传到 S3 上面去。学到了一些很有意思的东西,觉得值得记录一下。
工具的源代码:https://github.com/laixintao/mydumper2s3
备份数据库的方法
最简单的方法,只要将数据库 dump 出来,然后上传到 S3 即可。
但是全量 dump 出来数据库占用磁盘的空间较大,并且上传完之后一般都删掉了。有一种可以不浪费本地磁盘的空间的方法,之前在博客《用 ssh 传输文件》中介绍过。我们可以用管道将 dump 的进程和上传的进程连接起来,这样就不需要本地的磁盘了。
类似这样的方法:
|
1 |
mysqldump database | gzip | aws s3 cp - s3://bucket/aws-test.tar.gz |
MySQL 自带的 mysqldump 命令是支持将数据库 dump 到 stdout 的,然后我们使用 aws s3 的 cp 命令,将源文件设置为 stdin,中间加了一个 gzip 做压缩上传。因为 SQL 文本压缩空间很大。
使用 mydumper 的问题…
mydumper 是一个第三方的开源 dump 工具(只有 3k 行 C 语言代码)。做的事情其实和原生的 mysqldump 差不多,但是有几点好处(引用 Readme):Parallelism, Easier to manage output, Consistency, Manageability. 在我看来,最重要的是 Parallelism,它比原生的 mysqldump 要快很多,(猜想)这个速度快是用了很多黑魔法来实现的,比如采用了多线程同时写入多个文件的方式,因为多线程 dump,并不支持输出到 stdout,因为每一个线程都需要一个 fd 来写入(还是我的猜想)。在不修改 Mydumper 的代码的情况下,直接使用 Unix pipe 是不可行的。
所以,要是使用 mydumper 的话,我想到了以下几种方法。
1. 将 S3 挂载到系统上,作为一个文件系统
考虑使用 https://github.com/s3fs-fuse/s3fs-fuse 将 S3 直接挂载到操作系统上,这样 mydumper 并不知道自己在往网络上上传,fuse 封装出来一套 POSIX API,不是完全兼容的,还不知道够不够 mydumper 用,但是感觉问题不大。
这里的问题是,每次文件创建,每一次写入,都是通过网络做的,网络不稳定可能会有问题。也不知道问题会多大,我还没时间测试。
2. 黑魔法,使用 LD_PRELOAD 直接覆盖 write_data
链接的时候可以提前 load 我们定义好的函数,来覆盖 mydumper 的函数。(相当于 Python 的 mock.patch 功能)
比如写一个这样的函数:
|
1 2 3 |
int rand(){ return 42; //the most random number in the universe } |
然后定义环境变量:
|
1 2 |
gcc -shared -fPIC unrandom.c -o unrandom.so export LD_PRELOAD=unrandom.so |
这样在运行程序的时候,随机数得到的就永远是 42 了。
看了下 mydumper 的源代码,只有3k+行 clang,考虑可以使用 ld_preload 直接将他的 write_data (以及打开文件相关的操作)直接覆盖(考虑使用golang,比较好些),将实现直接替换成写 s3。
这样相当于不需要本地磁盘就可以上传了。
参考:https://jvns.ca/blog/2014/11/27/ld-preload-is-super-fun-and-easy/
3. 两个进程,一边 dump 一边上传
这个思路比较朴素,就是 mydumper 只管普通的上传,而另一个进程(我们就叫它 mydumper2s3 吧),只管上传,然后上传文件完成之后,就将上传完成的删掉。
这样,只要上传的速度比 dump 的速度快,就依然还是可以继续的。就怕磁盘空间不够,上传的速度又比 dump 的速度慢,就悲剧了。
这个问题我一开始纠结了很多,最后发现应该也不是什么大问题。以为:
- 看了一下 S3 的技术规格,如果在同一个局域网内,速度是 GB 级别的,而 mydumper 是几十M1秒;
- Mydumper 支持
--compress,自带压缩功能,那实际的写入速度又要慢上一些; - 实在不行,可以用 systemd/ionice 这种工具对 mydumper 的进程限速;
所以就不去考虑这个问题了。
有趣的是,我去翻 mydumper 的 issue,发现竟然有人抱怨在磁盘慢的时候 iohang 住,而不是报错(issue)。不过作者回复说这样挺好的啊,这样不就给你时间释放磁盘空间了吗:)
我也想要这样的 T T
实现细节
在 mydumper 还在写入文件的时候上传,需要注意,正在被打开并写入的文件先不要上传,等文件被关闭之后在开始上传。所以需要维护 4 个文件列表:
- 当前 dir 下的所有文件;
- 正在被打开的文件;
- 正在被上传的文件;
- 已上传的逻辑;
然后每隔 1s 扫描一次文件夹,将 “当前 dir 下的所有文件” 中,没有被打开、没有被上传、没有已上传的文件,加入到上传队列中。其中要注意好多线程之间的逻辑,至少需要一个定时扫描的 watcher 线程,然后需要一个上传的线程池(注意连接池的大小不要小于线程池的大小)。比如我写的一个 bug 是这样的,将这些文件加入到上传队列,但是没有立即更新到 “正在被上传的文件”中,而是线程池真正开始上传的时候才更新。这样就导致下一秒扫到的时候认为这些正在队列中的文件还没有上传,又入了一次队列,导致文件被重复上传了非常多次。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
+-----------+ | mydumper | +-----+-----+ | | v +-----+------+ upload +-------------+ +------+ | local disk +----------> mydumper2s3 +------> s3 | | <----------+ | |bucket| +------------+ delete +-------------+ +------+ after upload |
一开始我是想用 inotify 这种接口去监听文件变化的,最后变成了定时扫描(扫描间隔是可以用命令行参数 --interval 控制的),是考虑到下几点:
- inotify 只能在 Linux 系统工作,不同的操作系统,文件变化的事件不同;
- 实现太复杂,需要3个线程,监听创建 + 监听关闭 + 上传线程,这些线程之间需要通讯;
- 需要处理一些临时文件的变化,比如
metadata.partial最后 dump 完会被重命名成metadata;
最后实现的效果如下:
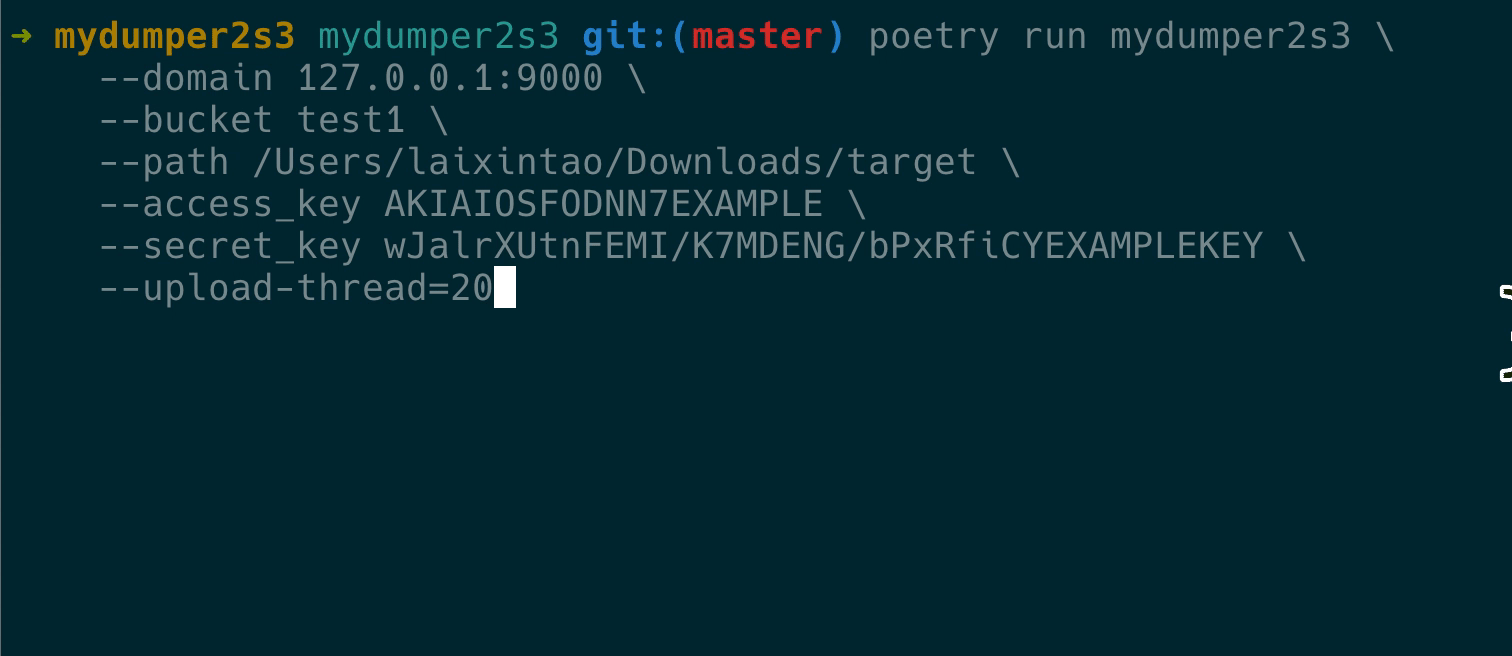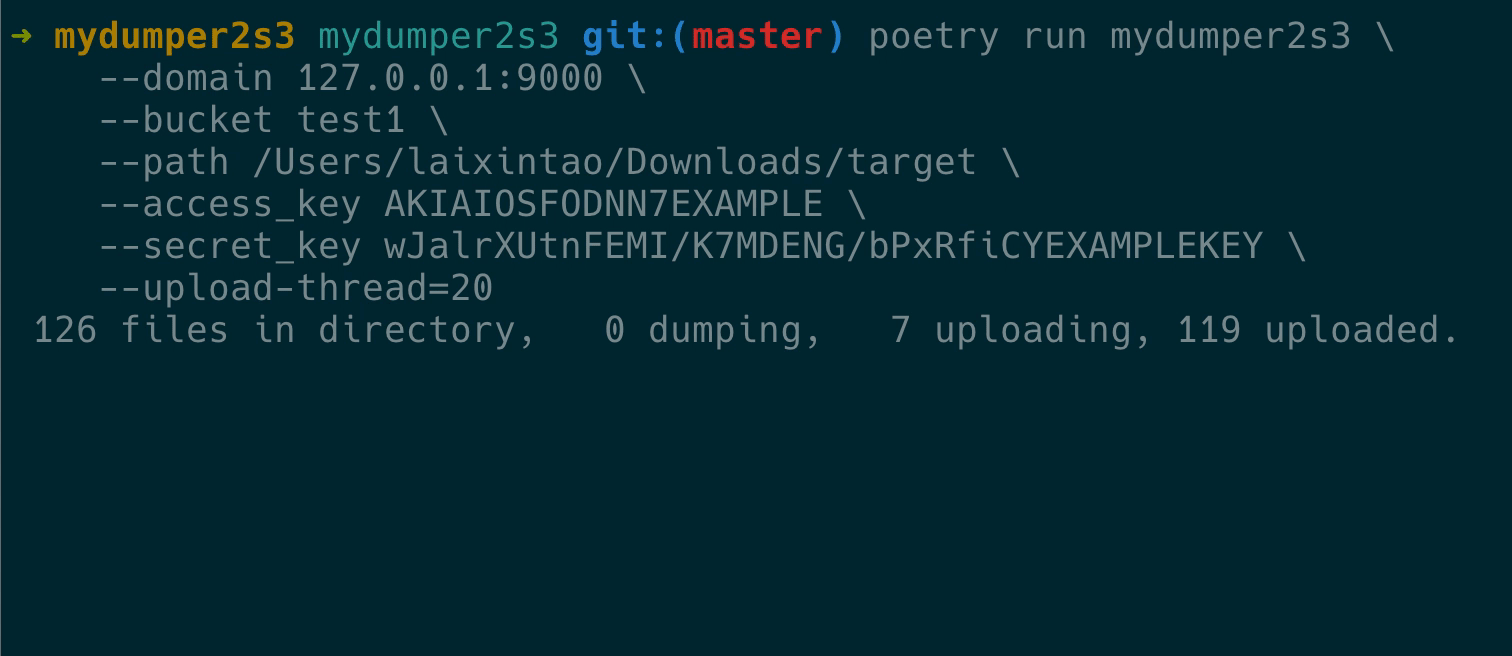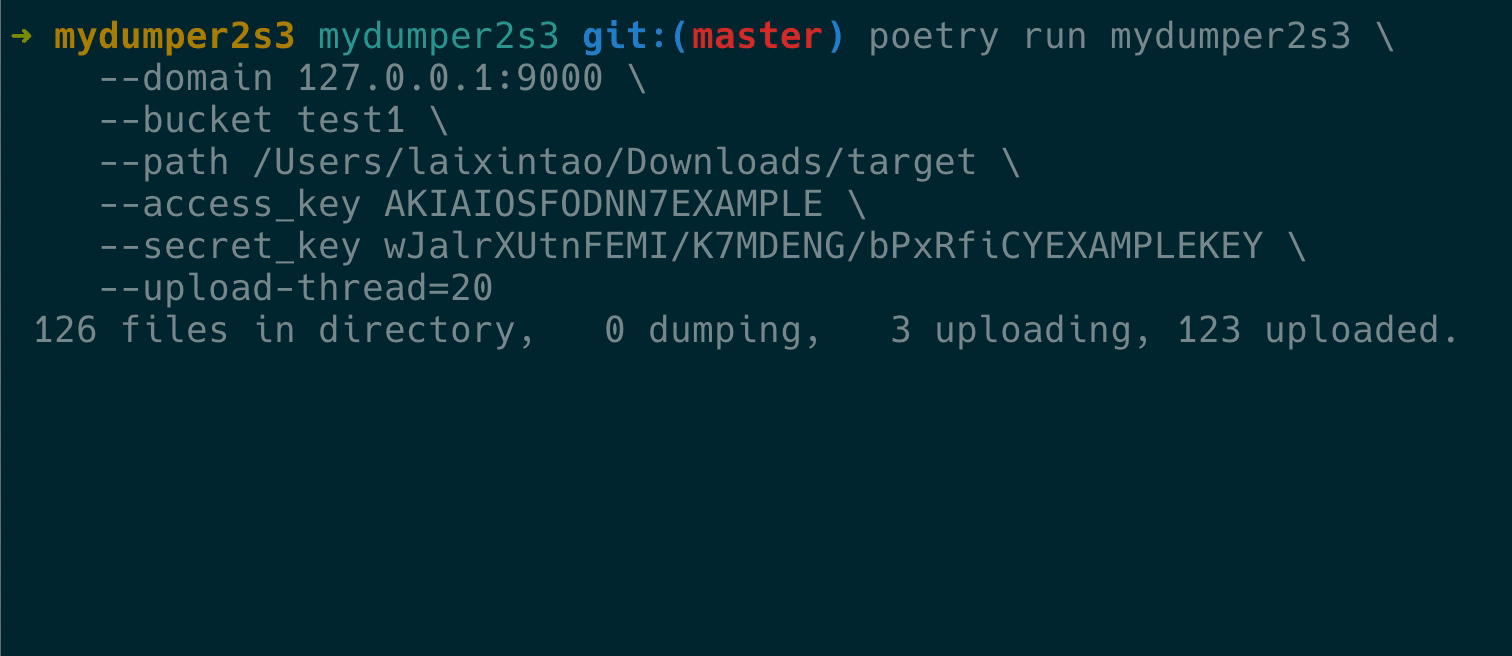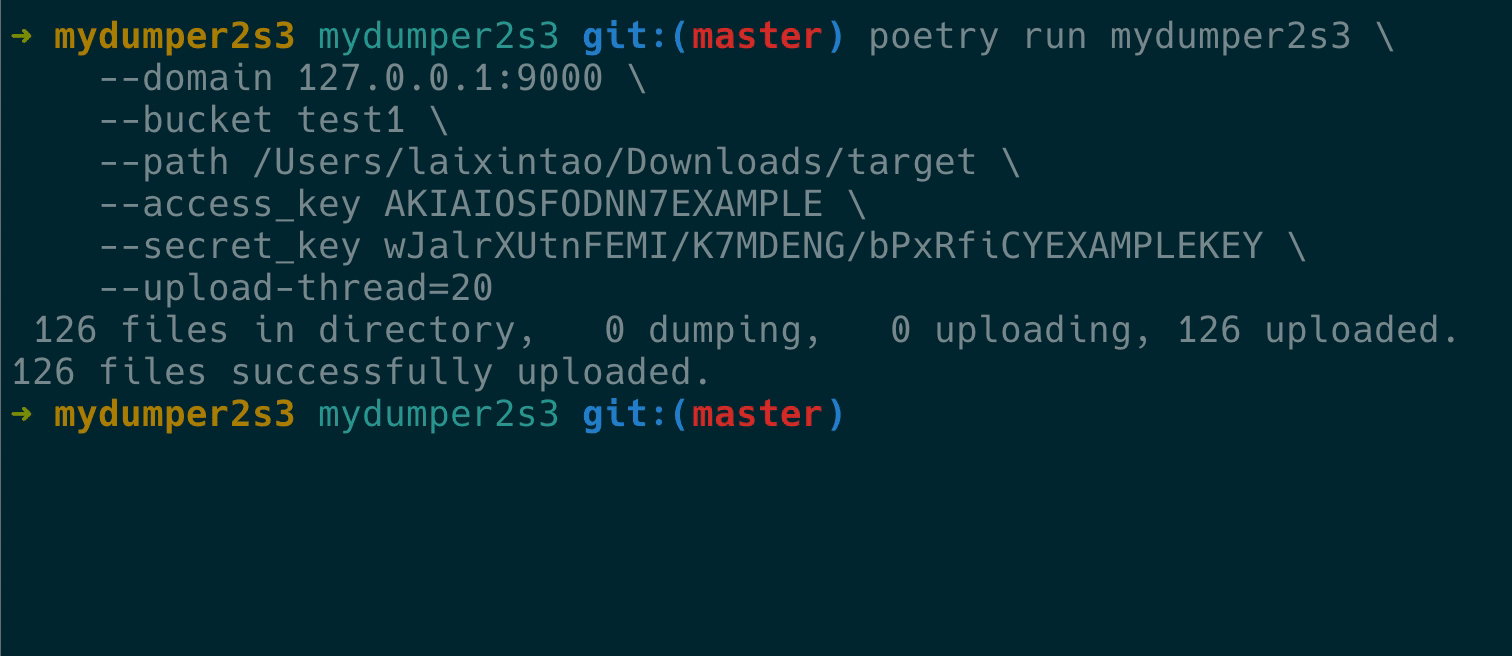
验证备份文件
还写了一个工具可以校验上传文件的 md5.
有个有意思的地方,如果文件太大(超过5M?),S3 的 SDK 在上传的时候会使用 multipart 上传,如果是multipart上传的,s3上面的 e-tag 不是整个文件的md5,是每段的md5合起来再md5. 这样校验就非常复杂。
我发现了这个神奇的bash,按照s3的逻辑在本地文件切段,然后计算hash:https://gist.github.com/emersonf/7413337 (from: https://www.savjee.be/2015/10/Verifying-Amazon-S3-multi-part-uploads-with-ETag-hash/)。
最后,这个工具的源代码在这里:https://github.com/laixintao/mydumper2s3
2021年10月29日更新:
今天发现 mydumper 已经实现 --stream 的feature了,作者到我的 Repo 留言说下个版本会支持。
目前还没release。所以我去看了它的代码,看这个实现比较简单。原来的逻辑都没有改,只是会在 mydumper 进程内新开一个线程将 dump 好的文件输出到 stdout 然后删除。这样还是用的多线程 dump。这样,我们就可以使用其他工具直接从 stdout 读出来然后上传了。不过读的时候要注意去解析 mydumper 的输出,比如它是每次先写 stdout 一个 \n -- 4个字符,然后写文件名字,然后文件内容。