Alertmanager 发送出来的告警是一条消息,一般我们会用 annotation 来说明发生什么事了。
但是 Grafana 发出来的,就会直接带上你的查询表达式当前的状况:
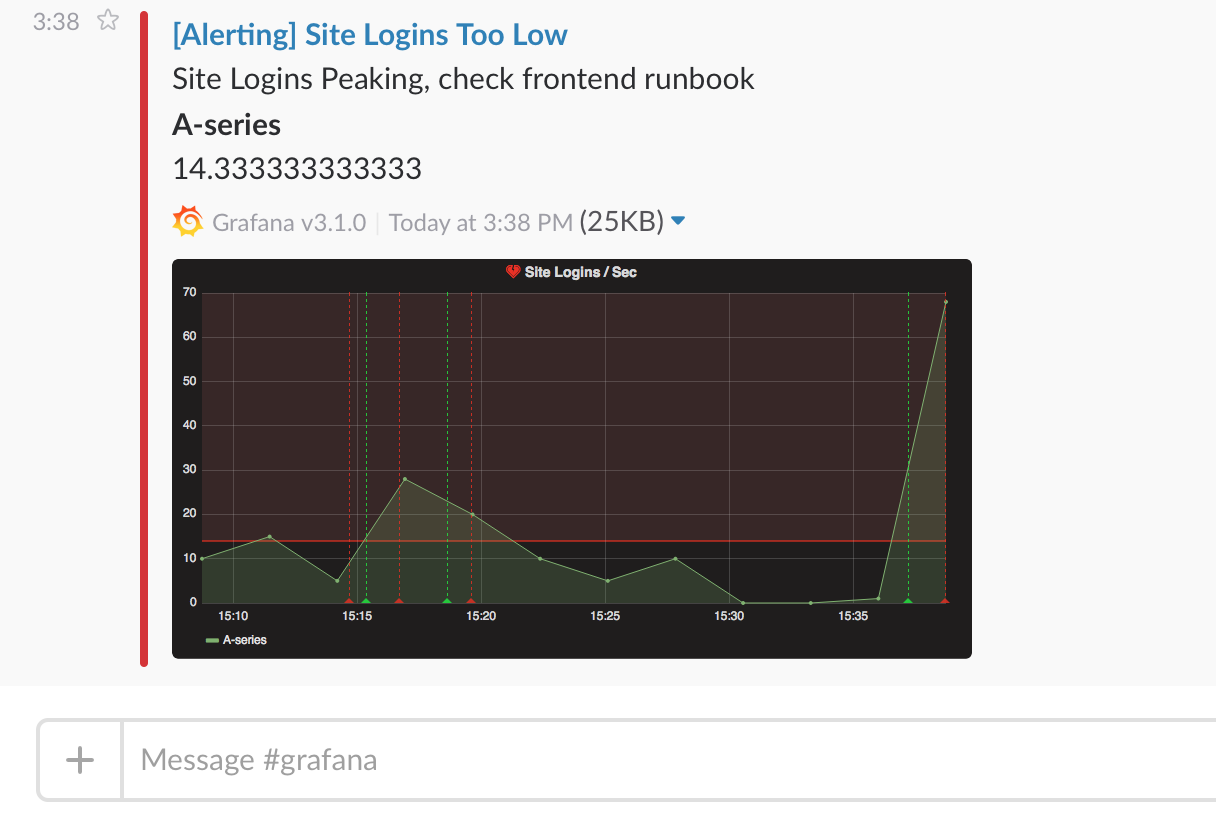
这个图是非常有用的,如果有图的话,基本上一看你就知道发生什么事情了,因为它可以告诉你一个 time series 图,是一个 Range 消息,如果没有图的话,就相当于你只能知道一个数据点的信息(Instant)。后面需要连接 VPN,打开对应的监控,去查看到底发生了什么。
但是我们依然没有选择用 Grafana 来做 Alert 系统,而是选择了 Alertmanager 来做。事实上,上面这个优点几乎是 Grafana 唯一的优点,在其他方面它都不如 Alertmanager,这个后面有时间再说吧。本文是想谈谈有什么可能让 Alertmanager 发出来消息的时候带上一个曲线图。
其实这件事情没有什么难度,只要在发出告警的带出一条渲染好的 URL 就可以了。唯一比较复杂的是,prometheus 对 alert 的逻辑是:如果一条查询的结果不是 null,那么就 fire,否则,说明一切正常。
比如 up == 0,正常情况下 up 值是 1,所以这条查询不会有结果。如果目标挂了,这么就成立了,这条查询就会有结果。
比如 rss_memory > 1G,正常情况下小于 1G,也不会有结果。但是如果超过了,查询就有结果了,就会 fire alerts。
所以如果你把 alert rules 的这条 expression 画出来的,就会长这样:
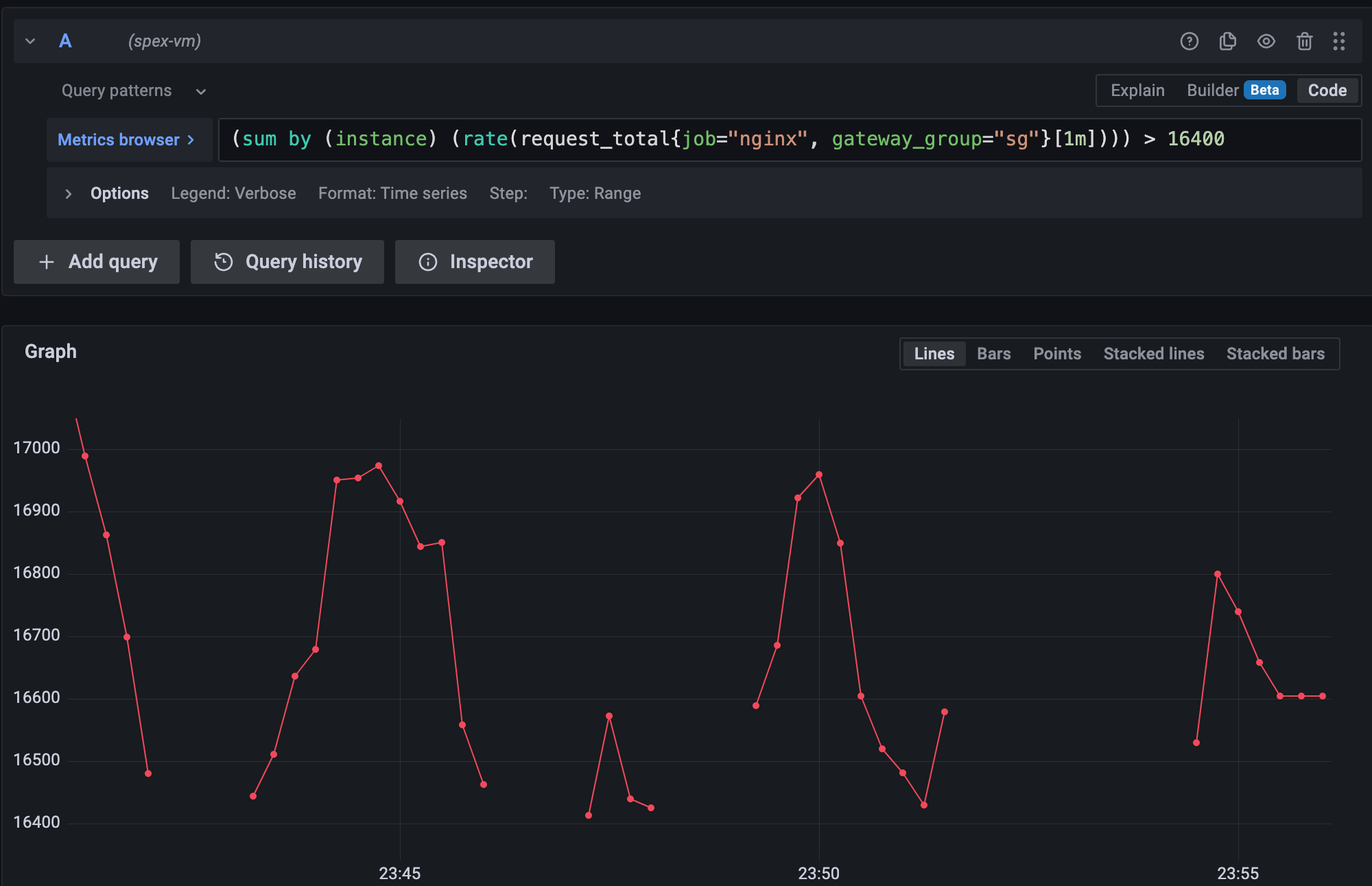
可以看到,触发 alerts 的时候就不是 null,threshold 以下的就都是 null 了。
一个解决方法是,我们可以将这个查询表达式拆开,分成作值和右值。分开画图。就可以看到像下面这样的效果:
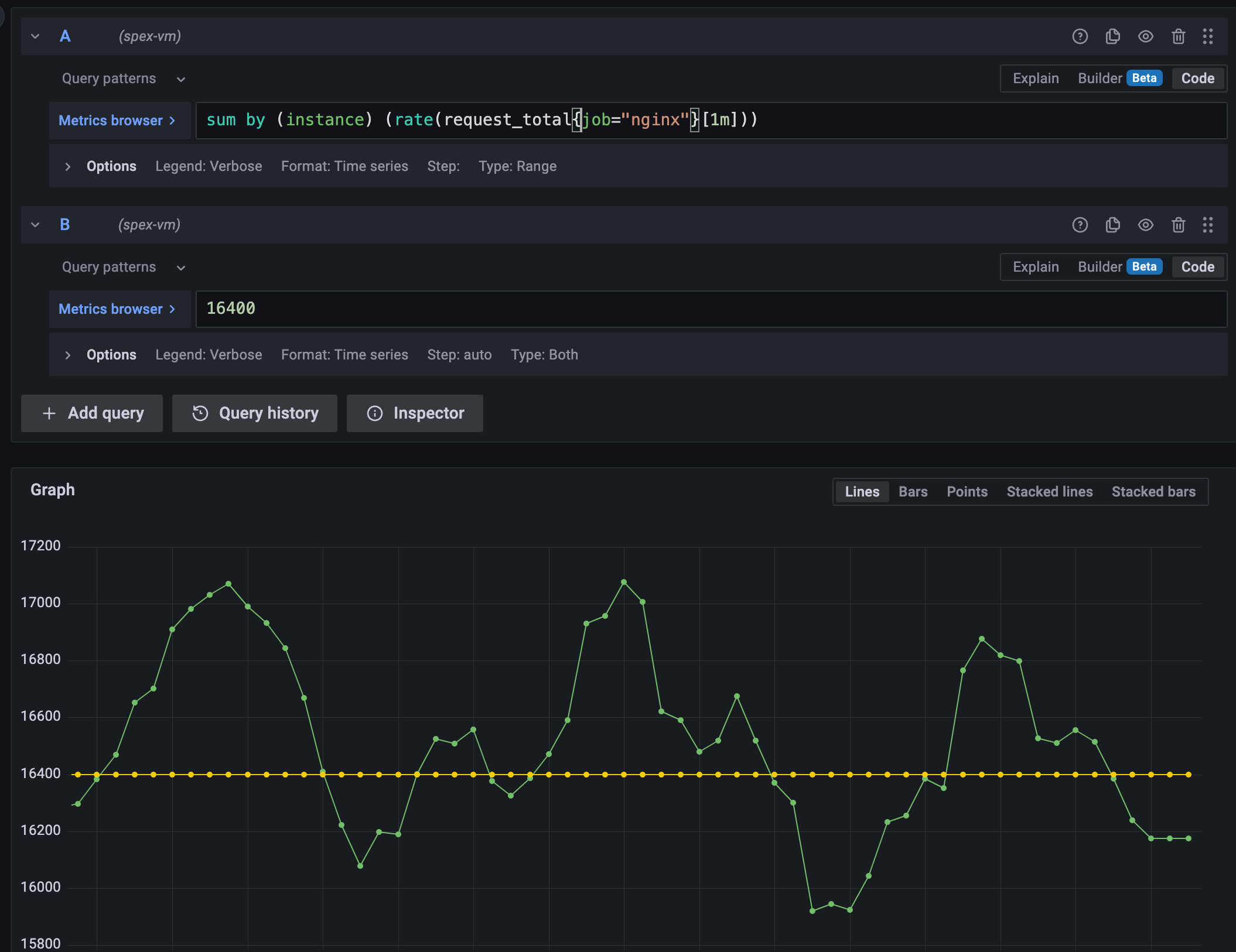
本以为会有现成的工具可以拆开 alert rules,将其拆成两个表达式。然后调查了一番,发现并没有这种东西。
那么 Grafana 是怎么做到的呢?很简单……Grafana 设置的 alert rules 的右值只能是一个固定的数字,必须按照固定的格式填入。
在 Prometheus 用户组发现一个哥们也有相同的问题,一个哥们回答说 Prometheus 的 go 库就支持这个功能,有一个 ParseExpr 函数,传入一个 string 的 PromQL 代码,传回一个 Expr 解析好的表达式。这哥们是 Promlens 的,这是一个付费的服务,可以解析和可视化 PromQL。
然后又找到了一些可以解析 PromQL 相关的库:
最后决定用 metricsql 来实现。唯一的缺点是这个库是 golang 写的(VictoriaMetrics 所有的产品都是用 golang 写的)。我的项目是基于 Python 的。
我决定用 golang 实现我需要的功能:传入一个 expression,然后传回 split 好的语法树。然后用 CGO 编译成一个 shared library,最后在 Python 中用 cffi 来调用。
核心的逻辑很简单,即使将 expression 用 metricsql.Parse 函数去处理,得到一个语法树,然后递归遍历一遍:
- 如果遇到逻辑操作符,比如 and, or, unless, 那么说明左边和右边依然是一个 expression,递归分析;
- 如果是比较操作符:==, >, < 等,那么它的左值和右值就直接拆开,用于画图,到此递归结束。有的时候会遇到表达式依然是比较的情况:
(a > 10) < 100,这种情况可以将 a > 10 看成是一条普通的线,直接返回即可,没有必要继续拆分;
为了方便测试和维护代码结构,go 写的核心的逻辑和 CGO 处理的部分分开。下面再写一个 CGO 函数,它的入口参数必须都是 import "C" 这个库提供的,将会用于 ABI。返回的参数也是。
编译方法如下:
go build -buildmode=c-shared -o libpypromql.so
这样就得到了一个 .so 文件和 header 文件。
下面就是用 Python 去调用这个 so 文件了。直接用 cffi 的接口就可以,这个很简单,基本上就是描述一下这个 so 的 ABI,然后用 cffi 去调用,解析结构。需要特别注意的是,golang 的 gc 不会释放它 return 的 C.CString,这部分必须手动释放:
|
|
def split_binary_op(code: str): """ split PromQL/MetricsQL alert rules into multiple expressions """ result = lib.SplitBinaryOp(code.encode()) json_result = ffi.string(result.r0).decode() err = ffi.string(result.r1).decode() lib.FreeString(result.r0) lib.FreeString(result.r1) if err: raise PromQLException(err) return json.loads(json_result) |
最后一步,因为是用 Poetry 打包的 Python package,所以还需要写一个 build.py 告诉 poetry 怎么 build whl。
还写了一个命令行的工具,可以从命令行拆分 expression,效果如下:
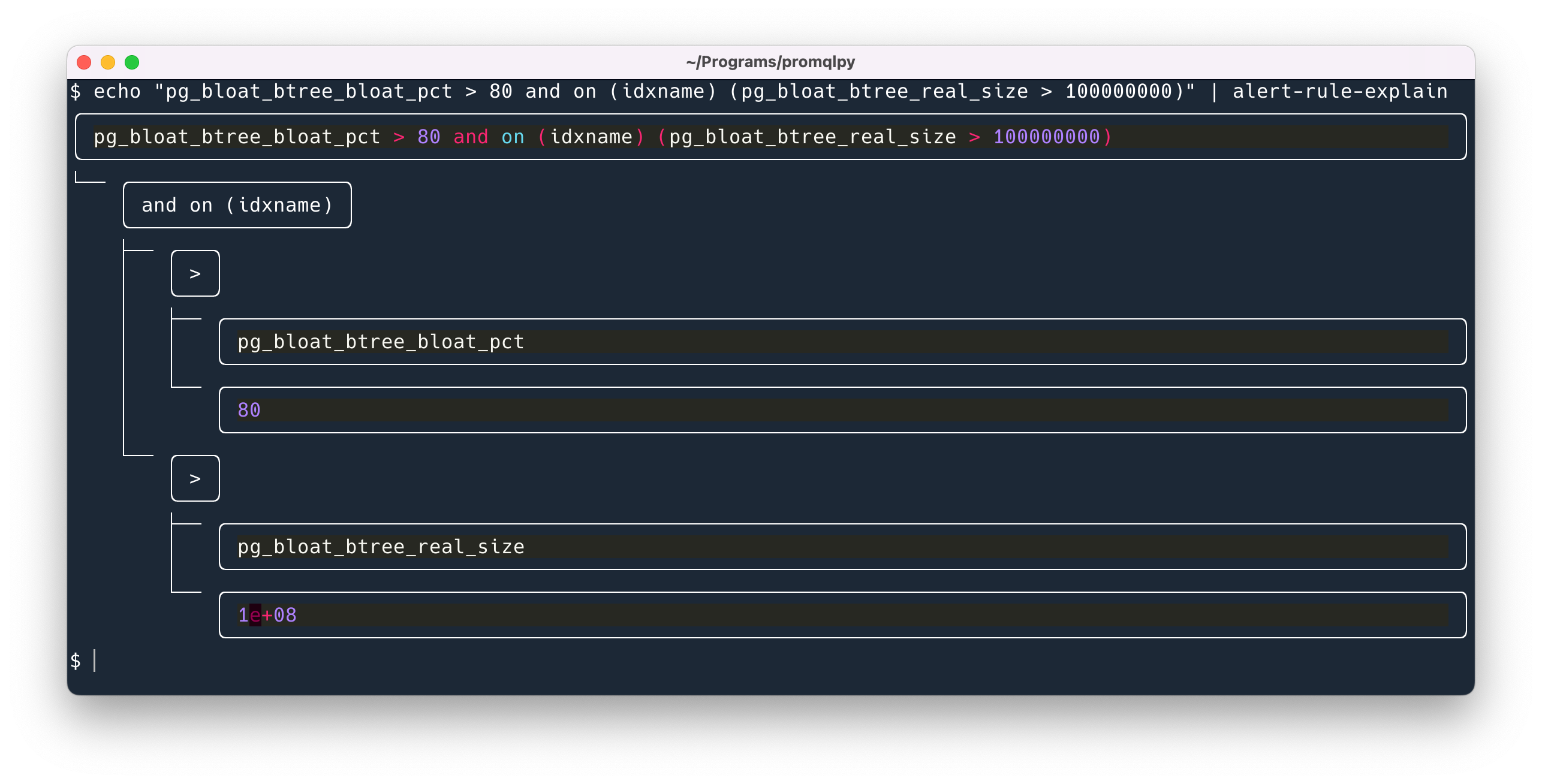
为了测试解析结果的正确性,我把 awesome-prometheus-alerts 项目所有的 alerts 抓下来了,用来生成了 400 多个单元测试。
项目的地址是:https://github.com/laixintao/promqlpy