很久之前看过一篇有关Python的list的博客,里面提到,Python中list的数据结构是这样的:
|
1 2 3 4 5 |
typedef struct { PyObject_VAR_HEAD PyObject **ob_item; Py_ssize_t allocated; } PyListObject; |
我很不理解的是,list完全可以存储×ob_item就可以了啊,为什么要存放××ob_item呢?
只要list的每一个元素存放的是指向PyObject的指针,就已经可以实现增删改查了,维护一些指向PyObject的指针就可以了,而且指针只有一层,还比“指向指针的指针”更快一些。百思不得其解,去stackoverflow上面提问,有个人回答,这样的话,如果要修改list的值,只要将指针指向另一个“指向PyObject的指针”就可以了。但是我觉得,即使是存一层指针,repoint也不是很麻烦。
后来自己就想了很长时间,跟朋友吃饭讨论过,跟张哥也讨论过。
昨天晚上,我感觉自己有点理解了。
首先,PyObject肯定是不能拿来用的,因为这就是文件系统的blob一样,我们用的是指向它的node,看他的文件块没有意义。所以一般来说,我们用的是×PyObject来操作Python对象。换句话说,我们基本上不会去直接搞PyObject,×PyObject一般是我们能获得PyObject的唯一方式。那么如果在list里面存放一层指针,即×PyObject的话,就差不多是复制这个对象进去了(虽然存放的也是指针)。参考下图:
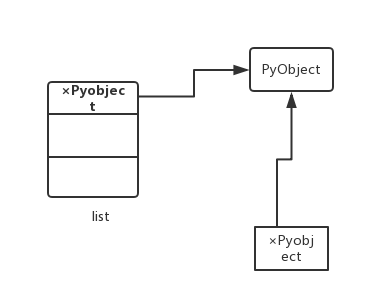
这个时候,如果从list的索引改了PyObject,那么×PyObject也会受影响,是指向了同一个对象(这个地方和××PyObject)是一样的。但是考虑这样一种情况:
|
1 2 3 4 5 6 7 8 |
class Person: def __init__(self, name): self.name = name tom = Person('tom') li = [] li.append(tom) tom = Person('lisa') |
假如是我想象的list存放的是×PyObject的话,我们将tom添加到list之后,重新给tom赋值了一个对象,也就是说,tom指向了另一个对象。但是li中的tom是直接指向一个对象的。也就是说,tom的repoint就和li中的tom关联不到了。
可能说的有点绕,和指针相关就比较麻烦,简单来说,就是:如果list存放的是×PyObject,那么变量重新指向别的对象的话,list存放的变量还是指向原来的对象,我们无法通过引用给list中的元素重新指向了(只能通过list的索引重新指向)。这就点像软链接和硬链接的区别。
但是如果存放的是××PyObject,那么引用(×PyObject)指向的什么,数组里面就存放的什么:
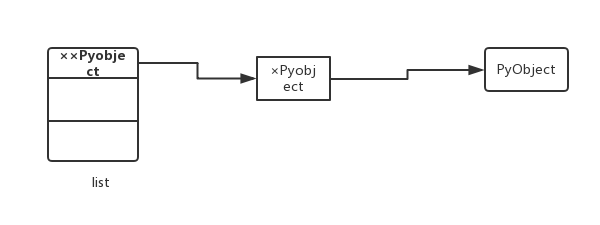
另外,如果list存放×PyObject,那么list的元素改变之后,旧元素很可能没有指针指向它了,很可能被作为垃圾回收。
以上,是我这几天的理解,没有经过验证,很可能都是错误的。