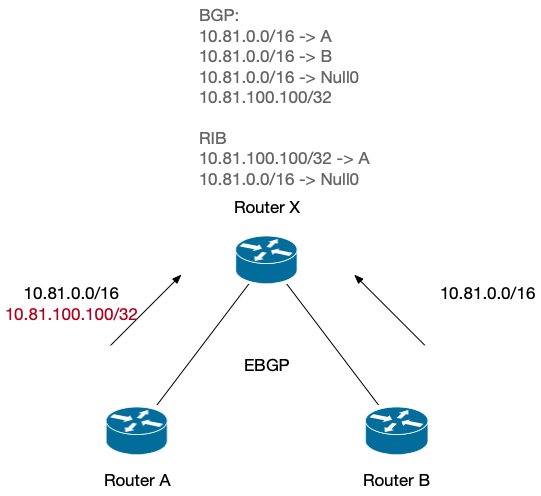
网络系列文章许久不更新了,因为最近的工作比较忙,有很多其他的问题要解决。上个周花了很多时间研究 P2P,(和 web3 区块链无关的),(和民间 P2P 借贷也无关),(和下载盗版电影也无关,好吧,算是有点关系)。而且着实被「云原生」坑了一把,所以这篇文章介绍一下我们要解决什么问题,Spegel 这个项目是什么,怎么解决问题的。最重要的是…… 我会写一下如何从 0 启动并运行这个项目。读者可能会问,这不是按照项目的文档就能跑起来的吗?不是!这项目是云原生的,它居然没有文档,只有一个 Helm Charts1,命令行的参数看的云里雾里,如果不在 K8S 中运行这个程序,就只能结合它的 Charts 以及源代码来弄懂参数的含义。好在我功力深厚,已经完全掌握命令行的启动方式了,接下来就把它传授给读者。
问题
在部署容器的时候,node 要从 image registry 来 pull image。如果要部署的规模非常大,比如 2000 个 container,那么就要 pull 2000 次,这样对 image registry 造成的压力就非常大。
在规模比较大的软件分发问题中,自然而然会想到 P2P 的方式来分发。如果要下载 1000 次,可以先让 10 个节点下载完成,然后后续 100 个节点从这 10 个节点下载,每一个并发是 10,然后其余节点从这 110 个节点下载。这样,每一个节点的最大并发都不会超过 10,就解决了中心点的性能瓶颈问题。
我们尝试过的 P2P 方案是 Dragonfly2, 这个工具以透明代理的方式工作3,透明代理会首先通过 P2P 查找资源,如果找到,优先从 P2P 网络进行下载。下载完成后,会另外保存一份「缓存」,在后续一段时间内(可配置,默认 6 小时,时间越长,文件生效的时间越长,但是占用的磁盘空间越大),会给其他请求下载的节点来 serve 文件。如果整个 P2P 网络都没有目标文件,那么就会回源下载。而且文件支持分段下载,比如一个文件 1G,就可以并行地从 10 个节点分别下载 100M。
透明代理的设计非常好,不光是镜像文件,像 Python 的 pip 下载 tar 包,apt 下载 deb 文件,部署其他的 binary 文件,都可以通过这个 P2P 网络来加速下载。
但是这个设计也有一些弊端,尤其是在镜像下载的场景。
比如进行故障切换的时候,要对目标 IDC 的服务进行扩容,需要同时扩容 100 个服务,那么这 100 个服务都需要请求到镜像中心,因为这 100 个服务都是不同的镜像,P2P 网络中现在没有缓存。或者对一组服务进行紧急扩容的时候,也会因为缓存中没有镜像而全部请求到镜像中心。
在多个数据中心部署的时候,由于无法事先得知一个 IDC 需要部署哪些服务,就得把所有的镜像都同步到这个 IDC,极其浪费带宽。如果不同步的话,那么每次部署都要跨 IDC 来拉取镜像, 延迟比较大。今天部署新的服务,跨 IDC 拉取镜像部署完成。明天一个机器挂了,容器要部署到另一个机器上去,但这时候 P2P 网络中的缓存已经删除了,所以又需要跨 IDC 拉取镜像部署。
以上的问题,按照 dragonfly 的缓存设计,不太好解决。
可能的方案
这个问题的本质,其实是镜像太大了,假设一个服务的镜像只有 10M4,算了,算 100M 吧,那么这些问题都不是问题,1000 个节点全部去镜像中心拉取,也才 10G,跨 IDC 也都能接受。
但是很多人打的 image 什么都往里放,golang 编译器也放进去,gcc 也放进去。甚至做基础镜像的团队也把很多不用的东西都放进去了。导致 image 最终就是 1G 的正常大小,甚至还有 10G 的5。
Image lazy loading
一个很新奇的想法是,既然 image 很多的文件都用不到,那么就只下载用得到的文件,其他的文件等读到的时候再去下载。比如 Nydus6,把 image 进行文件级别的索引和分析,启动的时候只下载必要文件,其他的文件等 access 的时候再通过 P2P 网络下载7。
从 containerd 来 serve
既然 image 在其他部署的机器上已经存在了,那能不能直接从其他的机器来下载呢?
通过 containerd 把已经存在的 image 读出来是可能的8。于是我们就想尝试写一个程序:
- 可以把本地 containerd 的 image 暴露出来;
- 需要下载 image 的时候,优先从其他的机器上直接下载;
- 需要做一个服务发现服务让不同的节点知道 image 的 blob 都存在于哪些机器上。
然后就发现了 Spegel 这个项目9,简直和我们想做的事情一模一样!
Spegel 做了上面的三件事:
- 暴露一个 HTTP 服务可以提供下载本机的 image;
- 对 containerd 做 image mirror,containerd 想要 pull image 的时候,会被 spegel 代理到去其他机器下载;
- 如何发现谁有什么镜像呢?服务发现是用的 P2P 网络,但是并没有用 P2P 来存储数据,本质上,只是用 P2P 来做了服务发现。Spegel 会定期把本地的 image 广播到 P2P 网络中,需要 image 的话,也会从 P2P 网络中寻找 Provider。
运行 Spegel
环境准备
首先需要准备一个 containerd 的运行环境。也可以直接安装 docker。
for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install -y ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "${UBUNTU_CODENAME:-$VERSION_CODENAME}") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin -y
sudo docker run hello-world然后需要安装 golang 用来编译项目的 binary,直接安装 golang 的官方文档进行编译即可。
wget https://go.dev/dl/go1.22.0.linux-amd64.tar.gz
rm -rf /usr/local/go && tar -C /usr/local -xzf go1.22.0.linux-amd64.tar.gz
cat - >> ~/.bashrc << EOF
export PATH=$PATH:/usr/local/go/bin
export GOPATH=~/go
EOF
source ~/.bashrc
go version下载项目进行编译。
git clone https://github.com/spegel-org/spegel.git
cd spegel
git checkout v0.0.28
go mod download
go build main.go -o spegel这里编译的是版本是 v0.0.28,因为最新的版本 v0.0.30 我没成功运行起来,会遇到错误:failed to negotiate security protocol: remote error: tls: bad certificate。有一个 issue 说是因为 IPv4 和 IPv6 dual stack 的问题10,但是尝试关闭 IPv6 也于事无补。
软件的 binary 准备好了,就可以准备运行起来了。
Containerd mirror 配置
Spegel 启动的时候会检查连接的 containerd 是否已经配置自己为 mirror,如果没有配置,会拒绝启动。Containerd registry config path needs to be set for mirror configuration to take effect。
首先配置 CRI 的 config path。
containerd config default > /etc/containerd/config.toml
vim /etc/containerd/config.toml
# 修改如下内容
[plugins."io.containerd.grpc.v1.cri".registry]
config_path = "/etc/containerd/certs.d"然后用 Spegel 提供的配置命令来创建 registry 的 mirror 配置。这个命令只是修改配置文件,你也可以自己修改。
./spegel configuration \
--log-level="INFO" \
--containerd-registry-config-path="/etc/containerd/certs.d" \
--registries https://registry-1.docker.io \
--mirror-registries=http://127.0.0.1:5000 \
--resolve-tags=true其中:
--containerd-registry-config-path:是要写入配置的目录,因为上面配置中 containerd 也是使用了这个目录,所以在这里 Spegel 就要修改这个目录。
--registries:是对什么域名配置 mirror。
--mirror-registries:Spegel 提供 image mirror 服务的地址。这里写什么地址,接下来启动 Spegel 的时候就使用什么地址。
--resolve-tags=true:标记 Spegel 的地址有 resolve tag 的能力。
这个命令执行过后,会看到多了一个文件:/etc/containerd/certs.d/registry-1.docker.io/hosts.toml,内容是:
server = 'https://registry-1.docker.io'
[host.'http://127.0.0.1:5000']启动项目
下一步就可以启动项目了。
启动的命令是:
./spegel registry \
--log-level="DEBUG" \
--mirror-resolve-retries=3 \
--mirror-resolve-timeout="2000ms" \
--registry-addr=:5000 \
--router-addr=172.16.42.21:5001 \
--metrics-addr=:9091 \
--containerd-sock=/run/containerd/containerd.sock \
--containerd-registry-config-path="/etc/containerd/certs.d" \
--bootstrap-kind=http \
--http-bootstrap-addr=172.16.42.21:5002 \
--http-bootstrap-peer=http://172.16.42.22:5002/id \
--resolve-latest-tag=true \
--registries=http://registry-1.docker.io \
--local-addr=172.16.42.22:30021参数的含义如下:
registry表示启动 registry 服务。spegel binary 只支持两个子命令,另一个就是上面用到的configuration;--mirror-resolve-retries表示 Spegel 在解析 image 的时候最多重试几次;--mirror-resolve-timeout表示解析 image 的时候多久会超时;--registry-addr指定 Spegel 在本地提供 image 下载服务的地址,containerd 会从这个地址来下载镜像,如果失败,就 fallback 到镜像中心;--router-addrSpegel 会 listen 这个地址来接收来自 P2P 网络的请求;--metrics-addr这个地址可以访问/metrics以及 golang 的 pprof 文件;--containerd-sockcontainerd 的客户端通过这个 socket 文件访问 containerd,本地已经存在的 image 也是通过这种方式访问到的;--containerd-registry-config-path和上面一样,但是这个值在代码中并没有实际用到;--bootstrap-kind加入一个 P2P 网络,至少需要认识一个已经存在 P2P 网络中的节点,通过已经存在于 P2P 的节点来加入网络。这里是指定发现节点的方式,是 HTTP;--http-bootstrap-addrSpegel 启动之后会 listen 这个地址,提供 HTTP 服务。只有一个 path/id,访问这个 path 会返回自己的 multiaddr11。即,其他节点可以把本 node 的--http-bootstrap-addr来当作 bootstrap http 地址,这个配置是让本节点对其他节点提供服务;--http-bootstrap-peer指定其他节点的--http-bootstrap-addr,来加入 P2P 网络;--resolve-latest-tag是否解析 latest tag,因为 Spegel 本质上是 image 缓存分发,如果 latest 修改了,那么 Spegel 解析到的 latest tag 可能是过时的;--registries对什么镜像地址进行 mirror;--local-addr本机的地址,实际上没有 listen,在代码中只是在获取到其他节点地址的时候,用这个配置项来比较是不是自己,过滤掉自己的地址,(用于有 NAT 等的复杂环境);
启动一个节点之后,再去另一个节点修改一下地址相关的参数,启动,就可以得到一个 2 节点的 Spegel 网络了。
使用 crictl 来测试
好像使用 docker 不会走到 contianerd 的 image 下载逻辑,所以我们下载一个 crictl 直接来操作 containerd。
安装 crictl:
VERSION="v1.30.0" # check latest version in /releases page
curl -L https://github.com/kubernetes-sigs/cri-tools/releases/download/$VERSION/crictl-${VERSION}-linux-amd64.tar.gz --output crictl-${VERSION}-linux-amd64.tar.gz
sudo tar zxvf crictl-$VERSION-linux-amd64.tar.gz -C /usr/local/bin
rm -f crictl-$VERSION-linux-amd64.tar.gz在第一个节点下载:
time crictl -r /run/containerd/containerd.sock pull registry-1.docker.io/library/node:latest耗时 3m 左右。
然后再去另一个节点执行同样的命令,会看到耗时 20s 左右,提升已经很明显了,而且会极大减少镜像中心的压力。
- Spegel 的 Charts:https://github.com/spegel-org/spegel/tree/main/charts/spegel ↩︎
- Dragonfly https://d7y.io/ ↩︎
- 架构图:https://d7y.io/docs/#architecture ↩︎
- 一个 Redis 都几 M 就够了 Build 一个最小的 Redis Docker Image ↩︎
- 这就是去年年终总结说过的问题,如果人人都是高级工程师,那么问题就不存在了 ↩︎
- 项目主页:https://nydus.dev/,也是 dragonfly 的一个项目 ↩︎
- AWS 等云厂商也有类似的技术 Under the hood: Lazy Loading Container Images with Seekable OCI and AWS Fargate | Containers ↩︎
- Containerd API:https://pkg.go.dev/github.com/containerd/[email protected]#Client.ContentStore ↩︎
- 项目代码:https://github.com/spegel-org/spegel,项目主页:https://spegel.dev/ ↩︎
- “could not get peer id” and timeouts since 0.0.29 · Issue #709 · spegel-org/spegel ↩︎
- https://docs.libp2p.io/concepts/introduction/overview/ ↩︎