这是 网络断断续续 一文的答案。
答案是,在同一个子网内,同一个 IP 地址分配到了 2 个不同的设备上。
对于这种时而正常时而异常的「幽灵问题」,在没有思路的时候,可以通过对比的方法来寻找线索。
有的时候 TCP 能够连通,有的时候无法连通。那么正常的 TCP SYN 包和异常的 TCP 包之间肯定是有什么字段是不一样的。当然,也有可能 SYN 包一模一样,问题出在了其他的网络设备上或者 TCP 的另一端。但是既然题目出给读者了,那么问题的根源肯定是隐藏在抓包文件里面。
通过对比来寻找答案
正常的 TCP 连接可以完成 TCP 的握手和挥手。
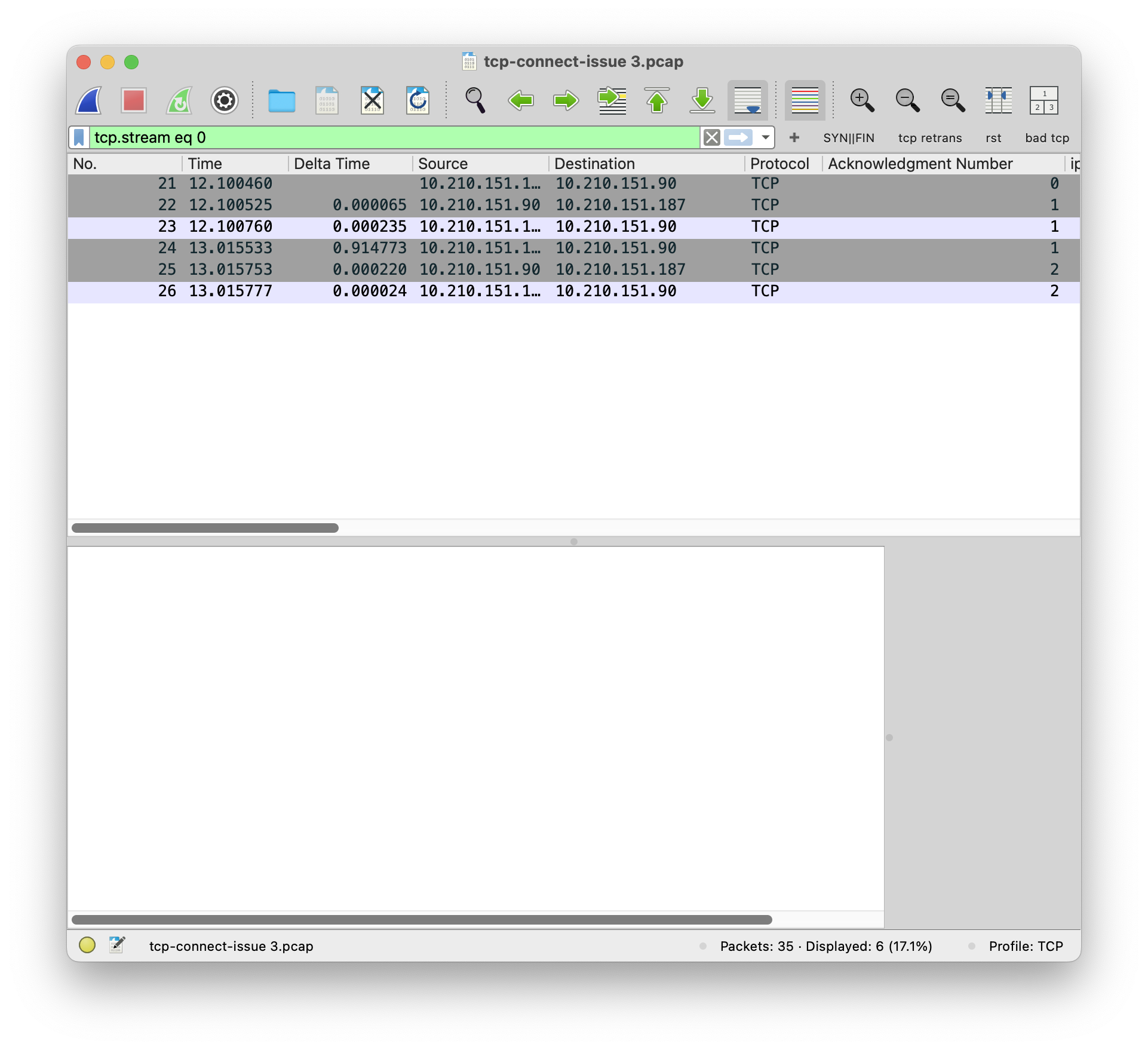
异常的 TCP 连接,发出去的 SYN 直接收到了 RST。
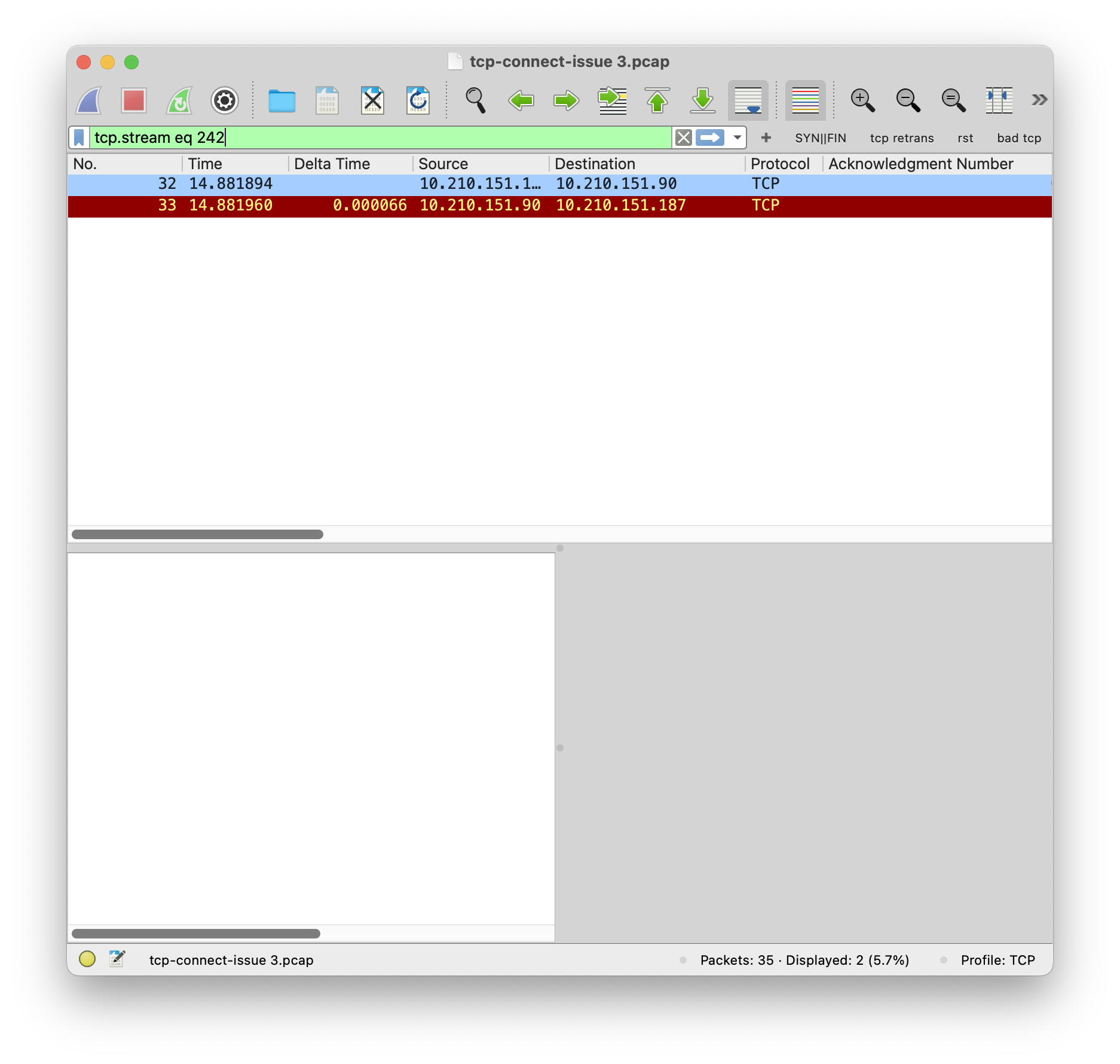
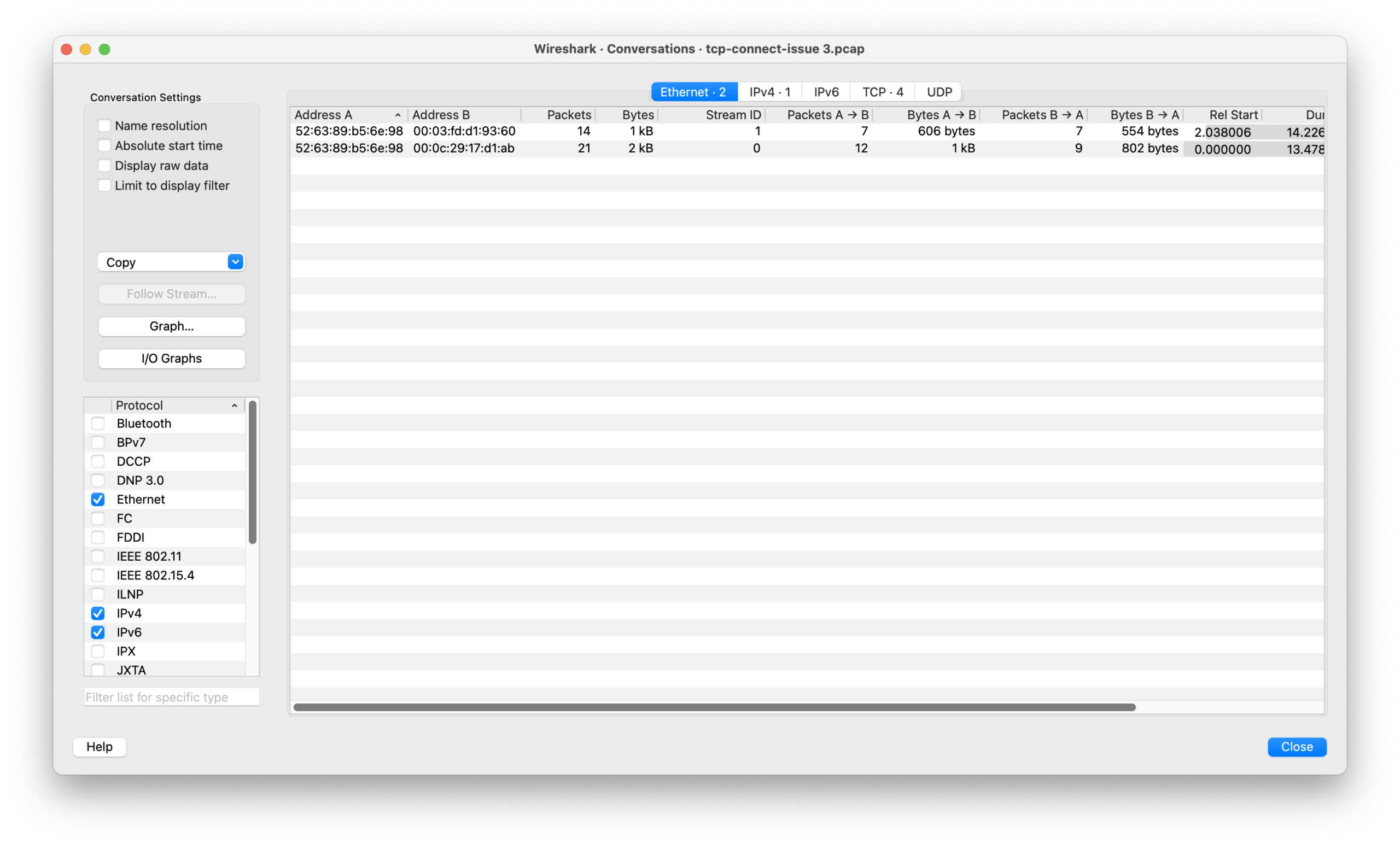
通过对比可以发现,两个 SYN 包的 Dst MAC 是不一样的。
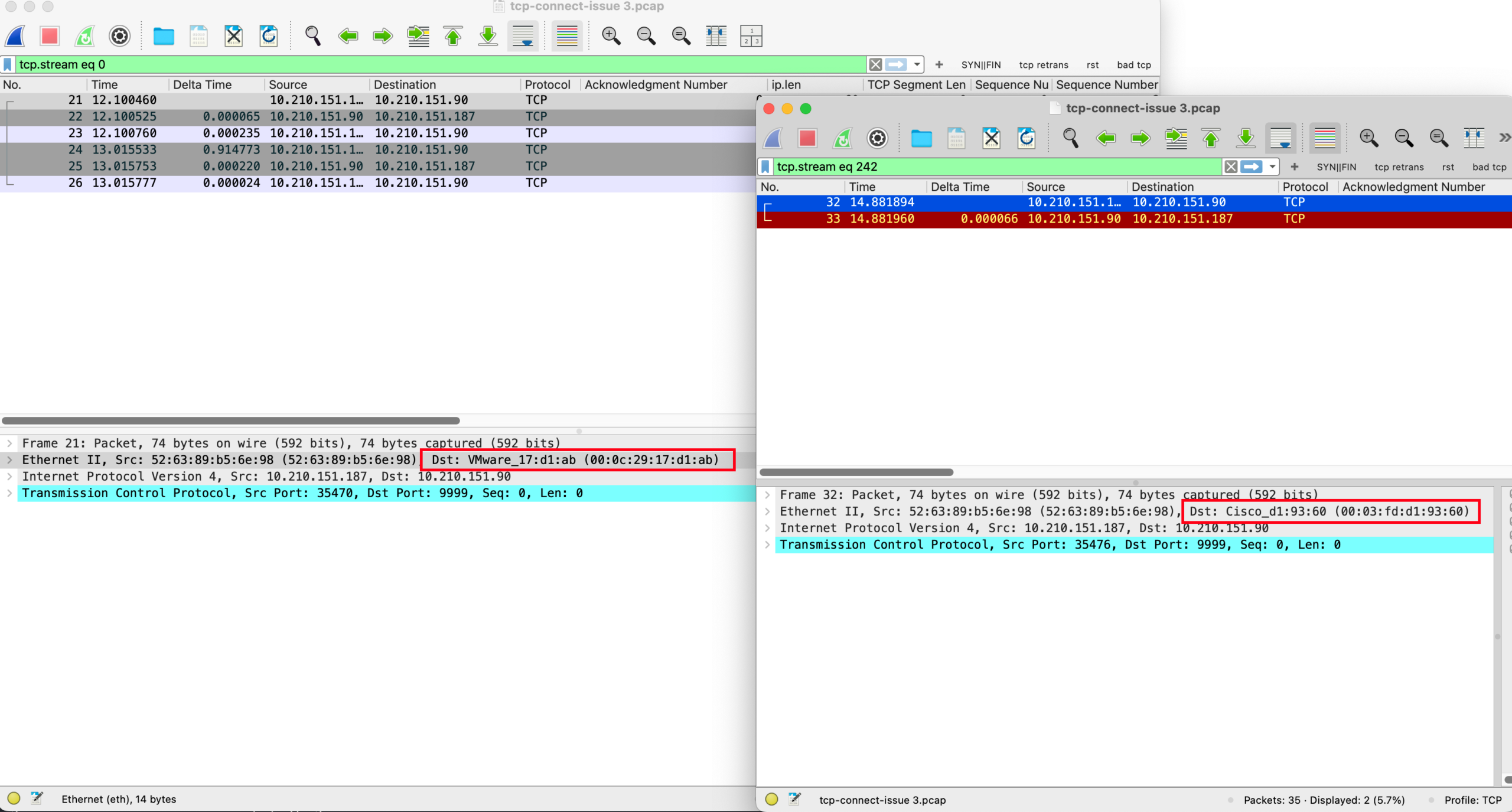
通过推理得出答案
如果不通过对比的方法,顺藤摸瓜,可以用下面的思路。
首先,Src IP 和 Dst IP 分别是 10.210.151.187 和 10.210.151.90,很大概率是属于同一个 /24 子网的 IP,不过要想确认的话需要看下服务器的 IP 地址是如何配置的,子网掩码是不是 /24,这点我们从给出的信息无从得知。
假设确实是属于同一个子网,那么 TCP SYN 包不经过网关,直接发给目的地址,二层的 Dst MAC 地址应该是目的 IP 的 MAC 地址。
假设不属于同一个子网,那么 TCP SYN 包经过网关,TCP SYN 包的目的地址应该是路由器的 MAC 地址。
无论是那种情况,正常情况下发送给同一个 Dst IP 的目的 MAC 应该是唯一且稳定的。通过 Conversation 统计可以看出,通讯的 IP 对只有一对,但是 MAC 的确有 2 对,这是不对的。
原因分析
造成这种现象的原因是,IP 分配重复了,在同一个子网内,同一个 IP 地址 10.210.151.90 被分配给了多个机器。
发送 TCP 包之前,需要知道对应的 Dst IP 地址的 Dst MAC 地址,怎么知道呢?Src 机器会在整个子网内广播 ARP 询问,持有这个 IP 的机器会回复 ARP。现在子网内有两个相同的机器是相同的 IP 地址。这两台机器的 IP 地址一样,MAC 地址不一样。如果我们现在 arping 10.210.151.90 ,会得到如下的回复:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
$ arping -c 3 10.210.151.90 ARPING 10.210.151.90 42 bytes from 5a:65:98:0c:82:02 (10.210.151.90): index=0 time=944.055 usec 42 bytes from c2:10:70:f2:ae:ab (10.210.151.90): index=1 time=997.915 usec 42 bytes from 5a:65:98:0c:82:02 (10.210.151.90): index=2 time=13.799 usec 42 bytes from c2:10:70:f2:ae:ab (10.210.151.90): index=3 time=109.388 usec 42 bytes from 5a:65:98:0c:82:02 (10.210.151.90): index=4 time=6.670 usec 42 bytes from c2:10:70:f2:ae:ab (10.210.151.90): index=5 time=48.983 usec --- 10.210.151.90 statistics --- 3 packets transmitted, 6 packets received, 0% unanswered (3 extra) rtt min/avg/max/std-dev = 0.007/0.353/0.998/0.438 ms |
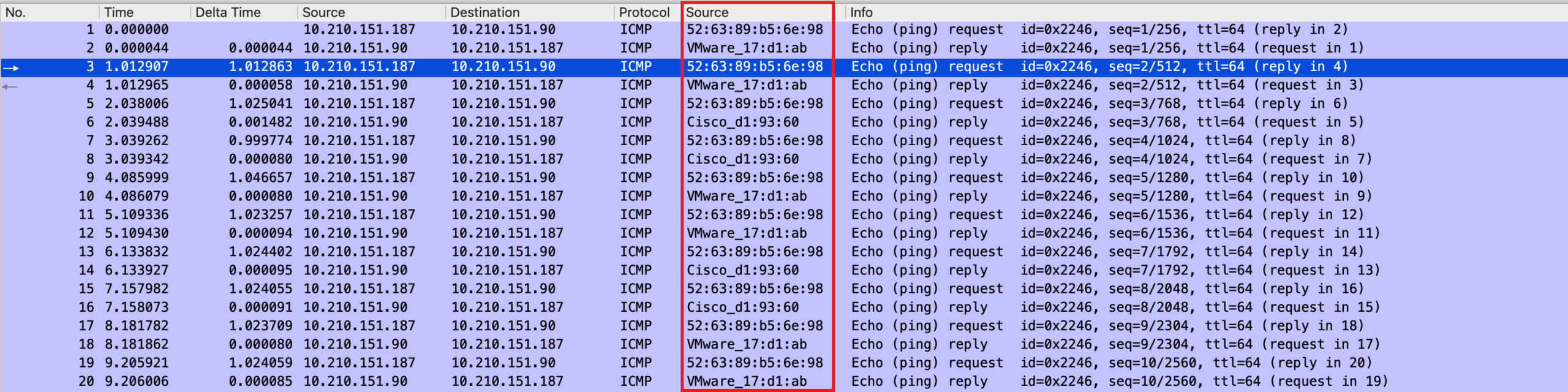
可以看到,我们发出去 3 个询问,却收到 6 个回复。说明每一个询问得到了 2 个答案。(其实,在诊断和验证这个问题的过程中,最快的方式就是用 arping 来测试一下,而不是抓包来分析。但是这里我们主要讨论抓包技术,所以拿来当作一个分析的案例。)
那么 Src 收到两个 ARP 应答,会以哪一个为准呢?答案是以先收到的为准。
|
1 2 |
$ ip nei show 10.210.151.90 dev h2-eth0 lladdr 5a:65:98:0c:82:02 REACHABLE |
但是 ARP 请求广播出去,这两个 ARP 应答哪一个先到是无法确定的,有的时候 5a:65:98:0c:82:02 先到,有的时候 c2:10:70:f2:ae:ab 先到,所以发送给 10.210.151.90 的包,有的时候发给了 MAC 地址为 5a:65:98:0c:82:02 的机器,有的时候发送给了 MAC 地址为 c2:10:70:f2:ae:ab 的机器。
补充一点,在实际的问题排查过程中,我们的 TCP 连接测试失败,最好的排查方法就是去对端进行抓包,看一下对端的机器是否收到了 SYN 包。以及在实际的现象中,客户端收到了 Connection refused ,通常意味着收到了 RST 报文(可能来自真实对端,也可能来自其他设备)。我们在对端抓包的过程中会发现即没有收到 SYN,也没有发出 RST,这说明包到别的地方去了。进而,我们可以发现字网内还有一个「李鬼」的问题。
那么,为什么 ping 的测试完全正常呢?
因为 ICMP 是无连接协议,,ping 的 ICMP 协议回复,是由 Kernel 负责的,所以无论 ICMP 包发送到哪一个机器上,由于它们都设置了这个 IP 地址,所以都可以做出回复。其实抓包中的回复是来自不同的机器,只不过 ping 不知道,只要是收到了回复,就认为一切正常。
最后一个问题,为什么会有 IP 重复的问题呢?
DHCP 可以用来动态分配 IP 地址给设备,但是一般只用于客户端,比如办公网、家用网络中的终端设备,这些设备一般作为连接的发起方,不需要 listen 一个固定的 IP 地址,IP 地址的动态变化对它们影响不大。但是在 IDC 的网络中,每一个服务器的软件都需要固定的 IP 地址,一般不用 DHCP 来动态分配,而是用中心化的 IPAM 系统1追踪 IP 地址的分配情况。如果里面记录的地址不正确,比如,一个地址已经在使用中了,但是并没有在 IPAM 记录,就造成 IP 地址重复的问题。
==抓包破案录==
这篇文章是抓包破案录系列文章(之前叫做《计算机网络实用技术》,后来改名了)中的一篇,这个系列正在连载中,我计划用这个系列的文章来分享一些网络抓包分析的实用技术。这些文章都是总结了我的工作经历中遇到的问题,经过精心构造和编写,每个文件附带抓包文件,通过实战来学习网络抓包与分析。
如果本文对您有帮助,欢迎扫博客右侧二维码打赏支持,正是订阅者的支持,让我公开写这个系列成为可能,感谢!
如果您正在阅读的是题目类的文章,这个目录内容正好用来隔离其他读者的评论。读完题目可以稍作暂停,进行思考,继续向下滑动,可能会被其他的读者剧透答案。
没有链接的目录还没有写完,敬请期待……
- 序章
- 抓包技术以及技巧
- 理解网络的分层模型
- 数据是如何路由的
- 网络问题排查的思路和技巧
- 不可以用路由器?(答案和解析)
- 网工闯了什么祸?(答案和解析,阅读加餐!)
- 重新认识 TCP 的握手和挥手(答案和解析)
- 3.5 秒初始延迟问题 (答案和解析)
- 网络断断续续…… (答案和解析)
- 延迟增加了多少?(答案和解析)
- 压测的时候 QPS 为什么上不去?(答案和解析)
- TCP 下载速度为什么这么慢?(答案和解析)
- 请求为什么超时了?(答案和解析)
- 0.01% 的概率超时问题 (答案和解析)
- 后记:学习网络的一点经验分享
与本博客的其他页面不同,本页面使用 署名-非商业性使用-禁止演绎 4.0 国际 协议。