一天工作日,你拿着刚买的咖啡来到了办公室,准备开始做计划好的工作,度过本该是平平无奇的一天,直到——一位用户发过来消息说他们有新的机器上线之后,所有的 TCP 连接都自带3.5s左右的延迟!他们的服务在使用新的服务器之后,延迟都上升了 3.5s!
经过他们自己的 debug,他们发现,延迟增加之后,在 TCP 连接建立之后,有3.5s 的时间没有发送数据,之后,网络就正常了!然后我们知道,不光服务器是新的,机架,网络设备,都是新的。这批服务器本不该你来负责,但是这个现象也太怪了!所有人都知道你是公司里的网络专家,如果有有解决不了的网络问题,就会来找你。
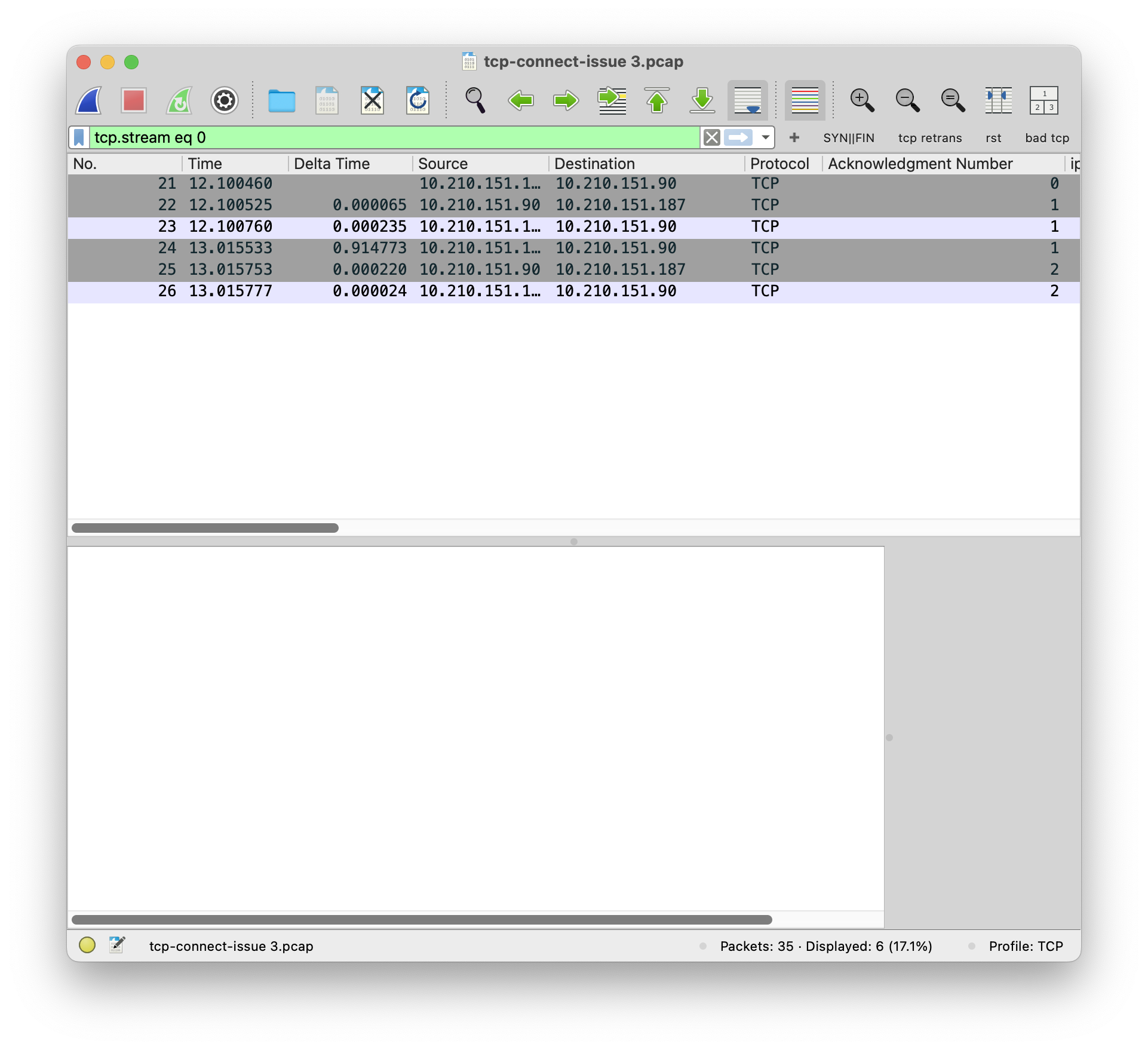
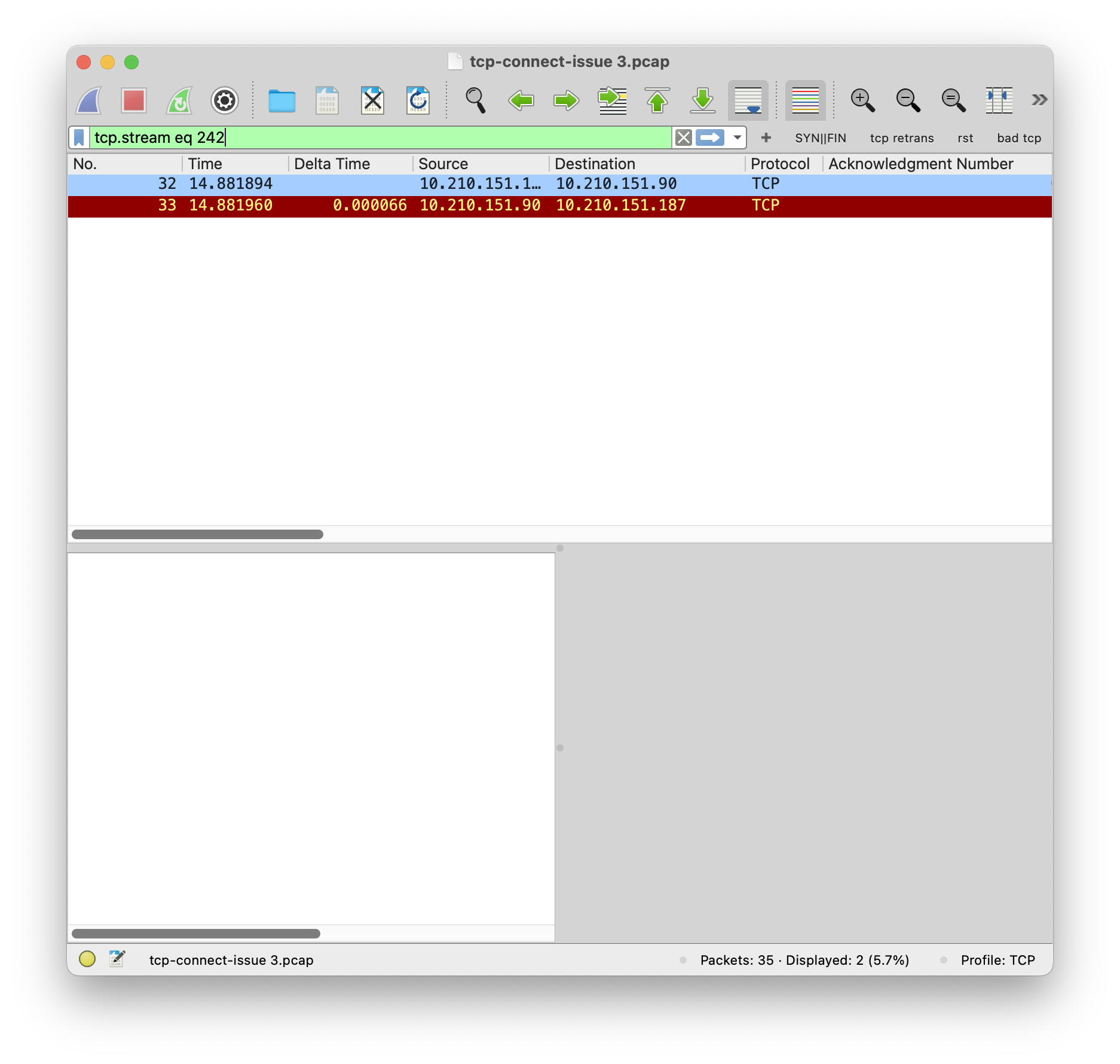
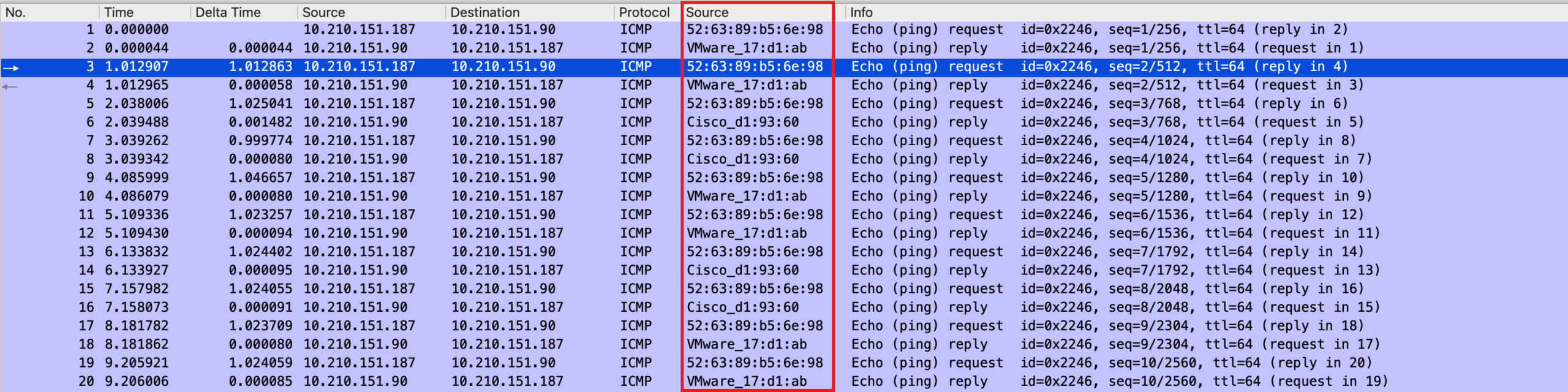
你让用户用 iperf 测试一下带宽1,用户测试了一下,结果如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
$ iperf3 -c 10.0.2.2 -b 10M Connecting to host 10.0.2.2, port 5201 [ 5] local 10.0.1.2 port 45026 connected to 10.0.2.2 port 5201 [ ID] Interval Transfer Bitrate Retr Cwnd [ 5] 0.00-1.00 sec 0.00 Bytes 0.00 bits/sec 2 1.41 KBytes [ 5] 1.00-2.00 sec 0.00 Bytes 0.00 bits/sec 1 1.41 KBytes [ 5] 2.00-3.00 sec 0.00 Bytes 0.00 bits/sec 0 1.41 KBytes [ 5] 3.00-4.00 sec 384 KBytes 3.15 Mbits/sec 24 22.4 KBytes [ 5] 4.00-5.00 sec 5.12 MBytes 43.0 Mbits/sec 0 221 KBytes [ 5] 5.00-6.00 sec 1.75 MBytes 14.7 Mbits/sec 0 328 KBytes [ 5] 6.00-7.00 sec 1.12 MBytes 9.44 Mbits/sec 0 328 KBytes [ 5] 7.00-8.00 sec 1.25 MBytes 10.5 Mbits/sec 0 328 KBytes [ 5] 8.00-9.00 sec 1.12 MBytes 9.44 Mbits/sec 0 328 KBytes [ 5] 9.00-10.00 sec 1.25 MBytes 10.5 Mbits/sec 0 328 KBytes - - - - - - - - - - - - - - - - - - - - - - - - - [ ID] Interval Transfer Bitrate Retr [ 5] 0.00-10.00 sec 12.0 MBytes 10.1 Mbits/sec 27 sender [ 5] 0.00-10.02 sec 12.0 MBytes 10.0 Mbits/sec receiver iperf Done. |
还真是和用户说的一样!
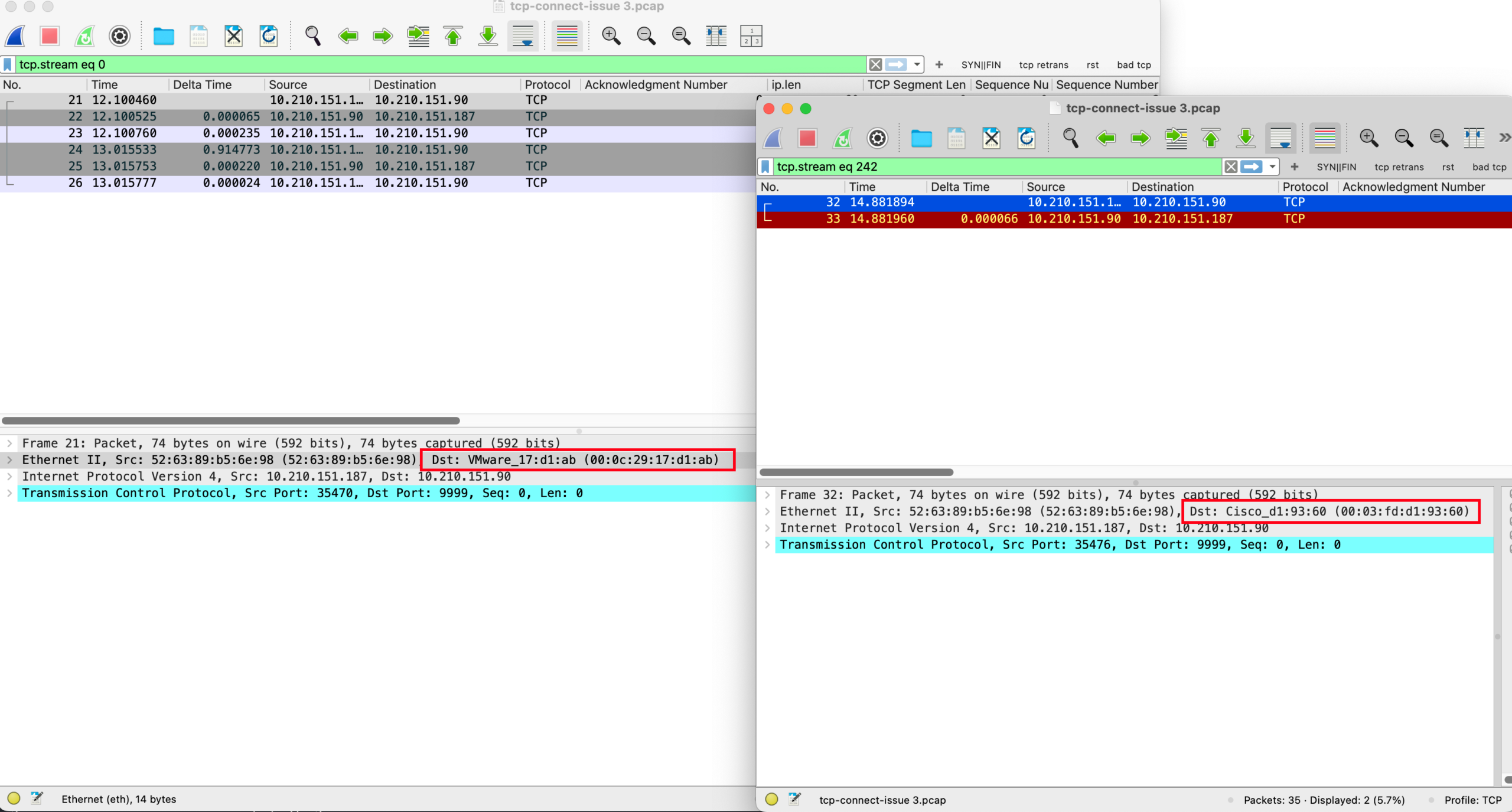
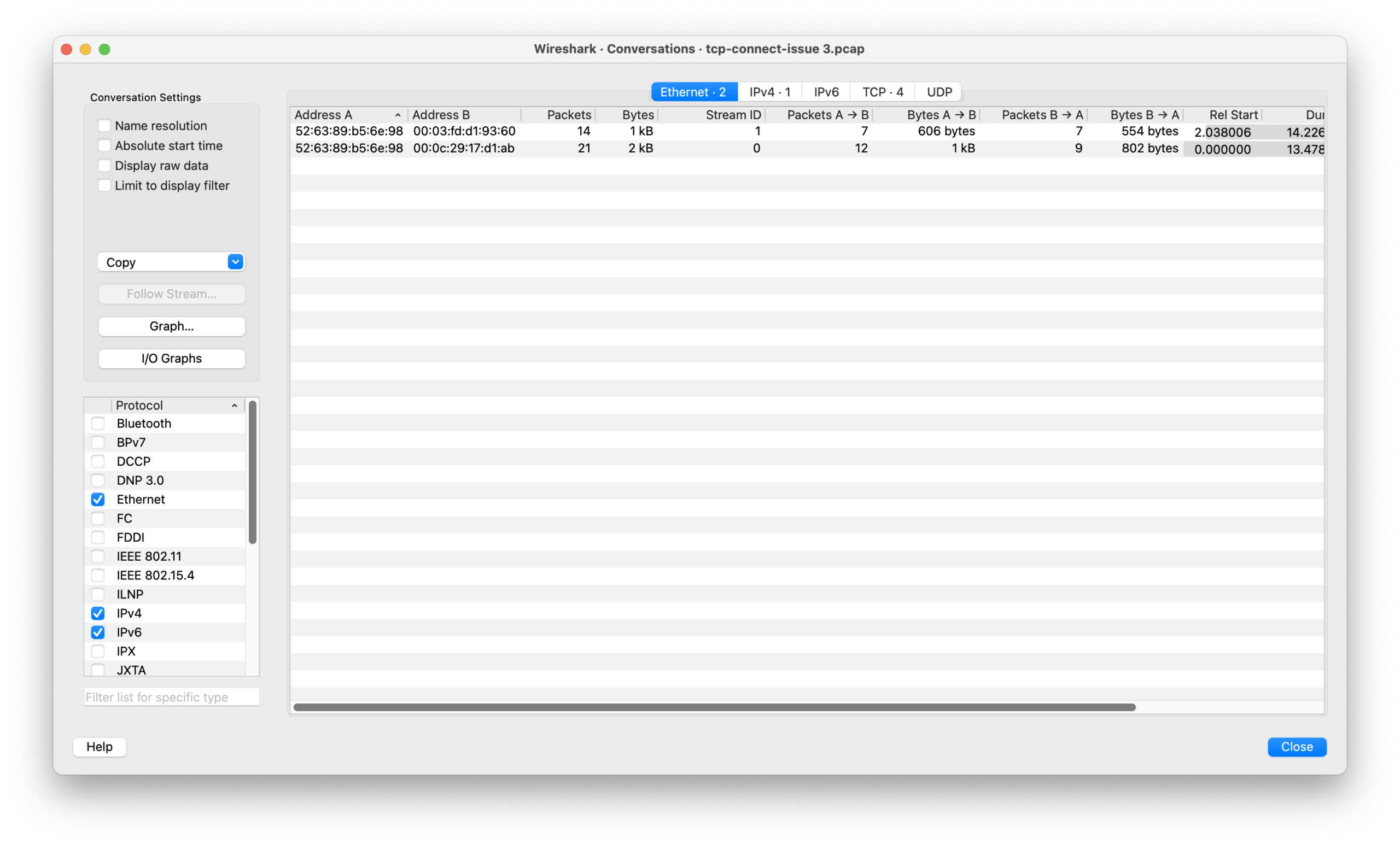
这必须要抓包一下才知道原因了!用户又做了一次 iperf,并且同时执行 tcpdump 进行抓包,过一会儿,就发来了抓包文件。
你看了一会,然后马上就发现了不对劲的地方……
请分析这个抓包文件,找出固定3.5s延迟的问题在哪里。
==抓包破案录==
这篇文章是抓包破案录系列文章(之前叫做《计算机网络实用技术》,后来改名了)中的一篇,这个系列正在连载中,我计划用这个系列的文章来分享一些网络抓包分析的实用技术。这些文章都是总结了我的工作经历中遇到的问题,经过精心构造和编写,每个文件附带抓包文件,通过实战来学习网络抓包与分析。
如果本文对您有帮助,欢迎扫博客右侧二维码打赏支持,正是订阅者的支持,让我公开写这个系列成为可能,感谢!
如果您正在阅读的是题目类的文章,这个目录内容正好用来隔离其他读者的评论。读完题目可以稍作暂停,进行思考,继续向下滑动,可能会被其他的读者剧透答案。
没有链接的目录还没有写完,敬请期待……
- 序章
- 抓包技术以及技巧
- 理解网络的分层模型
- 数据是如何路由的
- 网络问题排查的思路和技巧
- 不可以用路由器?(答案和解析)
- 网工闯了什么祸?(答案和解析,阅读加餐!)
- 重新认识 TCP 的握手和挥手(答案和解析)
- 3.5 秒初始延迟问题 (答案和解析)
- 网络断断续续…… (答案和解析)
- 延迟增加了多少?(答案和解析)
- 压测的时候 QPS 为什么上不去?(答案和解析)
- TCP 下载速度为什么这么慢?(答案和解析)
- 请求为什么超时了?(答案和解析)
- 0.01% 的概率超时问题 (答案和解析)
- 后记:学习网络的一点经验分享
与本博客的其他页面不同,本页面使用 署名-非商业性使用-禁止演绎 4.0 国际 协议。